помогите с mysql плз
Обычно на такие вопросы отвечают фразой "Вам это не нужно".
Хоть такой ответ мне и не нравится, но что-то в нём в данном случае есть
Хоть такой ответ мне и не нравится, но что-то в нём в данном случае есть
проблема в том, что в данном случае как раз-таки нужно именно это.
проблема в том, что в данном случае как раз-таки нужно именно это.расскажи плиз зачем это нужно, создавать таблицы в зависимости от даты
очень интересно
в требованиях к структуре БД стоит так. мне это самому кажется дикостью, но что делать.
требования составляли большие дяди, их не переубедишь.
требования составляли большие дяди, их не переубедишь.
расскажи плиз зачем это нужно, создавать таблицы в зависимости от датыЭто-то как раз понятно - секционирование. MySQL его умеет только с версии 5.1
Только зачем это делать через ХП?
Не проще сразу в запросе нужную таблицу указать?
Это-то как раз понятно - секционирование. MySQL его умеет только с версии 5.1Ну про partitioning понятно. Меня именно процедуры хранимые смутили.
Только зачем это делать через ХП?
Не проще сразу в запросе нужную таблицу указать?
А mysql 5.1 меня кстати очень порадовал. Он некоторые вещи более разумно делает. И при переходе отвалилось только то, за что убивать надо - соответственно правильно, что отвалилось
И кстати автору можно использовать мегаметод прегенерации таблиц. То есть создавать некоторым скриптиком, пускаемым по крону пару раз в неделю таблички на месяц вперёд и не париться о проверке.
не проще, потому что к БД будут обращаться из многих мест и с помощью разных интерфейсов. то есть, чтобы никто особо не думал, а просто вызывал процедуру(она кроме этого еще будет кое-чего делать).
Чё то как то не этак.
Имхо правильнее хранить в одной таблице с отдельным столбом гггг-мм, в неё же и писать без проверок. И наделать кучу вьюх с именами гггг-мм если уж совсем нужно. (хотя мб конечно при больших обьёмах напрямую к таблице будет существенно быстрее обращацца, только наверняка при какой то большой аналитике ещё и union all всякие будут в случае отдельных таблиц).
Имхо правильнее хранить в одной таблице с отдельным столбом гггг-мм, в неё же и писать без проверок. И наделать кучу вьюх с именами гггг-мм если уж совсем нужно. (хотя мб конечно при больших обьёмах напрямую к таблице будет существенно быстрее обращацца, только наверняка при какой то большой аналитике ещё и union all всякие будут в случае отдельных таблиц).
я уже говорил, что знаю, что это не так, но задача стоит так - почесать правой пяткой левое ухо.. вопрос не в том, что это неестественно, а в том, как это сделать.
create table if not exist gggg-mm (...........)
Если вот эта вот if not exist долго выполняется - то мб надо создать отдельную таблицу и хранить в ней уже созданные и проверять сначала по ним. Как то так наверно
create table tbl_names(varchar tbl_name);
.....
IF NOT EXIST (select tbl_name from tbl_names where tbl_name=@ggggmm)
THEN IF NOT EXIST @ggggmm
THEN
create table @ggggmm (....);
insert into tbl_names values(@ggggmm);
END IF;
END IF;
~~Action~~
.....
ps. Сам в mysql почти не работал - но если верить гуглу по диагонале - то нечто такое там можно осуществить по идее. Самому проверять лень.
не хочет он видеть переменную в CREATE TABLE. ругается на нее.
не хочет он видеть переменную в CREATE TABLE. ругается на нее.тогда генери как текст и запускай через какой-нибудь exec
сенькс!
всем спасибо. я уже придумал еще один изврат(написал dll-ку и послал всем кто в базу будет лазать но это лучше.
всем спасибо. я уже придумал еще один изврат(написал dll-ку и послал всем кто в базу будет лазать но это лучше.
Имхо правильнее хранить в одной таблице с отдельным столбом гггг-мм, в неё же и писать без проверок. И наделать кучу вьюх с именами гггг-мм если уж совсем нужно.Эээ. Если и делать вьюшки, то наоборот. Куча мелких таблиц и одна общая вьюшка с триггером INSTEAD OF INSERT.
PS Всем кому идея маленьких таблиц кажется неестественной, почитайте что такое секционирование и зачем оно нужно.
Или попробуйте поработать с таблицами объемом 100+Гб.
Самый правильный путь - использованить функции секционирования самой БД. Какая версия мускуля используется кстати?
Почитал
спасибо
Кругозор ещё немного расширен
спасибо
Кругозор ещё немного расширен
Или попробуйте поработать с таблицами объемом 100+Гб.Самый ice.
После проктирования такого становишься keymaster
<писько>
Rows: 1139182874
Avg_row_length: 230
Data_length: 262456475648
Max_data_length: 0
Index_length: 108979503104
Data_free: 0
Auto_increment: 1245841535
</писько>
По этому ещё и селектиццо нормально
а у меня вот щас из таблицы в 100 штук записей селектится 10 секунд 
а если еще и ордербай по таймстампу стелать ...
а если еще и ордербай по таймстампу стелать ...
а у меня вот щас из таблицы в 100 штук записей селектится 10 секунд100 или 100 000 ?
а если еще и ордербай по таймстампу стелать ...
кстате ботай как создавать индексы, чтобы при ордере using filesort не было.
Боюсь у него Оракл и никакого filesort не будет, пока есть свободная память.
2: [телепат мод]Попробуй в запросе TO_DATE <-> TO_TIMESTAMP поменяй, может поможет.[/телепат мод]
2: [телепат мод]Попробуй в запросе TO_DATE <-> TO_TIMESTAMP поменяй, может поможет.[/телепат мод]
Боюсь у него Оракл и никакого filesort не будет, пока есть свободная память.ну в мускуле то тоже filesort не означает создание файла на диске.
Я подозреваю что в оракле есть индексы и что они устроены тоже примерно как деревья. То есть если дерево индексов дополнить полем, по которому идёт сортировка то при использовании такого индекса не нужно будет выбирать ряды и их сортировать, а ссылки на них будут лежать в дереве уже в отсортированном виде.
Блин, какую-то фигню написал, но надеюсь понятно что имеется ввиду
Все зависит от того соклько записей выбираться будет.
Если процента 2-4, то имеет смысл индекс по полю, по которому сортировка производится, построить.
А если больше, то быстрее полный просмотр таблицы и сортировка результата в памяти.
Если процента 2-4, то имеет смысл индекс по полю, по которому сортировка производится, построить.
А если больше, то быстрее полный просмотр таблицы и сортировка результата в памяти.
Боюсь у него Оракл и никакого filesort не будет, пока есть свободная память.а если оракл память почти не жрет, в том числе и постоянный тяжелых запросах - это что значит?
что ему память не нужна? или что у него есть некая настройка, которую надо выставить, чтобы он начал память жрать?
А если больше, то быстрее полный просмотр таблицы и сортировка результата в памяти.почему?
на первый взгляд не очевидно.
если индекс легкий, то вычитка индекса на первый взгляд может быть выгоднее, даже если мы читаем 70% записей.
Все зависит от того соклько записей выбираться будет.Скорее наоборот, если мало записей выбирается, а потом сортируется, то оверхед от доступа к индексу может получиться больше каким-то образом, чем сортировка.
Если процента 2-4, то имеет смысл индекс по полю, по которому сортировка производится, построить.
А если больше, то быстрее полный просмотр таблицы и сортировка результата в памяти.
А если записей много, то время сортировки растёт не медленнее чем O(n*log(n а при наличии индекса время должно более линейно расти.
Он при запуске отжирает ровно столько, сколько ему сказали в параметрах.
Под свободной памятью я имел в виду, сколько у него неиспользованной памяти в SGA осталось.
Под свободной памятью я имел в виду, сколько у него неиспользованной памяти в SGA осталось.
Вот на процессорное время смотрят в последнюю очередь.
Самые тяжелые операции - логические чтения (из буфера) и физические чтения (с диска).
Когда мы идем по индексу, то на каждую запись приходиться по одному чтению из таблицы (если нам не хватило полей индекса и мы хотим еще какие-то поля из таблицы).
Когда мы просматриваем таблицу, читая все блоки по порядку, в одином блоке оказывается сразу несколько записей (штук 20 например).
В итоге, просматривая таблицу, а не индекс, мы выполним меньше чтений.
Самые тяжелые операции - логические чтения (из буфера) и физические чтения (с диска).
Когда мы идем по индексу, то на каждую запись приходиться по одному чтению из таблицы (если нам не хватило полей индекса и мы хотим еще какие-то поля из таблицы).
Когда мы просматриваем таблицу, читая все блоки по порядку, в одином блоке оказывается сразу несколько записей (штук 20 например).
В итоге, просматривая таблицу, а не индекс, мы выполним меньше чтений.
Когда мы идем по индексу, то на каждую запись приходиться по одному чтению из таблицы (если нам не хватило полей индекса и мы хотим еще какие-то поля из таблицы).Бред какой-то или я не понял про что ты. Индекс кешируется с таким же успехом, с каким и данные. Конечно, индекс довавляет оверхед в виде дополнительных чтений с диска. Но этот оверхед линейный (вроде бы а сортировка растёт нелинейно всё же. Явно она когда-то должна "обогнать" этот оверхед.
Когда мы просматриваем таблицу, читая все блоки по порядку, в одином блоке оказывается сразу несколько записей (штук 20 например).
В итоге, просматривая таблицу, а не индекс, мы выполним меньше чтений.
а у меня вот щас из таблицы в 100 штук записей селектится 10 секундплан в студию
а если еще и ордербай по таймстампу стелать ...
mysql 5.0.51
я, собственно, так и делал, как ты написал. правда, не получилось сделать хранимую процедуру, как было запланировано, ну да фиг с ним. я запутался: неужели нельзя использовать переменную в запросе CREATE TABLE @table [.....]? Первый раз с такой необходимостью столкнулся просто.
я, собственно, так и делал, как ты написал. правда, не получилось сделать хранимую процедуру, как было запланировано, ну да фиг с ним. я запутался: неужели нельзя использовать переменную в запросе CREATE TABLE @table [.....]? Первый раз с такой необходимостью столкнулся просто.
Индекс кешируется с таким же успехом, с каким и данные.Еще раз. Чтение, даже из кеша - это дорогая операция.
Требуемая версия блока может быть вообще только в кеше на каком нибудь другом узле кластера.
Или ее может не быть и придется откатывать блок undo логами.
Чем чтений меньше, тем быстрее работает запрос.
Конечно, индекс довавляет оверхед в виде дополнительных чтений с диска. Но этот оверхед линейный (вроде бы а сортировка растёт нелинейно всё же. Явно она когда-то должна "обогнать" этот оверхед.Правильно, индекс добавляет линейный оверхед, но константа огромная, потому что мы вынуждены читать один и тот же блок таблицы несколько раз.
Причем даже кешировние не спасет, если таблица целиком в память не помещается, потому что мы читаем блоки таблицы в случайном порядке.
Во, нашел картинку иллюстрирующую выборку по индексу.
Может понятней будет.
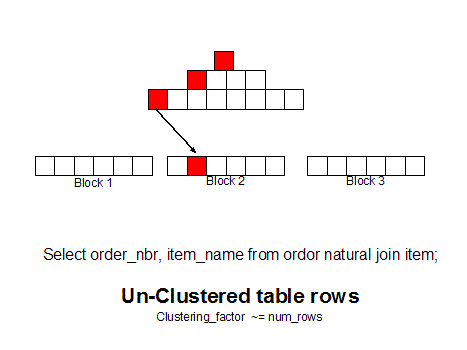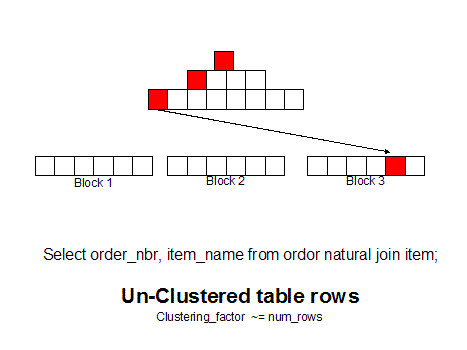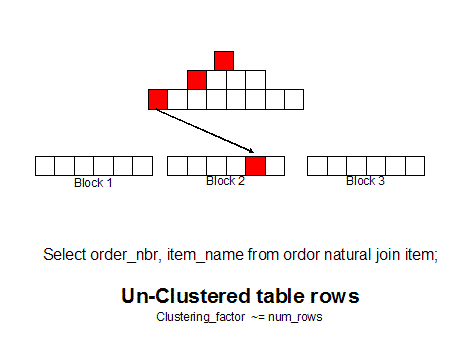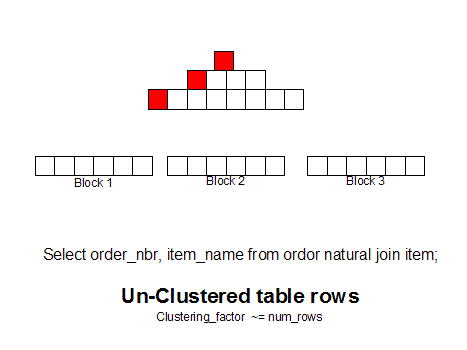
Каждый красный квадратик - чтение блока.
Может понятней будет.
Каждый красный квадратик - чтение блока.
Примерчик.
Чтение из таблицы: два поля, миллион записей, по второму построен индекс. Все данные в памяти.
Бред какой-то или я не понял про что ты. Индекс кешируется с таким же успехом, с каким и данные. Конечно, индекс довавляет оверхед в виде дополнительных чтений с диска. Но этот оверхед линейный (вроде бы а сортировка растёт нелинейно всё же. Явно она когда-то должна "обогнать" этот оверхед.
Чтение из таблицы: два поля, миллион записей, по второму построен индекс. Все данные в памяти.
StmtText StmtId NodeId Parent PhysicalOp LogicalOp Argument DefinedValues EstimateRows EstimateIO EstimateCPU AvgRowSize TotalSubtreeCost OutputList Warnings Type Parallel EstimateExecutions
------------------------------------------------------------------------------- ----------- ----------- ----------- ------------------------------ ------------------------------ --------------------------------------------- ----------------------------------------------------------- ------------- ------------- ------------- ----------- ---------------- ----------------------------------------------------------- -------- ---------------------------------------------------------------- -------- ------------------
select * from table_3 order by col1; 1 1 0 NULL NULL 1 NULL 1000000 NULL NULL NULL 55,3386 NULL NULL SELECT 0 NULL
|--Parallelism(Gather Streams, ORDER BY:([test].[dbo].[table_3].[col1] ASC 1 2 1 Parallelism Gather Streams ORDER BY:([test].[dbo].[table_3].[col1] ASC) NULL 1000000 0 6,65525 24 55,3386 [test].[dbo].[table_3].[rn], [test].[dbo].[table_3].[col1] NULL PLAN_ROW 1 1
|--Sort(ORDER BY:([test].[dbo].[table_3].[col1] ASC 1 3 2 Sort Sort ORDER BY:([test].[dbo].[table_3].[col1] ASC) NULL 1000000 0,005630631 45,743 24 48,68335 [test].[dbo].[table_3].[rn], [test].[dbo].[table_3].[col1] NULL PLAN_ROW 1 1
|--Table Scan(OBJECT:([test].[dbo].[table_3] 1 4 3 Table Scan Table Scan OBJECT:([test].[dbo].[table_3]) [test].[dbo].[table_3].[rn], [test].[dbo].[table_3].[col1] 1000000 2,384685 0,5500392 24 2,934724 [test].[dbo].[table_3].[rn], [test].[dbo].[table_3].[col1] NULL PLAN_ROW 1 1
Table 'table_3'. Scan count 3, logical reads 3216, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 3172 ms, elapsed time = 9470 ms.
StmtText StmtId NodeId Parent PhysicalOp LogicalOp Argument DefinedValues EstimateRows EstimateIO EstimateCPU AvgRowSize TotalSubtreeCost OutputList Warnings Type Parallel EstimateExecutions
--------------------------------------------------------------------------------------------------------- ----------- ----------- ----------- ------------------------------ ------------------------------ ----------------------------------------------------------------------------------- ----------------------------------------- ------------- ------------- ------------- ----------- ---------------- ----------------------------------------------------------- -------- ---------------------------------------------------------------- -------- ------------------
select * from table_3 with (index(test_index order by col1; 1 1 0 NULL NULL 1 NULL 1000000 NULL NULL NULL 175,537 NULL NULL SELECT 0 NULL
|--Nested Loops(Inner Join, OUTER REFERENCES:([Bmk1000], [Expr1005]) WITH ORDERED PREFETCH) 1 2 1 Nested Loops Inner Join OUTER REFERENCES:([Bmk1000], [Expr1005]) WITH ORDERED PREFETCH NULL 1000000 0 4,18 24 175,537 [test].[dbo].[table_3].[rn], [test].[dbo].[table_3].[col1] NULL PLAN_ROW 0 1
|--Index Scan(OBJECT:([test].[dbo].[table_3].[test_index] ORDERED FORWARD) 1 4 2 Index Scan Index Scan OBJECT:([test].[dbo].[table_3].[test_index] ORDERED FORWARD, FORCEDINDEX [Bmk1000], [test].[dbo].[table_3].[col1] 1000000 2,106829 1,100157 24 3,206986 [Bmk1000], [test].[dbo].[table_3].[col1] NULL PLAN_ROW 0 1
|--RID Lookup(OBJECT:([test].[dbo].[table_3] SEEK:([Bmk1000]=[Bmk1000]) LOOKUP ORDERED FORWARD) 1 6 2 RID Lookup RID Lookup OBJECT:([test].[dbo].[table_3] SEEK:([Bmk1000]=[Bmk1000]) LOOKUP ORDERED FORWARD [test].[dbo].[table_3].[rn] 1 0,003125 0,0001581 15 168,15 [test].[dbo].[table_3].[rn] NULL PLAN_ROW 0
Оверхед на доступ по индексу получается огромный: 1002854 логических чтений при использовании индекса против 3216 при последовательном чтении.Чего-то нифига не понял, откуда эти цифры. Всё что понял из таблицы - это total time и ещё колонки EstimatedIO и EstimatedCPU. Не сильно вроде отличается. Только CPU с индексом меньше надо.
Еще раз. Чтение, даже из кеша - это дорогая операция.Фига себе. Чего это за кеш такой тогда? Смысл любого кеша - чтобы операция стала недорогой. Про вытесненные данные не надо говорить, т.к. я имею в виду именно откешированные. Мы же говорим про "чтение из кеша", а не про "чтение с кешированием".
Требуемая версия блока может быть вообще только в кеше на каком нибудь другом узле кластера.Да понятно, что там много нюансов. Я просто чего хотел сказать:
Или ее может не быть и придется откатывать блок undo логами.
Чем чтений меньше, тем быстрее работает запрос.
Правильно, индекс добавляет линейный оверхед, но константа огромная, потому что мы вынуждены читать один и тот же блок таблицы несколько раз.
Причем даже кешировние не спасет, если таблица целиком в память не помещается, потому что мы читаем блоки таблицы в случайном порядке.
1) Твоё утверждение о том, что индекс лучше использовать на маленьких выборках - плохое (как мне кажется т.к. сортировка на маленьких выборках очень быстрая, ей можно пренебречь даже. Так, что любой оверхед заранее будет медленнее.
2) А при больших выборках всё не однозначно - есть много нюансов, зависящих от реализации и пр. И заранее утверждать что будет быстрее - неправильно. Думаю, что может быть по разному. Нужно ставить опыты в каждом случае.
На таблицу вообще не смотри, там догадки оптимизатора.
Смитри на строчки Execution Times и logical reads.
Смитри на строчки Execution Times и logical reads.
Фига себе. Чего это за кеш такой тогда? Смысл любого кеша - чтобы операция стала недорогой.Просто этих чтений из кеша становиться ОЧЕНЬ много при доступе по индексу.
Смитри на строчки Execution Times и logical reads.Ага, теперь вижу. Первое заметил сразу, а 2-е только сейчас.
По времени на самом деле не так уж сильно различается.
А что такое "logical reads"?
Кстати, для чистоты эксперимента это надо было ещё раз 10 повторить, чтобы с кешированием вопрос решился.
А logical reads это и есть чтения из кеша.
Оставить комментарий
Vadim69
подскажите плиз, как с помощью хранимой процедуры сделать такое:получаем одним из параметров тип DATE, берем оттуда ГГГГ-ММ, смотрим, нет ли в базе таблицы с таким именем, и если нет, создаем и вставляем туда запись, а если есть, то просто вставляем туда запись.