Распознавание простого текста.
готовые либы смотрел?
зы
можно кстати посмотреть либы для распознавания капчи
зы
можно кстати посмотреть либы для распознавания капчи
Готовые либы очень не хочется использовать потому что:
1) Пишется для себя и во многом ради процесса.
2) Не хочется разбираться с их использованием.
3) Задача существенно более частная, чем распознавание рукописного текста.
Так что подойдут только очень простые либы.
1) Пишется для себя и во многом ради процесса.
2) Не хочется разбираться с их использованием.
3) Задача существенно более частная, чем распознавание рукописного текста.
Так что подойдут только очень простые либы.
честно говоря, я бы в твоей задаче все случаи для одной цифры описал (случаи, когда картинко - это 1, когда 2, когда 3 итп). на каждую цифру, думаю, максимум 100 случаев будет. итого, 1000 строк в текстовом файле. халява. нахуя нейросеть городить.
52 буквы и 10 цифр, итого 62*100=6200. Как такую базу создать?
Короче ждать, пока появятся все 100 начертаний каждого символа, не вариант.
а, буквы еще. ну тогда больше, конечно, будет база.
ну если есть возможность на практике тестироваться, то я бы все равно делал базу.
руками бы распознал 1200 картинок, скажем, а потом уже можно только смотреть,
где система выдает "нет буквы" и добавлять в базу такие случаи.
но ты смотри сам, как бы, может тебе нейросеть быстрее будет написать.
или может тебе потом расширяться надо будет.
ну если есть возможность на практике тестироваться, то я бы все равно делал базу.
руками бы распознал 1200 картинок, скажем, а потом уже можно только смотреть,
где система выдает "нет буквы" и добавлять в базу такие случаи.
но ты смотри сам, как бы, может тебе нейросеть быстрее будет написать.
или может тебе потом расширяться надо будет.
Нейросеть, которая определяет отдельный символ, как выяснилось пишется легко. Проблема с парсингом картинки на отдельные символы 
на картинке примере символы разделены полосой "все пиксели чёрные".
Этой полоски может не быть. Кроме того ширина символа меняется, т.е. я распознал цифру и не знаю, на сколько нужно отступать вправо, чтобы начинать распознавать следующую.
ну да, я понимаю, но картинка-пример выглядит так, что я не могу себе представить ситуации, когда отступать нужно будет, скажем, на три не полностью черных полоски. если после распознавания известна правая граница распознанного символа, то я бы просто отступал вправо до следующей, содержащей хотя бы один белый пиксель полоски (это будет начало следующего символа)...
если граница после распознавания не известна, то я бы какую-то простую эвристику заюзал опять же. типа бъем по черным полоскам, если получилось < 5 кусков, то самый широкий бьем пополам и пробуем распознать, если получилось "плохо", то выбираем другое разбиение пополам, итп...
ну ладно, вобщем. тебя наверное такой вариант не устроит тоже.
если граница после распознавания не известна, то я бы какую-то простую эвристику заюзал опять же. типа бъем по черным полоскам, если получилось < 5 кусков, то самый широкий бьем пополам и пробуем распознать, если получилось "плохо", то выбираем другое разбиение пополам, итп...
ну ладно, вобщем. тебя наверное такой вариант не устроит тоже.
Допустим оказалось два символа, неразделенных черной полоской. Если попробовать поделить пополам наугад и ошибиться, то в одной из половинок получится что-то не похожее ни на один символ и нейросеть выдаст что-нибудь непредсказуемое.
Ситуация ухудшается тем, что 1) могут слипнутся больше двух символов и 2) есть знаки препинания, которые узкие, соответственно деление слипнувшегося куска на равные части не проходит.
Ситуация ухудшается тем, что 1) могут слипнутся больше двух символов и 2) есть знаки препинания, которые узкие, соответственно деление слипнувшегося куска на равные части не проходит.
Может это поможет. http://en.wikipedia.org/wiki/Viterbi_algorithm
о ширине - не совсем, может быть +- пиксель.Похоже на моноширинный шрифт.
Допустим оказалось два символа, неразделенных черной полоской. Если попробовать поделить пополам наугад и ошибиться, то в одной из половинок получится что-то не похожее ни на один символ и нейросеть выдаст что-нибудь непредсказуемое.Надо не пополам делить, а по известной ширине символа. Небольшая вариация ширины добавит вариантов деления. Надо будет выбрать среди них самый лучший в некотором смысле.
Ситуация ухудшается тем, что 1) могут слипнутся больше двух символов и 2) есть знаки препинания, которые узкие, соответственно деление слипнувшегося куска на равные части не проходит.
Знаки препинания не должны быть проблемой в моноширинном шрифте. Они Уже, но за ними (или перед ними, если выравниваются расстояния между правыми границами символов) идет дополнительный пробел, дополняющий до нужной ширины.
Главное заметить какие расстояния в этом шрифте константа - расстояние между левыми границами символов или между правыми. И соответственно выделять гипотезы именно этих границ и делить по ним.
Допустим оказалось два символа, неразделенных черной полоской. Если попробовать поделить пополам наугад и ошибиться, то в одной из половинок получится что-то не похожее ни на один символ и нейросеть выдаст что-нибудь непредсказуемое.Попробуй волновой алгоритм, у меня коллега писал распознавание сложной капчи на нём: http://ocrai.narod.ru/vectory.html; в его случае нейросети слабо помогали, но в твоём случае должно быть совсем просто.
Может лучше юзануть алгоритм скелетизации?
вернее я не это хотел сказать. волновой алгоритм по ссылке - он для скелетизации, но как это решит проблему слипшихся цифр?
Вообще хотелось бы увидеть исходной картинку (лучше штук 10 исходных а не бинаризованную, как это было в прошлой теме по распознаванию
вернее я не это хотел сказать. волновой алгоритм по ссылке - он для скелетизации, но как это решит проблему слипшихся цифр?
Вообще хотелось бы увидеть исходной картинку (лучше штук 10 исходных а не бинаризованную, как это было в прошлой теме по распознаванию
волновой алгоритм по ссылке - он для скелетизации, но как это решит проблему слипшихся цифр?Разбить слипшиеся скелеты на части на порядки проще, чем слипшиеся растры. Множество скелетов фактически будет несвязным графом, любые две вершины которого обладают полезными свойствами - геометрическим расстоянием и цветом. Это позволит связать граф и найти в нём скелеты, подходящие под вход нейронной сети.
Два слипшихся нуля могут дать такой вот скелет насколько я понимаю, и в общем случае конечно не очень понятно как его расклеивать
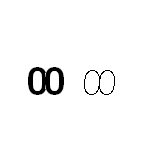
но наверрное это в общем случае проще чем расклеивать растр
но наверрное это в общем случае проще чем расклеивать растр
Вообще хотелось бы увидеть исходной картинку (лучше штук 10 исходных а не бинаризованную, как это было в прошлой теме по распознаваниюЭто точно. В частности интересно, как выглядят строчки с '1' (узкий символ 'm' (широкий символ) и знаками препинания для проверки гипотезы о моноширинности шрифта, которая делает разбивку на символы тривиальной.
При этом такую пару 'OO' довольно трудно отличить от пары 'CO'.
А еще траблы с отличением 'm' от 'rn'.
По-любому для высокого результата распознавания надо строить несколько вариантов разбиения на символы. Для рукописного текста для этого очень пригодится граф. Для машинопечатного текста иногда достаточно вертикальные столбики и горизонтальные палочки выделить.
А еще есть Скрытая Марковская Модель, которую можно учить и применять без разбиений на символы (но разбить на некие атомы - ребра графа или столбики - все равно придется). Только материала для обучения много надо, для машинопечатного, наверное, тысяч 10 строчек хватит.
А еще траблы с отличением 'm' от 'rn'.
По-любому для высокого результата распознавания надо строить несколько вариантов разбиения на символы. Для рукописного текста для этого очень пригодится граф. Для машинопечатного текста иногда достаточно вертикальные столбики и горизонтальные палочки выделить.
А еще есть Скрытая Марковская Модель, которую можно учить и применять без разбиений на символы (но разбить на некие атомы - ребра графа или столбики - все равно придется). Только материала для обучения много надо, для машинопечатного, наверное, тысяч 10 строчек хватит.
и в общем случае конечно не очень понятно как его расклеиватьПри известной ширине символов всё понятно. Я же написал, что вершины и дуги получаемого несвязного графа имеют свойства: расстояние и цвет. При расклеивании можно учитывать, что у тебя должны получаться паттерны заданной ширины. Также при склеивании и расклеивании можно учитывать цвет вершин и дуг (хотя бы grayscale). Опять же, перебрать варианты в скелете, каждый раз прогоняя каждый разумный вариант через нейронные сети, намного проще, чем перебирать варианты в растре.
Вообще хотелось бы увидеть исходной картинку (лучше штук 10 исходных)
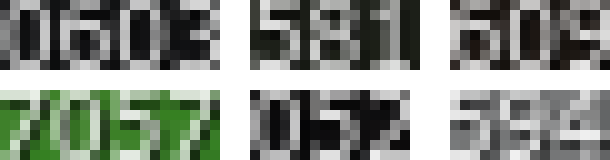
если сравнивать эти картинки и картинку в первом посте - кажется, что ты слишком сурово опроксимировал. может к некому среднему(по плотности) цвету привести
офигеть как всё размыто, а как ты назад контраст повышаешь?
такое впечатление, что это просто антиалиасинг цифр с тенью плюс автоматический кернинг. тут можно пойти от обратного: рисуешь цифру/букву какой-нибудь графической библиотекой в нужном разрешении и нужного размера, потом тупо сравниваешь с исходником, если совпадение превысило порог - значит цифру угадал. Есть вероятность, что библиотека, которая будет рисовать тебе цифры, будет делать это так же, как и та, что рисует исходные картинки.
думаю что и файнридер такое не распознает
В общем практически добился, чего хотел:
Цифры разделяю по наименее ярким вертикальным полоскам, учитывая минимальную и максимальную возможную ширину цифр.
Дальше гашу все пикселы с яркостью меньше пороговой. Пороговую яркость выбираю так, чтобы наверняка погасить фон, возможно потеряв что-то из самих цифр. Дополнительно в каждом квадрате 2x2 гашу самый неяркий пиксел, это можно делать, учитывая что толщина линий шрифта ровно 1 пиксел.
Результат распознаю однослойной нейросетью.
Цифры разделяю по наименее ярким вертикальным полоскам, учитывая минимальную и максимальную возможную ширину цифр.
Дальше гашу все пикселы с яркостью меньше пороговой. Пороговую яркость выбираю так, чтобы наверняка погасить фон, возможно потеряв что-то из самих цифр. Дополнительно в каждом квадрате 2x2 гашу самый неяркий пиксел, это можно делать, учитывая что толщина линий шрифта ровно 1 пиксел.
Результат распознаю однослойной нейросетью.
Оставить комментарий
Devid
Текст выводится на экран другой программой. Размер символов по высоте фиксирован, по ширине - не совсем, может быть +- пиксель. Кроме того текст выводится на полупрозрачном фоне и символы размыты.Если отсечь все пикселы с яркостью меньше пороговой, то получится что-то типа: (каждый квадрат - 1 пиксель)
Каждый отдельный символ легко распознать, например однослойной нейросетью. Но проблема в том, что промежутки между символами могут меняться, как и ширина самих символов. То есть, например, 8 может быть такой:
011110
110011
111111 - пиксели с боков менее яркие.
110011
011110
а может и такой
011110
010010
011110
010010
011110