Unicode in C++
Думаю, при помощи нормальных кросс-платформенных тулкитов вроде Qt и Gtk, которые уже внутри себя сами обрабатывают этот самый Юникод.
преобразование из wchar_t в байты внутри стрима идет наитупейшим образом.Программист Вася вручную переписывает STL.
Собственно вопрос: как нормальные люди обращаются с юникодом в кроссплатформенных приложениях написанных на С++?
Для начало нужно понять, с какой кодировкой ты работает, что есть юникод. Обычно сейчас называют юникодом кодировку UTF-8. приемущества — она однобайтная, недостатки — разные символы могут имать разную длинну.
Далее, нуджно понимать, что
в кроссплатформенных приложениях написанных на С++
меньше всего нужно думать о
msvcПотому что для винды придется писать отдельно, она не понимает utf-8 просто так.
Резюме:
1) определись, какое приложение ты пишешь — консольное, графическое или демон (службу)?
1а) в случае консоли нужно писать адаптер для вывода в консоль из utf-8
1б) в графическом — что ты будешь использовать GTK/Qt, что под виндой? что под Маком?
1в) демон пишет всё только в логи, поэтому проблем не будет.
Короче, уточняй задачу, и сразу совет — используй cmake. Он нормально работает с msvc, и всеми компиляторами.
Хм. Пожалуй изначальный вопрос стоит переформулировать - как вообще нормальные люди пишут кроссплатформенные приложения на С++?
Какие приложения? Примеры?
А вообще, судя по вопросам, ты нихуя не напишешь, лучше не берись, иди поучись писать у кого-нить.

Хм. Пожалуй изначальный вопрос стоит переформулировать - как вообще нормальные люди пишут кроссплатформенные приложения на С++?Без юникода пишут, пока нормально получается
Без русского вывода, правда)
Обычно сейчас называют юникодом кодировку UTF-8. приемущества — она однобайтная, недостатки — разные символы могут имать разную длинну.дык однобайтная или разной длины?
Для ascii символов она однобайтовая, для остальных — как получится.
Ее главная фича — обратная совместимость с кучей Cишного хлама, афаик
Ее главная фича — обратная совместимость с кучей Cишного хлама, афаик
а ты зачем отвечаешь?
я же не тебя подкалывал
я же не тебя подкалывал
версия msvc какая?
Для начало нужно понять, с какой кодировкой ты работает, что есть юникод. Обычно сейчас называют юникодом кодировку UTF-8. приемущества — она однобайтная, недостатки — разные символы могут имать разную длинну.Работаю с кучей кодировок, причем не обязательно юникодных. Минимальный необходимый набор - cp1251, UTF8, UTF16.
1) определись, какое приложение ты пишешь — консольное, графическое или демон (службу)?Консольное, ага.
1а) в случае консоли нужно писать адаптер для вывода в консоль из utf-8
Но я честно говоря не вижу особых преимуществ использования UTF8 как внутренней кодировки программы. Про адаптер - ну я уже написал его для вывода UTF16, легче мне от этого не стало - ощущение черезжопности не прошло ).
Какие приложения? Примеры?Самый тупой пример: консольный парсер HTML, который в HTML'ке ищет нечто, и выдает на stdout. Отсюда и необходимость работы с кодировками.
А вообще, судя по вопросам, ты нихуя не напишешь, лучше не берись, иди поучись писать у кого-нить.Хы, да я уже все написал, а теперь вот встал вопрос о прикручивании поддержки различных кодировок и вывода в UTF8/16.
http://icu-project.org/index.htmlХм, это чудо я уже ботал. IO API там противный, но конечно лучше чем ничего.
В общем, я хотел получить ответ вроде "ну нормальные люди юзают либы A, B и C и не парятся - их код компилится и одинаково работает (почти) везде". Для тяжеловесных GUI приложений ответ я получил. С легковесными видимо придется париться.
версия msvc какая?8.0
stlport кстати не помогает? или другие реализации stl-я?
Но я честно говоря не вижу особых преимуществ использования UTF8 как внутренней кодировки программы.Увидь. Подумай, почему люди используют эту кодировку, например, в интернете везде.
Самый тупой пример: консольный парсер HTML, который в HTML'ке ищет нечто, и выдает на stdout.Зачем там начинать с msvc?
Кстати, если производительность не важна — используй Mozilla для парсинга. Она выдает 16-битный юникод, на входе — все че хочешь. Более того, она имеет весь арсенал для работы с этими строками, подобие STL.
Но парсить больше 50 страниц в секунду ты её не заставишь.

Её обычно используют для передачи данных, а не для внутреннего хранения. Для внутреннего utf-16.
Потому что для винды придется писать отдельно, она не понимает utf-8 просто так.ХЗ насчёт utf-8, но разве ucs-2 она не понимает "просто так"? А что тогда она "просто так" понимает?
wcout.imbue(locale("rus_rus";
wcout << L"хфй" << endl;
работает под MSVC 7.1 нормально.
rus_rusА если хочется не "рус_рус", а часть символов - кирриллица, часть - западноевропейские, а часть - вообще иероглифы? Юникод вообще-то как раз для этого разрабатывался.
Ну это не ко мне, а ко врачу, который тебе лоботомию делал. Консоль в винде не может отображать символы всех локалей одновременно.
Консоль в винде не может отображать символы всех локалей одновременноЭто кто тебе такое сказал?
Если есть доказательства обратного, то о существовании оных нужно заявить тому, кто этот топик вообще открывал.
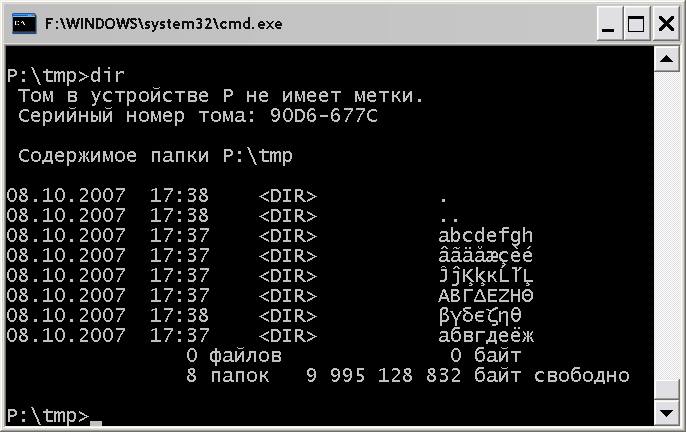
Что я делаю не так?
Меняешь дефолтный шрифт, хуле.
Даже если и так, что ты узнать-то хотело?
Даже если и так, что ты узнать-то хотело?
Я так понимаю, что проблема в том, что код, который ты будешь компилировать, получается не юникодный, поэтому запись L"[лол]" интерпретирует 'л' неправильно. Если избегать нелатинских строковых констант в коде, то всё должно работать.
Меняешь дефолтный шрифт, хуле.То есть, ты признаёшь, что это:
Консоль в винде не может отображать символы всех локалей одновременно- наглая ложь?
Потому что консоль в винде может отображать символы всех локалей одновременно, проблема в том, что в некоторых случаях дефолтный шрифт консоли - "точечные шрифты", а не юникодные Lucida Console или Consolas.
Я так понимаю, что проблема в том, что код, который ты будешь компилировать, получается не юникодный, поэтому запись L"[лол]" интерпретирует 'л' неправильно. Если избегать нелатинских строковых констант в коде, то всё должно работать.Если вбивать строковые константы циферками, или даже преобразовывать в рантайме из интов в массив wchar_t - получаю то же самое. Баг глобальный, и не у меня. Вечером попробую stlport - сейчас работаю с реализацией stl, что идет в комплекте со студией.
Консоль в винде не может отображать символы всех локалей одновременно.Какое вообще отношение к обсуждаемому вопросу имеет виндовая консоль? Не все ли равно, что она отображает, а что нет - все равно через пайп все можно считать в нужном для себя виде.
Н-да, с stlport все еще хуже. Мне его вообще не удалось заставить выводить UTF16 в wfstream. Ну и на консоль ес-но тоже ничего не выводится. Жесть короче.
Я так понимаю, что проблема в том, что код, который ты будешь компилировать, получается не юникодный, поэтому запись L"[лол]" интерпретирует 'л' неправильно. Если избегать нелатинских строковых констант в коде, то всё должно работать.Кстати, тогда к тебе вопрос - если у меня исходники в юникоде (UTF-8 что будет записано в строку в этом случае:
const char* str = "абра-кадабра"?
Символы будут по прежнему занимать один байт? Строка будет преобразована в однобайтную кодировку? Что произойдет, в общем?
23 байта будет записано.
Йопт. А если я потом в таком же виде выведу это на консоль, понимающую UTF-8, оно все нормально покажется по-русски?
именно!
хотя там от консоли наверное зависит. вот в убунте на работе у меня консоль не показывает знаки ударения над символами.
ну и вообще управляющие символы игнорит. почему — хз, не вникал. если кто знает, где происходит игнор — скажите.
ну и вообще управляющие символы игнорит. почему — хз, не вникал. если кто знает, где происходит игнор — скажите.
Кстати, тогда к тебе вопрос - если у меня исходники в юникоде (UTF-8 что будет записано в строку в этом случае:зависит от компилятора. и от того, можно ли объяснить в какой кодировке приходят исходные файлы, и в какой кодировке должны формироваться строки в exe.
const char* str = "абра-кадабра"?
зависит от компилятора. и от того, можно ли объяснить в какой кодировке приходят исходные файлы, и в какой кодировке должны формироваться строки в exe.каким образом это зависит от компилятора, что значит "нельзя объяснить в какой кодировке приходят исходные файлы" и что такое кодировка строк в exe?

Мож шибко умный компилятор от винды поймет, что это UTF-8, и в строку все как CP1251 загонит?
> что значит "нельзя объяснить в какой кодировке приходят исходные файлы"
в общем случае, у тебя один cpp-ишник может быть в win-кодировке, другой - в utf-8, третий - в utf-16, четвертый - в koi8. Соответственно, компилятор может такие исходные файлы в разной кодировке поддерживать, а может и не поддерживать.
> что такое кодировка строк в exe
например, русский язык в однобайтной кодировке - может кодироваться в Dos-кодировке, может в win, а может и в nix-овой(koi8)
или проще говоря - буква 'ф' в одном случае будет записана как один байт(число а в другом будет записана как другой байт(другое число).
в общем случае, у тебя один cpp-ишник может быть в win-кодировке, другой - в utf-8, третий - в utf-16, четвертый - в koi8. Соответственно, компилятор может такие исходные файлы в разной кодировке поддерживать, а может и не поддерживать.
> что такое кодировка строк в exe
например, русский язык в однобайтной кодировке - может кодироваться в Dos-кодировке, может в win, а может и в nix-овой(koi8)
или проще говоря - буква 'ф' в одном случае будет записана как один байт(число а в другом будет записана как другой байт(другое число).
не, ну насколько я понимаю, если строковая константа записана в исходнике с какой-то кодировкой, то это однозначно определяет последовательность байт, которая ей соответствует, и писать именно эту последовательность байт в скомпилированный код — имхо вполне здравая идея. то есть компилятору должно быть пофиг на разнообразие кодировок в проекте. важно только понимать каждую из них в отдельности.
из второго твоего абзаца выходит, что некие особо умные компиляторы могут наплевать на кодировку исходника (т.е. кодировку описываемой строковой константы) и перекодировать его в свою любимую кодировку.
мне интересно, чем нужно руководствоваться, чтобы такое странное поведение оказалось оправданным?
из второго твоего абзаца выходит, что некие особо умные компиляторы могут наплевать на кодировку исходника (т.е. кодировку описываемой строковой константы) и перекодировать его в свою любимую кодировку.
мне интересно, чем нужно руководствоваться, чтобы такое странное поведение оказалось оправданным?
не, ну насколько я понимаю, если строковая константа записана в исходнике с какой-то кодировкой, то это однозначно определяет последовательность байт, которая ей соответствует, и писать именно эту последовательность байт в скомпилированный код — имхо вполне здравая идеяЗависит от языка.
В XML, например, это, можно сказать, что и не так.
Это ты с той точки зрения смотришь, что ты в среде разработки работаешь, а не сам подсовываешь компилятору файлы.
какая разница, кто подсовывает компилятору файл — я или среда разработки?
мне кажется странным, что компилятор пытается что-то перекодировать, если я его об этом не просил.
мне кажется странным, что компилятор пытается что-то перекодировать, если я его об этом не просил.
Я кстати нашел солюшн.
Под винду:
Юзаем WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE)...) для вывода на консоль (если вывод программы не перенаправлен в пайп / файл WriteFile(GetStdHandle(STD_OUTPUT_HANDLE)...) - если перенаправлен. Что юзать определяем через isatty (по идее должна быть такая же ф-я из WinAPI, но я особо не искал). В итоге на консоли отображаются юникодные символы, а при перенаправлении вывод в файл идет в UTF16.
Под никсами:
Не паримся с wchar_t и юзаем char, считая что весь io идет в прозрачном UTF8. То есть можно спокойно юзать стримы или fwrite и не заморачиваться с isatty.
Для перекодировки используем MultiByteToWideChar / WideCharToMultiByte под виндой и iconv под никсами. Обертываем все это в удобоваримый интерфейс, и счастье наступает.
Итог: бесплатного решения не через жопу нет.
Под винду:
Юзаем WriteConsole(GetStdHandle(STD_OUTPUT_HANDLE)...) для вывода на консоль (если вывод программы не перенаправлен в пайп / файл WriteFile(GetStdHandle(STD_OUTPUT_HANDLE)...) - если перенаправлен. Что юзать определяем через isatty (по идее должна быть такая же ф-я из WinAPI, но я особо не искал). В итоге на консоли отображаются юникодные символы, а при перенаправлении вывод в файл идет в UTF16.
Под никсами:
Не паримся с wchar_t и юзаем char, считая что весь io идет в прозрачном UTF8. То есть можно спокойно юзать стримы или fwrite и не заморачиваться с isatty.
Для перекодировки используем MultiByteToWideChar / WideCharToMultiByte под виндой и iconv под никсами. Обертываем все это в удобоваримый интерфейс, и счастье наступает.
Итог: бесплатного решения не через жопу нет.
в каком смысле не так и что такое скомпилированный XML-код?
Да не пытается он перекодировать, а предупреждает(или даже валится что в некоторых строках кодировка не совпадает с кодировкой файла.
А то будет половина меню в одной кодировке, половина в другой
А то будет половина меню в одной кодировке, половина в другой
у меня вопрос не в том, что делает компилятор, а в том, почему он так делает.
это же странно! =)
я в файле задал константу (последовательность байт а он ее меняет.
ему что, делать нефиг?
это же странно! =)
я в файле задал константу (последовательность байт а он ее меняет.
ему что, делать нефиг?
ну или не меняет, а говорит: "чувак, фиговая какая-то у тебя константа. пожалуй, я свалюсь (выдам предупреждение)."
В том смысле, что ты считываешь xml-файл, в котором все тексты в cp1251, и в метаданных сказано, что это cp1251 - и получаешь тексты во внутренней кодировке своей программы (например, utf-8 вообще не думая о кодировках.
Да задал ты константу в KOI8, а компилятору не сказал, что исходник в кодировке KOI8, и он по умолчанию в win ее и скомпилил. Откуда ему знать, что у тебя другое умолчание?
Да задал ты константу в KOI8, а компилятору не сказал, что исходник в кодировке KOI8, и он по умолчанию в win ее и скомпилил.А константа - это набор символов или набор байт?
Потому что у байт кодировок не бывает.
у меня умолчание очень простое: компилятор ничего не меняет.
в исходном примере файл был в UTF-8, но последовательность байт в бинарнике почему-то зависела от компилятора.
объясни мне плз на пальцах, как мог получиться такой эффект? для меня это нечто сверхъестественное.
вот была буква "а", d0b0 в UTF-8. компилятор "по умолчанию" компилит ее в win. что будет в бинарнике?
в исходном примере файл был в UTF-8, но последовательность байт в бинарнике почему-то зависела от компилятора.
объясни мне плз на пальцах, как мог получиться такой эффект? для меня это нечто сверхъестественное.
вот была буква "а", d0b0 в UTF-8. компилятор "по умолчанию" компилит ее в win. что будет в бинарнике?
Как ты думаешь сам, мы обсуждаем сейчас то у чего есть кодировка или то у чего нет кодировки?
А UTF8 вообще соберется, если компилятор будет про него думать что он win ?
А хер знает.
У C++ есть кодировка?
У C++ есть кодировка?
А в чём проблема?
Наоборот - не соберётся.
А в cp1251 всё допустимо.
Наоборот - не соберётся.
А в cp1251 всё допустимо.
я пока не понял даже, что такое кодировка откомпилированного кода,
а ты спрашиваешь о кодировке языка программирования.
а ты спрашиваешь о кодировке языка программирования.
у с++ - нет, у исходников есть.
Вообще, по идее, ты должен быть прав - в файле записана последовательность байтов, которая должна быть загнана в строку независимо от того, в какой кодировке среда отображает твой файл.
Но если взгянуть на проблему с другой стороны - если у тебя разные исходные файлы в разных кодировках (о чем уже то среда тебе твои русские символы покажет везде нормально, а вот скомпилены будут разные строки.
Ну, для справки - после того, как я конвертил коды в UTF-8, у меня стал валиться тест на открытия файла с русским именем, потому что теперь конструтору fstream передается строка в другой кодировке. Это в msvc, в линуксе я не собирал еще.
Какой вариант тебя больше устроит?) Я думаю, что это все полностью зависит от компилятора или от среды, или от компилятора+среда.
Но если взгянуть на проблему с другой стороны - если у тебя разные исходные файлы в разных кодировках (о чем уже то среда тебе твои русские символы покажет везде нормально, а вот скомпилены будут разные строки.
Ну, для справки - после того, как я конвертил коды в UTF-8, у меня стал валиться тест на открытия файла с русским именем, потому что теперь конструтору fstream передается строка в другой кодировке. Это в msvc, в линуксе я не собирал еще.
Какой вариант тебя больше устроит?
) Я думаю, что это все полностью зависит от компилятора или от среды, или от компилятора+среда.В том смысле, что ты считываешь xml-файл, в котором все тексты в cp1251, и в метаданных сказано, что это cp1251 - и получаешь тексты во внутренней кодировке своей программы (например, utf-8 вообще не думая о кодировках.это что за волшебство? опиши плз процесс считывания файла.
и заодно то, как с этим процессом связан язык программирования XML. =)
Вообще, по идее, ты должен быть прав - в файле записана последовательность байтов, которая должна быть загнана в строку независимо от того, в какой кодировке среда отображает твой файл.именно!

Но если взгянуть на проблему с другой стороны - если у тебя разные исходные файлы в разных кодировках (о чем уже писал то среда тебе твои русские символы покажет везде нормально, а вот скомпилены будут разные строки.жесть!
Ну, для справки - после того, как я конвертил коды в UTF-8, у меня стал валиться тест на открытия файла с русским именем, потому что теперь конструтору fstream передается строка в другой кодировке. Это в msvc, в линуксе я не собирал еще.
Я думаю, что это все полностью зависит от компилятора или от среды, или от компилятора+среда.жесть!
короче, я понял всё. спасибо участнегам за дискуссию.
опиши плз процесс считывания файлаНу ты суёшь парсеру xml, он его парсит и выдаёт тебе структуру в твоей рабочей кодировке, вне зависимости от того, какая там кодировка в самом xml использовалась.
Для перекодировки используем MultiByteToWideChar / WideCharToMultiByte под виндой и iconv под никсами.Обертываем все это в удобоваримый интерфейс, и счастье наступает.Что-то мешает использовать wcstombs и там, и там?
парсер != компилятор.
не совсем понятно выразился наверное.
и парсер, и компилятор, по хорошему должны тебе результат парсинга отдать, а перекодировать
в нужный тебе формат для обработки (руководствуясь информацией о кодировке xml-файла) — твоя задача.
твой парсер xml умеет выполнять некоторые твои задачи за тебя.
и парсер, и компилятор, по хорошему должны тебе результат парсинга отдать, а перекодировать
в нужный тебе формат для обработки (руководствуясь информацией о кодировке xml-файла) — твоя задача.
твой парсер xml умеет выполнять некоторые твои задачи за тебя.
Ну объясни тогда, что такое парсер, что такое компилятор, и что играет роль парсера, а что - компилятора в случае xml-файлов
на самом деле ==, конечно. =)
аналог с компилятором: вывод на консоль строковой константы, зашитой в код.
ты должен знать в какой кодировке выводишь и сказать об этом консоли, чтобы она поняла, как это читать.
если ты в какой-нибудь переменной будешь хранить кодировку вывода, задаваемую из, например, конфига,
а компилятор все твои строки в разных кодировках сконвертит в одну, случится страшное.
твой парсер перекодирует xml потому, что ему об этом сказали. так же, как и консоли в примере выше.
аналог с компилятором: вывод на консоль строковой константы, зашитой в код.
ты должен знать в какой кодировке выводишь и сказать об этом консоли, чтобы она поняла, как это читать.
если ты в какой-нибудь переменной будешь хранить кодировку вывода, задаваемую из, например, конфига,
а компилятор все твои строки в разных кодировках сконвертит в одну, случится страшное.
твой парсер перекодирует xml потому, что ему об этом сказали. так же, как и консоли в примере выше.
Что-то мешает использовать wcstombs и там, и там?Есть предположение, что смена глобальной локали, на основе которой wcstombs конвертирует, будет давать тормоза и проблемы в мультитредовых приложениях.
Под виндой еще есть wcstombs_l, которому локаль передается непосредственно, но man(3) про эту ф-ю не знает, так что не факт, что она будет везде доступна. Я правда особо не тестил, только в man глянул.
Есть предположение, что смена глобальной локали, на основе которой wcstombs конвертирует, будет давать тормоза и проблемы в мультитредовых приложениях.Есть предположение, что кривизна рук передается непосредственно в мозг.
не, ну насколько я понимаю, если строковая константа записана в исходнике с какой-то кодировкой, то это однозначно определяет последовательность байт, которая ей соответствует, и писать именно эту последовательность байт в скомпилированный код — имхо вполне здравая идея.это все клево, но как быть если у тебя в исходнике двухбайтная кодировка, а в exe-шнике однобайтная, или наоборот?
Есть предположение, что кривизна рук передается непосредственно в мозг.Ты наверно тут самый умный, да?
Давай, дерзай, напиши ф-ю конвертации из произвольной кодировки в utf16 с использованием mbstowcs, которая будет нормально работать в мультитредовом приложении. Ты наверно собрался перед каждым вызовом mbstowcs лочить мутекс, а затем вызывать setlocale - mbstowcs - setlocale? Такой подход убивает всю пользу от мультитредовости, плюс небезопасен, т.к. пользователю ф-ии надо знать, что отныне ему самому нельзя вызывать setlocale.
The function _configthreadlocale is used to control whether setlocale affects the locale of all threads in a program or only the locale of the calling thread.
как быть если у тебя в исходнике двухбайтная кодировка, а в exe-шнике однобайтная, или наоборотА нет кодировок, строки - это последовательности байт.
Бля, не тупи!
Пусть у тебя есть две функция
int checkPass (const char * pass)
{
return strcmp(pass, "пассворд");
}
доставшаяся в наследство от старого мудрого хакера и лежащая в DOS-кодировке. И новая функция, точно такая же, но уже в файлеге, закодированном win1251. Когда ты открываешь оба файлега в ИДЕ, она понимает, о какой кодировке идёт речь и отображает их одинаково (допустим). Ты их компилишь и... И? У тебя получаются две разные функции? Хотя визуально они одинаковы? Или как?
Ты, конечно, можешь сказать, что это самоуправство со стороны IDE. А что делать с тремя файлегами в utf8, unicode (то есть UCS-2, насколько я понимаю) и utf16 (ну там, допустим, ещё иероглифы какие-нибудь есть кроме русской записи, которые как-нибудь влияют)?
Вот и получается, что вообще говоря компилятору нужно быть довольно-таки умным и самостоятельно (однако взаимодействуя со средой) периодически преобразовывать кодировки. Например, если ты пишешь
wchar * s = TEXT("пассворд");
то компилятор должен вне зависимости от кодировки файла создать строковую константу со словом "пассворд" в UCS-2.
Пусть у тебя есть две функция
int checkPass (const char * pass)
{
return strcmp(pass, "пассворд");
}
доставшаяся в наследство от старого мудрого хакера и лежащая в DOS-кодировке. И новая функция, точно такая же, но уже в файлеге, закодированном win1251. Когда ты открываешь оба файлега в ИДЕ, она понимает, о какой кодировке идёт речь и отображает их одинаково (допустим). Ты их компилишь и... И? У тебя получаются две разные функции? Хотя визуально они одинаковы? Или как?
Ты, конечно, можешь сказать, что это самоуправство со стороны IDE. А что делать с тремя файлегами в utf8, unicode (то есть UCS-2, насколько я понимаю) и utf16 (ну там, допустим, ещё иероглифы какие-нибудь есть кроме русской записи, которые как-нибудь влияют)?
Вот и получается, что вообще говоря компилятору нужно быть довольно-таки умным и самостоятельно (однако взаимодействуя со средой) периодически преобразовывать кодировки. Например, если ты пишешь
wchar * s = TEXT("пассворд");
то компилятор должен вне зависимости от кодировки файла создать строковую константу со словом "пассворд" в UCS-2.
Ты, конечно, можешь сказать, что это самоуправство со стороны IDE.Я так и скажу.
А что делать с тремя файлегами в utf8, unicode (то есть UCS-2, насколько я понимаю) и utf16Пытаться отобразить их в той кодировке, которая в настройках.
Для языка программирования, имхо - лучший вариант. А у XML кодировка определяется не каким-то непонятным образом, а очень даже реальным заголовком.
это все клево, но как быть если у тебя в исходнике двухбайтная кодировка, а в exe-шнике однобайтная, или наоборот?записать в экзешник (количество символов * 2) байт? =)
я просто все еще не понимаю, что такое кодировка exe-шника.
в начальных условиях уже есть какой-то exe-шник, который собирали из однобайтных исходников? или как?
>The function _configthreadlocale is used to control whether setlocale affects the locale of all threads in a program or only the locale of the calling thread.
Это все конечно замечательно, но эта ф-я есть только под виндой (
Это все конечно замечательно, но эта ф-я есть только под виндой (
записать в экзешник (количество символов * 2) байт? =)какой символ тогда будет записан в переменную ch?
char ch = "Вася"[0]
так зачем придумали писать букву L перед строковой константной?
hint:
это появилось - когда исходники обычно были в однобайтной кодировке, а exe-шники понадобились с строковыми двухбайтными константами
какой символ тогда будет записан в переменную ch?если исходник в UTF-8, то 00.
char ch = "Вася"[0]
так зачем придумали писать букву L перед строковой константной?я не догадаюсь всё равно, потому что у меня в голове эта ересь не укладывается! =)
hint:
это появилось - когда исходники обычно были в однобайтной кодировке, а exe-шники понадобились с строковыми двухбайтными константами
рискну предположить, что им лень было сконвертить исходник, но очень хотелось придумать новую крутую букву. =)
какой символ тогда будет записан в переменную ch?Если считать, что char - байт, а "Вася" - последовательность байт, то первый байт "Вася" в таком виде, в каком оно хранится в исходниках.
char ch = "Вася"[0]
> если исходник в UTF-8, то 00.
и что это за символ? речь идет о том, что хотелось получить именно символ, а не байт.
и как с таким подходом - хотя бы написать программу, которая будет из константной строки выбирать только цифры?
и что это за символ? речь идет о том, что хотелось получить именно символ, а не байт.
и как с таким подходом - хотя бы написать программу, которая будет из константной строки выбирать только цифры?
цифры — это ж ASCII.
const char *str = "абра-кадабра 666";
for (; *str; ++str) if ('0' <= *str && *str <= '9') // ...
если надо искать не ASCII, можно написать многобайтный strchr. не вижу проблемы.
при считывании с произвольного устройства — конвертить во внутреннюю кодировку (хоть многобайтную, strchr-то написали).
const char *str = "абра-кадабра 666";
for (; *str; ++str) if ('0' <= *str && *str <= '9') // ...
если надо искать не ASCII, можно написать многобайтный strchr. не вижу проблемы.
при считывании с произвольного устройства — конвертить во внутреннюю кодировку (хоть многобайтную, strchr-то написали).
цифры — это ж ASCII.Вообще-то, цифра в какой-то кодировке может записываться не только не своим ascii-кодом, но и вообще не содержать в этой записи ascii-код.
Я уж не говорю про то, что, если мы увидели байт с кодом, как у какой-то цифры в ascii - это необязательно эта цифра (см.UCS-2)
UCS-2 — это вообще жесть. =)
btw, мой второй абзац эту проблему решает.
btw, мой второй абзац эту проблему решает.
> цифры — это ж ASCII.
тебе кто это сказал?
если строка была двухбайтная, то этот код обработает ровно одну цифру, потому что код 6 будет 0x36 0x00, а 0x00 - это конец строки
тебе кто это сказал?
const char *str = "абра-кадабра 666";
for (; *str; ++str) if ('0' <= *str && *str <= '9') // ...
если строка была двухбайтная, то этот код обработает ровно одну цифру, потому что код 6 будет 0x36 0x00, а 0x00 - это конец строки
for (; *str; ++str)А слона-то я и не заметил...
В си ведь вроде были какие-то костыли для строк, содержащих нулевые байты?
если строка была двухбайтная, то этот код обработает ровно одну цифру,а что это за страшная кодировка, в которой так?
потому что код 6 будет 0x36 0x00, а 0x00 - это конец строки
UCS2 LE?
ну коли так, понятно, зачем может быть нужен многобайтный char.
спасибо тебе и DG за разъяснения. =)
спасибо тебе и DG за разъяснения. =)
moo:~$ heump test
0000000 0a36
0000002
moo:~/subver/endeavour$ iconv -f utf8 -t utf16 test > test2
moo:~/subver/endeavour$ iconv -f utf8 -t ucs2 test > test3
moo:~/subver/endeavour$ heump test2
0000000 feff 0036 000a
0000006
moo:~/subver/endeavour$ heump test3
0000000 0036 000a
0000004
moo:~/subver/endeavour$ cat test
6
круто, да. =)
Оставить комментарий
tima56
Собственно вопрос: как нормальные люди обращаются с юникодом в кроссплатформенных приложениях написанных на С++?А то мне похоже уже пора головой об стену биться - если даже такое под виндой + msvc не работает:
wcout << L"[лол]" << endl;
Выводится первая скобка, после чего стрим падает в fail. Как выяснилось после ковыряний, преобразование из wchar_t в байты внутри стрима идет наитупейшим образом. Для того, чтобы заставить это все работать, приходится делать imbue локали с самописным codecvt в wcout. Короче, все через жопу.
И это не единственное место, где все через жопу ).
Хотелось бы простого и понятного солюшена, типа того, что есть в java.
Хм. Пожалуй изначальный вопрос стоит переформулировать - как вообще нормальные люди пишут кроссплатформенные приложения на С++?