Редактировать PDF файл???
Adobe Acrobat Professional 7.0
В 7-м даже редактировать можно? Это как выглядит-то хоть?
Ты путаешь простой акробат с ридером 
Ридером никаким нельзя, простой - это редактор
Ридером никаким нельзя, простой - это редактор
Ути-пути, доктор меня лечить пришел. Не учи отца ебаться. Что конкретно в 7-м акробате можно редактировать?
А редактирования pdf-ов тебе мало? 
не поверишь!
1) нажимаешь кнопочку "редактировать текст"
2) встаёшь в нужное место
3) редактируешь


1) нажимаешь кнопочку "редактировать текст"
2) встаёшь в нужное место
3) редактируешь
Это начиная с 7-го стало так можно делать? Или я 6-м такого не замечаю просто?
Это начиная с 7-го стало так можно делать? Или я 6-м такого не замечаю просто?ВСЕ Adobe Acrobat (не ридеры) являются редакторами pdf!
А для чего они по-твоему тогда вообще нужны?
А можешь скриншот запостить «до редактирования» и «в процессе»?
акробат не стоит - pdf не редактирую. больше просматриваю ридером.
Но как-то раз редактировал пятым.
А что, какие-то проблемы?
Но как-то раз редактировал пятым.
А что, какие-то проблемы?
Видимо, мне ни разу в руки не попадались PDF-ки, которые можно редактировать. Вообще, я просто не представляю себе как это возможно реализовать: всякие отступы, переносы и прочие параметры абзаца. Ничего этого в PDF не хранится, поэтому он такой маленький и получается в итоге. Тем более, что чаще всего в PDF зашивается не весь шрифт, а только используемые символы. Откуда он недостающие брать будет?
Если ПДФка сделана из jpeg'а, то, пожалуй, её действительно нельзя редактировать.
А шрифты эта зараза использует системные - по крайней мере имеет свойство ругаться, когда нужных не находит.
А шрифты эта зараза использует системные - по крайней мере имеет свойство ругаться, когда нужных не находит.
нажимаешь кнопочку "редактировать текст"Где она находится? Что-то не могу найти.
Ребята, вам нужно сначала изучить как делается PDF-ка. Поясню вкратце. Текст, который мы набрали в InDesign, Quark или еще в чем-то — это буквы, расположенные на своих местах. Программа верстки занимается именно тем, что расставляет каждую буковку, точку и закорючку на свое место. Она определяет интервалы между буквами (по метрике шрифта, как Quark или оптически, как умеет InDesign выравнивает края, переносит слова и делает еще кучу важной работы. Тем же самым занимается и TeX, кстати. Так вот, когда из программы верстки мы экспортируем файл в PDF, туда записывается положение символа и его код. И все, больше, по сути, никакой информации. Изображения букв могут браться из «системного» шрифта, а может быть и так, что они будут прошиты прямо в PDF по желанию автора. Ну и спрашивается тогда: как вообще Acrobat может брать на себя функции программы верстки (которых очень-очень много откуда он будет доставать изображения недостающих символов, как будет выравнивать, переносить и т. д. и т. п.? Об этом никто не задумывался?
Ответь пожалуйста тогда, чем акробат отличается от ридера?
О! кстати мега сенкс про ликбез кстати у адобе есть прога для верстки?
кстати у адобе есть прога для верстки?Уж я тебя! Поставил специально пятый акробат.
Итак, берём документ: стандарт ISO 9899 (Programming languages — C)
Начинаем редактировать текст....
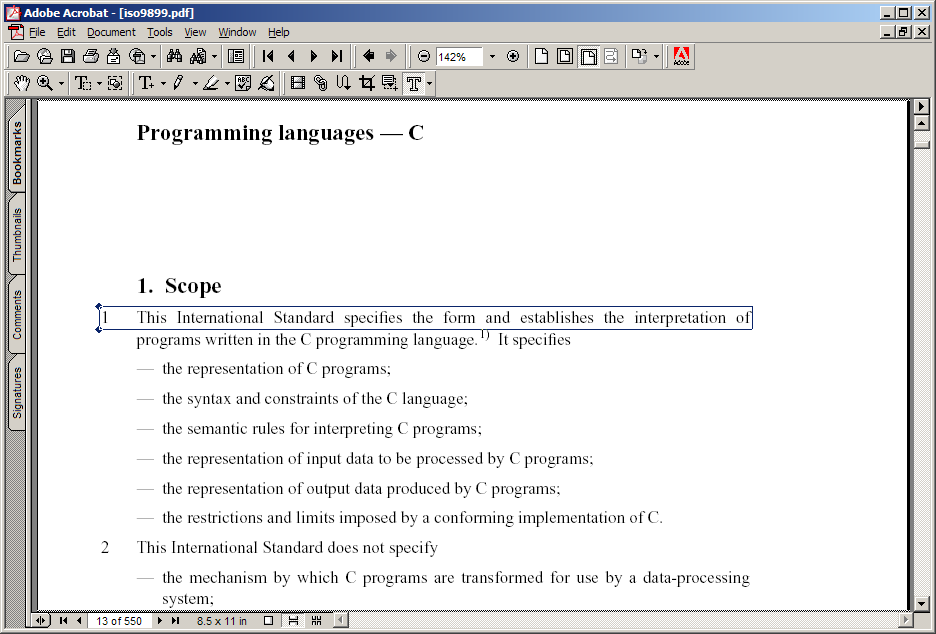
получаем:
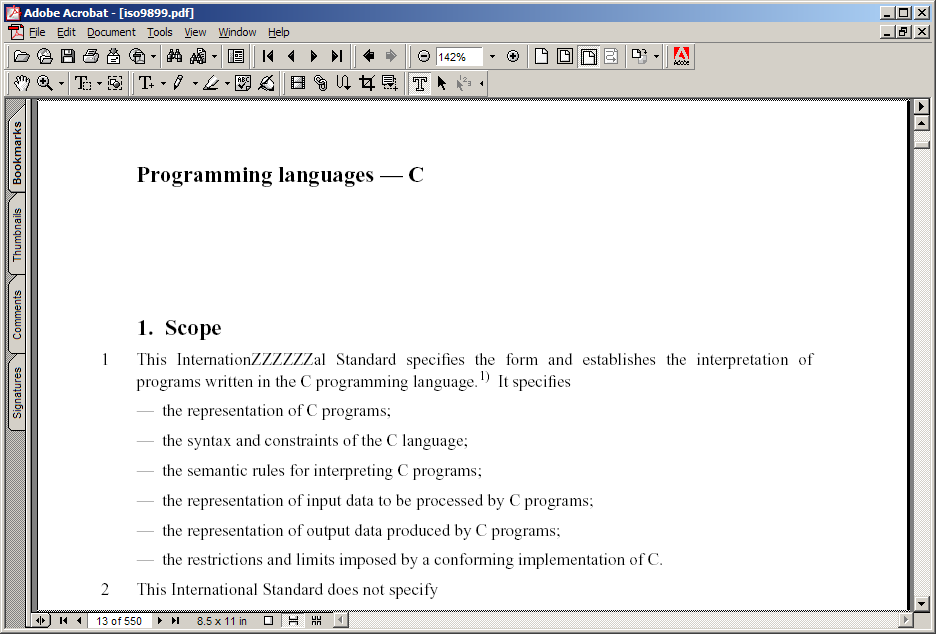
структура этого PDF такова, что он свёрстан построчно - мы можем редактировать построчно (например, мы не можем разорвать строку или склеить две строки)
есть документы, которые свёрстаны побуквам - это вообще пипец. мы можем изменять отдельные буквы, но не слова.
Документы из ТеХ-а не редактируются
Документы, сдистилленные из ворда редактируются.
Итак, берём документ: стандарт ISO 9899 (Programming languages — C)
Начинаем редактировать текст....
получаем:
структура этого PDF такова, что он свёрстан построчно - мы можем редактировать построчно (например, мы не можем разорвать строку или склеить две строки)
есть документы, которые свёрстаны побуквам - это вообще пипец. мы можем изменять отдельные буквы, но не слова.
Документы из ТеХ-а не редактируются
Документы, сдистилленные из ворда редактируются.
Акробат умеет делать PDF-ки из инетовских страничек и всяких там документов MS Office. Плюс обладает замечательным инструментом для копирования текста, который, правда, не всегда работает (в силу специфики некоторых PDF).
Adobe InDesign.
так типа индезигн лучче всех в формат пдф делает? или кварк лучче?
Этот результат я и ожидал. Я, как всегда, развесил уши, поняв «редактирование» в слишком широком смысле. Это, конечно, никакое не редактирование. Это, как оно правильно называется «TouchUp». Вам тут маркетологи сливки на говне взбивают, а вы ведетесь. Только что придумал классное сравнение: PDF — это как уже собранный исполняемый модуль. В exe-файлах тоже ведь можно текст переправить, но с ограничениями. А в исходнике — сколько влезет. Вот и с «редактированием» PDF такая же история.
Это кому как нравится. Старички все привыкли в Quark делать, молодежь InDesign хавает. Вся засада в том, что в обоих продуктах есть непересекающиеся нужные фичи. Лично я с детства подсел на Adobe: все продукты выглядят однотипно, используют почти одинаковые сочетания клавиш, все друг под друга заточены, да и вообще — сами по себе просто супер.
А теперь ответ по теме: не знаю.
Просто второй раз правильно вопрос прочитал.
Просто второй раз правильно вопрос прочитал.
Плюс обладает замечательным инструментом для копирования текстаридер тоже умеет, вроде
По-моему, нет.
копирование - запросто. даже картинки.

Круто, а я и не знал. Всегда нормальный ставил, Reader не изучал никогда.
Я ридер именно по этому и пользую, ибо PDF готовлю в ТеХе, а просматривать он умеет замечательно. и копировать.
бывают, конечно, PDF, которые очень извратно сделаны. Например, без шрифтов и все буквы в кривые переведны - тут уж ничего сделать нельзя.. Или например, когда в документе каждое слово печатается задом наперёд (a-la creation order на формах в VB/Delphi etc). т.е. каждая буква на своём месте, однако в документе сначала прописана последняя буква, потом предпоследняя и т.д. Текст виден нормально, а при копировании ерунда получается
бывают, конечно, PDF, которые очень извратно сделаны. Например, без шрифтов и все буквы в кривые переведны - тут уж ничего сделать нельзя.. Или например, когда в документе каждое слово печатается задом наперёд (a-la creation order на формах в VB/Delphi etc). т.е. каждая буква на своём месте, однако в документе сначала прописана последняя буква, потом предпоследняя и т.д. Текст виден нормально, а при копировании ерунда получается
Вот меня такие вещи как раз и засмущали. Некоторые ведь даже шифровать пытаются, типа, собственную кодировку зашить вместо стандартной. Короче, вывод такой: без исходника нормально поправить текст не получится.
Вообщем пока не нашел ни одной утилитки которая могла бы перевести в doc или редактировать нормально. То что здесь рекомендовали фактически ничего не подходит. Как оказалось, многие утилиты криво переводят файл в doc не сохраняя формат файла или не поддерживая русских букв. Просто текст скопировать нет необходимости, мне нужно сохранить все таблицы, разметку и.т.д. Тут прочитал, что FineReader это делает (сильно сомневаюсь, что он сохранит таблицы и разметку, так как его основная функция распознать текст да и то там вручную править надо. Пока не пробовал, в надежде еще найти утилитку.
А вот эта статья:
А вот эта статья:
Недавно мне пришлось переводить значительную часть запароленного 4-х мегабайтного документа из формата Adobe PDF в формат MS Word. Будучи человеком (немного) ленивым, я не спешил набирать текст вручную, а стал искать способы конвертации. Задание осложнялось тем, что кроме пароля на выделение и копирование текста, документ имел в изобилии таблицы, картинки и нестандартное форматирование.
Через некоторое время я нашёл программу, с помощью которой можно снять пароль на выделение и копирование текста из PDF-документа. Это была знаменитая Advanced PDF Password Recovery, из-за которой её автор отсидел срок в американской тюрьме. Но для этой программы тоже пришлось искать кряк, иначе она только 10% декодировала. Очень трудно было найти программу и кряк/сериал одинаковой версии. Пришлось качать из разных захолустных мест. Но каково было моё удивление, когда я обнаружил, что все старания пропали даром: при копировании нормально отображавшегося текста с ним что-то вдруг происходило - то слова пропадали, то лишние пробелы где-попало вылазили.
Поиск инструмента перевода PDF в HTML, RTF или DOC перешёл в новую фазу. Я обнаружил на сайте Adobe on-line сервис по переводу злосчастного PDF в HTML, но оказалось, что он русских букв не понимает, а форматирование получается паршивое. Аналогичные результаты показывали всевозможные утилиты, заявлявшиеся их создателями, как лучшее средство для преобразования PDF. Русские символы с завидной настойчивостью превращались в пробелы, хотя в остальном форматирование документа оставалось.
Я обнаружил, что на официальном русском сайте Adobe открыто заявляется, что с русским языком в ПО для PDF проблемы, и применения PDF для русскоязычного документотворения не рекомендуется! А в журнале "Компьютерное Обозрение" была целая статья, восхвалявшая PDF и советовавшая им пользоваться Дилетанты...
И тут, словно озарение, на меня свалилась программа размером 2 метра BCL Drake 6.0. Я уж было, обрадовался, но что-то мне подсказывало, что не так всё просто, как говорится в мануалке. А там говорилось, что эта программа-плагин для Adobe Acrobat предназначена для простого и эффективного преобразования PDF в RTF с полным сохранением форматирования. Попробовал. Вместо русских букв увидел какую-то тарабарщину, но после применения средства Word'а "Сервис/Восстановить повреждённый текст..." получил родимую кириллицу. УРА! Но слова стали наезжать друг на друга, а каждый абзац (или строка, в зависимости от установок Drake'а) оказался внутри объекта "надпись". Редактирование такого "документа" - одна морока. Хотя с пивом покатит...
Я уже был готов присоединится к проекту "PDF to HTML" с открытым исходным кодом sourceforge.net/projects/pdftohtml, чтобы привить ему любовь к русским буквам, но тут товарищ Хоменко Ю. принёс мне уникальное средство для перевода документов из формата PDF. Оно открывает файлы PDF с паролями и без, замечательно сохраняет форматирование документа со всеми его таблицами и рисунками, но требует немного ручного труда. Это ABBYY FineReader 6.0 Professional. Именно шестая его версия умеет преобразовывать PDF-файл в свой рабочий пакет, содержащий программно "отсканированные" с разрешением 300 dpi страницы. Есть одно но: если документ имеет нестандартное оформление (много лишних линий, рамочек) или его иллюстрации содержат электрические схемы, графики, диаграммы, то FineReader воспринимает их не как рисунки, а как таблицы и пытается их распознать. В таких случаях приходится вручную переопределять области распознавания и их тип (текст, таблица, рисунок, "определить автоматически"). Зато качество распознавания получается отличное. Некоторые замечания можно предъявить таблицам - зачем было делать фиксированную высоту ячеек, но иначе действительно трудно сохранить внешний вид документа. Итак, покупайте FineReader или качайте его отсюда. Если у Вас триальная версия, то придётся регулярно залазить в реестр и ставить ключику
[HKEY_CURRENT_USER\SOFTWARE\ABBYY\FineReader\6.00\Splash]
значение "Runs"="9999999999". Но лучше купить эту замечательную программу. Чтобы в будущем вышла версия 7.00.
На самом деле FineReader отличная программа! Не знаю как с таблицами (никогда не распознавал тексты с таблицами но форматирование просто здоровски сохраняется! Плюс, что меня очень порадовало, он понимает переносы слов.
Вобщем, рекомендую!
Вобщем, рекомендую!
Нашел!!
ABBYY PDF Transformer
Хорошо преобразовал все таблицы и разметки файла. Хотя есть небольшие недочеты.
Рекомедую всем
http://www.abbyy.ru/pdftransformer/
ABBYY PDF Transformer
Хорошо преобразовал все таблицы и разметки файла. Хотя есть небольшие недочеты.
Рекомедую всем
http://www.abbyy.ru/pdftransformer/
Оставить комментарий
zxcv
Какой программой можно редактировать PDF файл. Либо перевести в формат doc.?