Я разочарован в IT специалистах
Можно на любом языке решать задачу?
Можно на любом языке решать задачу?Я могу качественно оценить только C++ (Windows/Linux C# или Java. Кроме этого я считаю, что нет смысла оценивать языки или виртуальные машины с GIL.
раз уж троллить, то начнем
Денег-то сколько?
Денег-то сколько?
то есть например можно решать на OpenMP ?
ну ок, кидай текст задачи
ну ок, кидай текст задачи
то есть например можно решать на OpenMP ?Для этой задачи есть готовые решения, нет смысла решать её без использования примитивов. Грубо говоря, если тебя просят пример реализации std::vector, нет смысла присылать класс, который делегирует все методы к std::vector
Давай.
Мне всегда казалось, что необходимость писать многопоточный код возникает намного раньше, чем понимание важности алгоритмической сложности.мне кажется, что наоборот: сначала оттачивают решение стандартных алгоритмических задач (стеки, списки и тд а далее распараллеливают либо уходят в асинхронщину, лок(вейт)-фри, особенности архитектур (это вообще другая стихия) и тд
кидай задачку, зарядка для ума всегда приветствуется
что то я не понял о чем ты. я писал много поточные проги только на OpenMP , поэтому мне стало интересно о чем тут речь..
я писал много поточные проги только на OpenMP , поэтому мне стало интересно о чем тут речьМеня интересует, как это работает, а не как можно использовать готовое решение.
Меня интересует, как это работает, а не как можно использовать готовое решение.Блок-схему нарисовать надо?
сначала оттачивают решение стандартных алгоритмических задач (стеки, списки и тд а далее распараллеливаютВ моей практике требования "чтобы GUI не подвисал во время записи в БД" появились намного раньше, чем "чтобы можно было обрабатывать 10.000 подключений по сокету" или "отчёт за год должен строиться не более чем за 1 минуту". И, честно говоря, алгоритмическая подготовка страдает у меня до сих пор.
Блок-схему нарисовать надо?Достаточно написать код на примитивах.
а чем плохо использовать готовое решение, если оно попадает скажем в разрешенные фреймворки?
а чем плохо использовать готовое решение, если оно попадает скажем в разрешенные фреймворки?Во-первых, это не имеет никакого практического смысла во время оценки твоих знаний. Во-вторых, реальные задачи могут с лёгкостью отступить от готового решения, причём небольшое отступление может привести к катастрофическим последствиям как в рамках алгоритмической сложности, так и в рамках параллелизма и масштабируемости.
не очень понятно, зачем вы попусту трёте щас. запостил бы задачу...
не очень понятно, зачем вы попусту трёте щас. запостил бы задачу...Я же написал, почему не хочу постить. Могу прислать тебе в приват. Кстати, я предлагаю выслать моё решение вперёд, до того, как ты сделаешь своё.
не, я решать не хочу.
не, я решать не хочу.Тогда почему ты думаешь, что трём попусту? Сейчас интересно с кем-то порешать, задачка в принципе несложная и достаточно интересная. А потом уже можно выложить своё решение сюда. Если кто-то ещё захочет, то выложит своё. Тогда и приходи троллить.

Тогда почему ты думаешь, что трём попусту?потому что трёте попусту. =)
- а вот у меня есть задачка, но я вам её не покажу
- а почему не покажешь?
- а потому что у вас документов нету!
- как же это нету? усы и хвост мои документы!
- нет, это не документы.
итд
потому что трёте попусту. =)Всегда проще кого-нибудь затроллить, чем что-то сделать. Поэтому мне кажется, что трут попусту те, кому слабо выполнить практическое решение, но очень хочется сказать что-нибудь умное. Я пообещал позже выложить условие задачи и своё решение, поэтому не до конца понимаю, к чему относится твой отзыв: с одной стороны тебя интересует задача, с другой стороны ты не собирался её решать.
Я пообещал позже выложить условие задачи и своё решение, поэтому не до конца понимаю, к чему относится твой отзыв: с одной стороны тебя интересует задача, с другой стороны ты не собирался её решать.Можешь к своему разочаровательному посту дописать что IT-специалисты и читают-то с трудом

Требовалось написать многопоточный код с достаточно простой алгоритмической частью.есть тренд: "не писать многопоточный код. если вы пишите многопоточный код, значит вы делаете что-то неправильно".
причем, чем лучше специалист, и чем больше он написал кода, тем он сильнее убеждается в верности этого утверждения.
следование этому тренду приводит к тому, что либо код переформулируется так, чтобы не было проблем многопоточного взаимодействия, либо они были минимальны, либо решались библиотекой (или однажды написанной заготовкой). в итоге, очень редкий программист действительно пишет сложную многопоточку с кучей эффектов для production-а
и получается, что своей задачей ты оцениваешь какую-то странную характеристику, которая в реальной работе и не встречается, чем-то это мне напоминают работодателей, которые оценивают программистов по правильности ответа, чему будет равно i в выражении, аля "i=i=3-i+++++i";...
если у вас есть действительная потребность писать многопоточный код, тогда стоит принять, что это не совпадает с "рынком". и что такому навыку оптимальнее обучать по месту, а не искать готовых специалистов
Всегда проще кого-нибудь затроллить, чем что-то сделать. Поэтому мне кажется, что трут попусту те, кому слабо выполнить практическое решение, но очень хочется сказать что-нибудь умное. Я пообещал позже выложить условие задачи и своё решение, поэтому не до конца понимаю, к чему относится твой отзыв: с одной стороны тебя интересует задача, с другой стороны ты не собирался её решать.блин. ты чего такой недобрый? белены объелся?

я просто заметил, что мне ваша переписка с хулио показалась бессмысленной. задача твоя мне неинтересна, я просто отметил, что по-моему стоило бы сразу выложить ее текст, чтобы избежать переливания из пустого в порожнее. просто высказал свое мнение на этот счёт. никого я не пытался троллить и не собираюсь этого делать. вот мне заняться больше нечем, только сидеть и троллить в разделе девелопмент.
В моей практике требования "чтобы GUI не подвисал во время записи в БД" появились намного раньшетвоя практика нестандартна, так что не надо удивляться, что у других она другая
по-моему стоило бы сразу выложить ее текст, чтобы избежать переливания из пустого в порожнееОн вполне нормально объяснил почему этого не сделал.
да, я сейчас шёл из магазина и подумал, что наверное он это сделал, чтобы решал каждый по отдельности, чтобы это не превратилось в коллективный разум или типа того. и, перечитав пост, увидел там вроде бы эту мысль. хотя сначала её не увидел. =)
твоя практика нестандартна, так что не надо удивляться, что у других она другаяА я считаю, что нестандартна коммерческая практика, когда люди занимаются алгоритмической подготовкой до инженерной. А вот в теории (при обучении программированию) всё как раз наоборот.
есть тренд: "не писать многопоточный код. если вы пишите многопоточный код, значит вы делаете что-то неправильно".Этот тренд есть только среди тупых фанатов Microsoft. У них есть ещё много разных трендов, и все они предназначены для выбивания денег. Поскольку решения, написанные быдлокодерами, не способны работать без покупки дорогостоящего софта, Microsoft-у и другим крупным компаниям очень и очень выгодно плодить людей с точкой зрения, подобной твоей. Кстати, средний уровень Java разработчиков, которых я прособеседовал за последние пол года, на порядки выше уровня .NET разработчиков. Мало того, абсолютно бесполезное мясо встречается как раз при наличии в резюме только технологий от Microsoft.
причем, чем лучше специалист, и чем больше он написал кода, тем он сильнее убеждается в верности этого утверждения.Я всё время убеждаюсь в обратном: подход "я использую только готовое" остаётся красивым только в туториалах.
и получается, что своей задачей ты оцениваешь какую-то странную характеристику, которая в реальной работе и не встречается
Мне эта характеристика встречается чуть ли каждую неделю.
что мешает выложить задачу сразу, а ответы принимать в приват?
если кому-то захочется насрать и выложить решение, то он это и так сделает (да и задачу тоже выложит до кучи)
так что я лично вижу только одну причину: иметь список тех, кто возьмется за решение. Нафига это надо я хз, может, злорадствовать потом над теми, кто ниасилит
если кому-то захочется насрать и выложить решение, то он это и так сделает (да и задачу тоже выложит до кучи)
так что я лично вижу только одну причину: иметь список тех, кто возьмется за решение. Нафига это надо я хз, может, злорадствовать потом над теми, кто ниасилит
Этот тренд есть только среди тупых фанатов MicrosoftА можешь хотя бы примерно сказать где и зачем вам нужна многопоточность? Т.е. Даркгрей вроде разумно говорит. И вроде как при больших нагрузках и больших объемах данных многопоточность скорее вредна, чем полезна.
А я считаю, что нестандартна коммерческая практика, когда люди занимаются алгоритмической подготовкой до инженерной.
при чем тут твой пример с ГУИ-то? я вот за все время работы не написал ни одного толстого ГУИ, и одна мысль о его написании мне противна

что мешает выложить задачу сразу, а ответы принимать в приват?
Ты хочешь её решить или нет?
так что я лично вижу только одну причину: иметь список тех, кто возьмется за решение. Нафига это надо я хз, может, злорадствовать потом над теми, кто ниасилитНикакой теории заговора нет.
Этот тренд есть только среди тупых фанатов Microsoft.хм, мне вот всегда казалось наоборот - МС как и его фанаты просто обожают треды
2Но: он же сказал, шобы гуй не фризился.
А можешь хотя бы примерно сказать где и зачем вам нужна многопоточность? Т.е. Даркгрей вроде разумно говорит. И вроде как при больших нагрузках и больших объемах данных многопоточность скорее вредна, чем полезна.Нам она нужна везде: от клиентских приложений до серверной части.
при чем тут твой пример с ГУИ-то? я вот за все время работы не написал ни одного толстого ГУИ, и одна мысль о его написании мне противнаПример с GUI потому и называется "примером".
Ты хочешь её решить или нет?
если она интересная и там нет гуи
и если раньше не кончится пиво и не захочется спать (да-да, одни отмазки
)хотя я не большой спец в многопоточности (one more excuse)
Этот тренд есть только среди тупых фанатов Microsoft.тебя в детстве покусал Билл Гейтс, и у тебя осталась травма?
python и ruby тоже написал микрософт, и поэтому там даже сам язык имеет проблемы с многопоточкой?
например, почти весь веб (что на сервере, что на клиенте) работает без необходимости написания ручной многопоточки, а на этом рынке у микрософта не очень большая доля.
на телефонах вон даже от многопроцессности отказываются, а ты говоришь многопоточка...
У них есть ещё много разных трендов, и все они предназначены для выбивания денег.как-то сложно понять, как именно microsoft на многопоточке зарабатывает деньги, если средства упрощающие это - предоставляются бесплатно.
тогда уж скорее intel за этой тенденцией стоит. они в основном платные инструменты для многопоточки предоставляют
> Я всё время убеждаюсь в обратном: подход "я использую только готовое" остаётся красивым только в туториалах.
согласен, в реальной практике используется другой подход: "я использую, в основном, готовое, и только те вещи, которые критичны, и на которых я хочу специализироваться - я пишу сам"
Нам она нужна везде: от клиентских приложений до серверной части.и в чем критичная необходимость везде в рукопашную писать многопоточку? почему не хватает готовой многопоточной базы, готового многопоточного веб-сервера и однажды написанного многопоточного каркаса для клиента?
и в чем критичная необходимость везде в рукопашную писать многопоточку? почему не хватает готовой многопоточной базы, готового многопоточного веб-сервера и однажды написанного многопоточного каркаса для клиента?Потому что нет готовых средств для реализации качественных программ хотя бы средней сложности.
тебя в детстве покусал Билл Гейтс, и у тебя осталась травма?Тебя в детстве покусал Билл Гейтс и теперь при полнолунии ты превращаешься в щуплого очкарика?
Потому что нет готовых средств для реализации качественных программ хотя бы средней сложности.Ты старательно избегаешь конкретики.
хм, мне вот всегда казалось наоборот - МС как и его фанаты просто обожают тредыMicrosoft обожает быстрый порог вхождения. Это приводит к тому, что быдлокодеры плодятся с большой скоростью. Зато растут прибыли у Microsoft-а.
python и ruby тоже написал микрософт, и поэтому там даже сам язык имеет проблемы с многопоточкой?А ещё есть фреймворки и библиотеки типа Qt, Gtk, libev, которые вместо потоков все используют event-loop. В отдельные треды, как правило, выносят исключительно низкоуровневые синхронные вызовы, которые действительно могут завесить интерфейс.
например, почти весь веб (что на сервере, что на клиенте) работает без необходимости написания ручной многопоточки, а на этом рынке у микрософта не очень большая доля.
на телефонах вон даже от многопроцессности отказываются, а ты говоришь многопоточка...
Кстати, мне тоже интересно, что же это за задача, с которой всё началось.
Потому что нет готовых средств для реализации качественных программ хотя бы средней сложности.качественным по каким критериям?
зы
и ты настолько самонадеян, что считаешь, что сможешь всё написать качественнее рынка и это поддерживать с помощью одной своей команды?
ззы
практика показывает, что качественнее рынка можно написать лишь по одному двум-критериям в небольшой(средней) нише (по остальным критериям будет хуже, и с трудом дотягивать до среднего по рынку а бизнес-опыт подсказывает, что это лучше тратить только на то, что действительно дает конкурентное преимущество, и что можно монетизировать.
и соответственно, я плохо понимаю на каких задачах ручная тотальная многопоточка может дать сильное конкурентное преимущество.
Кстати, мне тоже интересно, что же это за задача, с которой всё началось.Главное, чем это закончилось. Вообще, когда я пишу в этом разделе я совершенно не представляю, чем это может закончиться. Теперь тут кто-то начал доказывать, что многопоточность вообще не нужна. Самое интересное, напиши я, что задачка была алгоритмической, мне бы точно так же сейчас втирали, что на хуй никому не всралось знание, есть ли в .NET дерево или нет. В итоге можно было бы придти к выводу, что весь софт уже давно написан, а программисты на хуй никому не нужны.
Главное, чем это закончилось. Вообще, когда я пишу в этом разделе я совершенно не представляю, чем это может закончиться. Теперь тут кто-то начал доказывать, что многопоточность вообще не нужна. Самое интересное, напиши я, что задачка была алгоритмической, мне бы точно так же сейчас втирали, что на хуй никому не всралось знание, есть ли в .NET дерево или нет. В итоге можно было бы придти к выводу, что весь софт уже давно написан, а программисты на хуй никому не нужны.Так ты задачу пришли-то.
Ну, я не буду рассказывать условие задачи целиком, но тем не менее постараюсь побыть тем мудаком, который всё испортил.
Задача заключается в том чтобы написать некий аналог некого жабовского FixedThreadPool (интернеты сказали мне, что это выполняльщик задач в потоках). Т.е., всё требование к многопоточности заключается в жажде многопоточности.
Особенно мне понравилось загадочное последнее требование:
Задача заключается в том чтобы написать некий аналог некого жабовского FixedThreadPool (интернеты сказали мне, что это выполняльщик задач в потоках). Т.е., всё требование к многопоточности заключается в жажде многопоточности.
Особенно мне понравилось загадочное последнее требование:
* Будет плюсом, если учесть, что данное решение может работать внутри серверной части.Решение напишу утром, а то спать хочется.
ну лично мне изначально показалось странным, что ты хочешь на собеседовании давать задачку где писать идеальное решение час( с учетом того, что ты его знаешь, а человек его будет искать и значит затратит сильно больше).
Опять же, оказалось, что ты просишь реализовать класс, который в общем-то есть(это к моим словам "взять готовое решение").
Так базару нет - спросить какието вещи о многопоточности - это ок, особенно если в проекте она используется.
Опять же, оказалось, что ты просишь реализовать класс, который в общем-то есть(это к моим словам "взять готовое решение").
Так базару нет - спросить какието вещи о многопоточности - это ок, особенно если в проекте она используется.
ну лично мне изначально показалось странным, что ты хочешь на собеседовании давать задачку где писать идеальное решение час( с учетом того, что ты его знаешь, а человек его будет искать и значит затратит сильно больше).Задачка не для собеседования, я давал решать её сколько угодно времени на дому.
Задача заключается в том чтобы написать некий аналог некого жабовского FixedThreadPool (интернеты сказали мне, что это выполняльщик задач в потоках). Т.е., всё требование к многопоточности заключается в жажде многопоточности.это случаем не вариация на тему Producer/Consumer http://www.albahari.com/threading/part4.aspx#_Wait_Pulse_Pro...
?
Хотелось бы посмотреть на задачку. Можно в приват. Разглашать не буду)
> Я разочарован в IT специалистах
не моё, сорри если сильно не в тему
не моё, сорри если сильно не в тему
... skip ...
На сайте вижу, что большая часть отчетов в формате XML. Скачать программу, которая может читать отчеты в этом формате можно по ссылке с сайта ФСФР http://www.fcsm.ru/ru/contributors/financialmarket/emitters/...
Называется эта очень нужная софтина «Программа-анкета для ЕЖО эмитентов ФСФР России». ЕЖО в общем. Скачиваешь, ставишь, загружаешь в нее отчет компании. Программа произведена «Интерфаксом». Экспорт из этой проги возможен почему-то только в MS Word. Ни какого тебе Excel или DBF или Access на худой конец. В текстовый файл хотя бы! Так нет.
Поговорил со знакомым программистом о формате XML, после чего обозвал всех программеров мерзавцами в кубе. Потому что нет стандартной проги, которая бы их читала XML по-человечески или конвертировала его во что-то стандартное. Т.е. формат XML создан для поддержания количества рабочих мест для людей, которые называют себя программистами.
...skip ...
Я уважаю топикстартера, но название топика навеяло мне следующий опус:
Одиноко брожу средь толпы я
И не вижу мне равного в ней.
До чего же все люди тупые,
До чего же их всех я умней.
Все другие гораздо тупее,
Нет такого, чтоб равен был мне.
Лишь один себе равен в толпе я.
Лишь один. Да и то не вполне.
Из треда я так и не понял: почему IT специаллист должен уметь писать многопоточный код?
Мне кажется это все равно, что проверять крутость повора по его умению готовить суши.
Мне кажется это все равно, что проверять крутость повора по его умению готовить суши.
Это (про суши) интересное мнение, как всегда вопрос в общем-то в том, что понимать под IT-специалистом, я думаю.
На мой взгляд было бы логично(*) ожидать от программиста базовых знаний по всем темам CS/IT и глубоких в какой-то конкретной области. Так уж повелось, что для того чтобы разобраться в мало-мальски сложной проблеме приходится использовать знания из самых разных областей. Именно поэтому трудно считать специалистом человека, у которого полностью отсутствуют знания хотя бы в одной из областей (включая, очевидно, multi-threading). Примерно того же мнения придерживается, к примеру Стив Йегг, но т.к. у него речь идет о телефонном скрининге, то многопоточность туда не входит.
(*) Что любопытно, это хотя и "логично", но не очень согласуется с реальность - есть постоянный устойчивый спрос на специалистов по xml-программированию (struts/spring/etc которые размножают веб странички копипастом. Другое дело, что работа эта достаточно низкооплачиваема.
На мой взгляд было бы логично(*) ожидать от программиста базовых знаний по всем темам CS/IT и глубоких в какой-то конкретной области. Так уж повелось, что для того чтобы разобраться в мало-мальски сложной проблеме приходится использовать знания из самых разных областей. Именно поэтому трудно считать специалистом человека, у которого полностью отсутствуют знания хотя бы в одной из областей (включая, очевидно, multi-threading). Примерно того же мнения придерживается, к примеру Стив Йегг, но т.к. у него речь идет о телефонном скрининге, то многопоточность туда не входит.
(*) Что любопытно, это хотя и "логично", но не очень согласуется с реальность - есть постоянный устойчивый спрос на специалистов по xml-программированию (struts/spring/etc которые размножают веб странички копипастом. Другое дело, что работа эта достаточно низкооплачиваема.
почему IT специаллист должен уметь писать многопоточный код?Ну вот например есть сервер на C++ с пулом рабочих потоков (worker в которых выполняются обработчики тех или иных запросов. И вот приходит такой "специалист", не знающий что такое многопоточность, зато знающий что компиляция регулярного выражения может выполняться долго. Ну и засовывает класс для регэкспов на уровень файла с ключевым словом static. Типа чтоб один раз скомпилилось, а потом везде использовалось. И всё было бы отлично, если бы этим классом был например pcrecpp::RE (он thread-safe). Но ведь нет, выносят свой класс-обёртку, которая внутри имеет какой-нибудь буфер, и потому уже конечно не thread safe.
Пришли плиз условие в приват....
и мне
Ну вот например есть сервер на C++ с пулом рабочих потоков (worker в которых выполняются обработчики тех или иных запросов. И вот приходит такой "специалист", не знающий что такое многопоточность, зато знающий что компиляция регулярного выражения может выполняться долго. Ну и засовывает класс для регэкспов на уровень файла с ключевым словом static. Типа чтоб один раз скомпилилось, а потом везде использовалось. И всё было бы отлично, если бы этим классом был например pcrecpp::RE (он thread-safe). Но ведь нет, выносят свой класс-обёртку, которая внутри имеет какой-нибудь буфер, и потому уже конечно не thread safe.ВРоде такая ситуёвина может возникнуть только у C++ спеца , а не у IT специалиста в среднем?
Пости уже условие или пришли в приват!
А то обсуждение особенно тупо в результате выглядит: чо-та обуждаете, обсуждаете, часть обсуждающих условие видела, часть не видела, но опознать кто есть кто совершенно невозможно, потому что опытные тролли!
А то обсуждение особенно тупо в результате выглядит: чо-та обуждаете, обсуждаете, часть обсуждающих условие видела, часть не видела, но опознать кто есть кто совершенно невозможно, потому что опытные тролли!
Подтверждаю, что такая ситуация может возникнуть у джава специалиста тоже. Сам согрешил несколько лет назад. За остальных IT-специалистов сказать не могу. А каких именно ты имеешь в виду?
А каких именно ты имеешь в виду?всех кроме JAVA и Сишных
Мне тоже пришли условие пожалуйста.
Многопоточность-хреноточность, важно то, за что деньги платят. Поэтому метод консультанта может быть лучше всего - осваивается много бабла и результат гарантирован . Ну сэкономишь ты фирме 500 тысяч, чего толку-то, тебя похвалят и будешь дальше кодить.
и мне тоже пришли плз
и мне
напоминаю, что для отправки личных сообщений существует фича под названием "отправить личное сообщение"
а что вы все так подорвались? Майк что ли денег дает правильно решившему?
Ребята, зачем вам задача, если вы не будете её решать? Отослал уже раз 20, а решили только два человека. Подождите, мы всё доделаем и выложим условие на форуме, вместе с тремя своими решениями и оценками работы на разных машинах.
напоминаю, что для отправки личных сообщений существует фича под названием "отправить личное сообщение" (с)
ммм... прости, а они обязаны?
Ну лично я тоже был несколько разочарован задачей. Конечно пилить её до блеска можно долго-долго, добавляя всевозможные хаки, но не во время обеда же, легче уж обсудить возможности и поторговаться чуть позже. А с алгоритмической точки зрения она слабая, я ожидал хотя бы... ммм, ну не знаю чего, граф распараллелить какой-нить (впрочем этого мне и так пока хватает).
(впрочем этого мне и так пока хватает).ммм... прости, а они обязаны?Ты забыл прочитать мой первый пост?
Ну лично я тоже был несколько разочарован задачей.
Разочарован, потому что она слишком простая или слишком сложная?
Конечно пилить её до блеска можно долго-долго, добавляя всевозможные хаки, но не во время обеда же, легче уж обсудить возможности и поторговаться чуть позже.Зачем пилить её до блеска? Главное сделать её правильно, и для этого вовсе необязательно выбирать самый сложный путь, который я тебе описал.
Разочарован, потому что она слишком простая или слишком сложная?Потому что ожидал более необычную задачу, которая раскрыла бы мои знания полнее
Зачем пилить её до блеска? Главное сделать её правильно, и для этого вовсе необязательно выбирать самый сложный путь, который я тебе описал.А ты вилку снизишь
Потому что ожидал более необычную задачу, которая раскрыла бы мои знания полнееЗнания по алгоритмам или по многопоточному программированию?
А ты вилку снизишьЭто тут не при чём. На работе мы предлагали верхнюю границу и за другие знания.
Знания по алгоритмам или по многопоточному программированию?Можно совместить, к примеру попросить сделать хороший параллельный поиск минимального пути между любыми вершинами в графе хранящемся неким особым образом на н процессорах. Там хотя бы с ассимптотикой легче напутать и обсудить можно многое.
ЗЫ а то решение с жуткой ассимптотикой прили всё же плиз.
Можно совместить, к примеру попросить сделать хороший параллельный поиск минимального пути между любыми вершинами в графе хранящемся неким особым образом на н процессорах. Там хотя бы с ассимптотикой легче напутать и обсудить можно многое.Для этого нужно сначала правильно решить более простую задачу, хотя бы с блокировками.
ЗЫ а то решение с жуткой ассимптотикой прили всё же плиз.Как-то неправильно это - присылать чужой код, который прислали мне. Оно получается, если полностью сортировать на каждой итерации.
Для этого нужно сначала правильно решить более простую задачу, хотя бы с блокировками.Вот и отличный способ испугать тех, кто их не знает
у нас новая начальница аналитики точно также ищет сотрудника. то ей не понравилось что нет искорки в глазах, то неразговорчивый, то про личную жизнь на собеседовании что-то ляпнул. Так и ищут до сих пор. 
Дак вот в том то вся и проблема.
Некоторые люди забывают, что им нужен все-таки программист, а не фотомодель.
Ну вот придет к вам скажем на собеседование одноногий программист. Но он круто шарит в теме. Вы что его не возьмете что ли? Ну да будет немного неприятно с ним общаться, но привыкнуть не сложно. Главное что работа будет идти. А может все обернется даже лучше, чем я описываю. Все бывает.
Некоторые люди забывают, что им нужен все-таки программист, а не фотомодель.
Ну вот придет к вам скажем на собеседование одноногий программист. Но он круто шарит в теме. Вы что его не возьмете что ли? Ну да будет немного неприятно с ним общаться, но привыкнуть не сложно. Главное что работа будет идти. А может все обернется даже лучше, чем я описываю. Все бывает.
одноногий
работа будет идти
Но он круто шарит в теме. Вы что его не возьмете что ли?Когда ты круто шаришь в теме, ты сможешь сделать как минимум две вещи: найти в гуголе, как решить задачку, после чего решить её. Если ты не можешь сделать этого за 2-3 дня, то твоё сравнение с фотомоделью малость неуместно.
я взял одну такую машину с винтами на 250 IOPS, поставил на неё один SQL Server Express (бесплатный) и продемонстрировал 1200 запросов в секунду при наличии 2500 одновременных SSL подключений.
Странный ты какой-то. MS говно. Пишут они говно и продают за деньги. Но прогать я буду на С#.
.Не пинайте, если что не так, но я убеждён, что
вся проблема винды с её многопоточностью в том, что там нет нормального fork'a.
Нельзя запустить 800 процессов(может даже на 20 тачках которые все слушают один порт.
Нужно делать один процесс с кучей потоков. В одном потоке слушать сокет, потом передавать в другой и там с ним работать.
плюс ко всему, особо треды не попараллелишь. Дальше одного компа не уйти, т.к. вся фича в общей памяти. А на одном компе всё равно возникают проблемы с доступом к памяти от нескольких процессов.
Поэтому не очень понятна вот эти прыгалки вокруг тредов. Из параллельных приложений, треды самые дешёвые, да.
Но по сути, это перенос параллельности на уровень процессоров-памяти.
А память в общем-то самое узкое место.
Так что пользуясь тредами, ты делаешь то же, против чего бастуешь. Использует "готовые" решения от Intel/AMD/etc, вместо того, чтобы полностью разделить паралельные инструкции.
А здесь(в тредах) уже нужно знать, что там реально за комп, на котором будет всё крутиться и писать под него. Хорошая работа для гения. ужасная для бизнеса.
Зачем писать мегапрогу на тредах для суперкомпа, если можно написать чуть посложнее IPC-прогу, поставить 1 дешёвый комп, а по мере выростания нагрузки просто доставлять дешёвые компы?
А серьёзное приложение на тредах - это геморой для отладки. Это означает жуткую поддержку в будущем. Нежелание вносить какие-либо изменения, пусть уж так работает. И смерть проекта в будущем.
IPC-прогу можно покрыть тестами и дальше развивать. Подключать новый людей и т.д.
Даже если она и с динамической типизацией.
Собственно поэтому в языках c GIL и сделали этот GIL. Потому как и с ним неплохо.
Нельзя запустить 800 процессов(может даже на 20 тачках которые все слушают один порт.Многопоточность нужна не только для сетевого ввода-вывода. Кроме того, не понятно, какой вывод ты пытаешься из сделать из невозможности на старых версиях Windows слушать один порт несколькими абсолютно независимыми процессами.
Нужно делать один процесс с кучей потоков. В одном потоке слушать сокет, потом передавать в другой и там с ним работать.
плюс ко всему, особо треды не попараллелишь. Дальше одного компа не уйти, т.к. вся фича в общей памяти. А на одном компе всё равно возникают проблемы с доступом к памяти от нескольких процессов.Из наличия многопоточности нельзя сделать вывод об отсутствии горизонтального масштабирования. Наоборот, при отсутствии многопоточности можно сделать вывод об отсутствии вертикального. Ниже есть пояснение, почему вертикальное масштабирование актуально и востребовано.
Но по сути, это перенос параллельности на уровень процессоров-памяти.Во-первых, при использовании механизма "процесс на сокет" ты делаешь абсолютно то же самое. Во-вторых, потоки в любой современной операционной системе могут работать настолько же параллельно, насколько и процессы. В-третьих, самое узкое место - это ввод-вывод, и если использовать решения с одним потоком (даже асинхронный ввод-вывод, скорее всего, можно будет назвать однопоточным только в случае level triggering) на машинах с несколькими ядрами, то это узкое место очень быстро даст о себе знать.
А память в общем-то самое узкое место.
Так что пользуясь тредами, ты делаешь то же, против чего бастуешь. Использует "готовые" решения от Intel/AMD/etc, вместо того, чтобы полностью разделить паралельные инструкции.
А здесь(в тредах) уже нужно знать, что там реально за комп, на котором будет всё крутиться и писать под него. Хорошая работа для гения. ужасная для бизнеса.Нет, не нужно.
Зачем писать мегапрогу на тредах для суперкомпа, если можно написать чуть посложнее IPC-прогу, поставить 1 дешёвый комп, а по мере выростания нагрузки просто доставлять дешёвые компы?Затем, что существует два подхода, для которых уже давно производили расчёты по деньгам. Для Яндекса, Google или других фирм, которые содержат свои собственные дата центры, может быть выгоднее покупать дешёвое железо. Для тех, кто арендует дата центры намного выгоднее покупать дорогостоящее, потому что оно окупает себя при оплате за место и электричество, при чём в течение года. Поэтому тема вертикального масштабирования вполне актуальна и востребована. Кроме всего прочего, я так и не смог понять, почему ты всё время разделяешь способ масштабирования: наличие вертикального не подразумевает отсутствие горизонтального.
А серьёзное приложение на тредах - это геморой для отладки. Это означает жуткую поддержку в будущем. Нежелание вносить какие-либо изменения, пусть уж так работает. И смерть проекта в будущем.Если ты не умеешь решать даже простые задачи, то возможно. Многопроцессное решение не намного легче многопоточного, а даже наоборот, имеет свои проблемы. Причём при наличии готового многопоточного решения никто не запрещает запускать много процессов, даже на разных компьютерах.
IPC-прогу можно покрыть тестами и дальше развивать. Подключать новый людей и т.д.
Даже если она и с динамической типизацией.
Во-первых, при использовании механизма "процесс на сокет" ты делаешь абсолютно то же самое. Во-вторых, потоки в любой современной операционной системе могут работать настолько же параллельно, насколько и процессы.
IPC - много процессов. у каждого своя память. (за исключением случаев оптимизации, когда большая либа в общей памяти после fork'a лежит, но это можно отключать)
MT - один процесс, одна память. Все потоки лезут в одну память. А это конкуренция и ожидание на уровне процессор-память.
А с памятью ничего кроме кэша не придумали. Поэтому не верю, что "настолько же".
Если для тебя это не узкое место, как ты пишешь, То я не понимаю, в чём проблема всё в одном потоке делать вообще или с GIL. разработка и поддержка упрощается в разы.
А то получается все потоки у тебя в IO сидят, то тут и GIL нормально справится.
Вообще, я спорить не буду. Вполне допускаю, что мой взгляд достаточно нубский. суперкластерами я не располагаю.
Давай пример приложения, где необходимы треды. Я перепишу через IPC и сравним.
Если ты не умеешь решать даже простые задачи, то возможно.Судя по
Для тех, кто арендует дата центры намного выгоднее покупать дорогостоящее, потому что оно окупает себя при оплате за место и электричество, при чём в течение года.
Не только я считаю, что проще купить железо в 2 раза мощнее, чем приложение переписать, которое на старом железе почему-то стало тормозить жутко.
Сам ведь приводишь истории, что пришёл консультант и предложил суперкластер. И, если б не твой энтузиазм, его бы и выбрали.
Давай пример приложения, где необходимы треды. Я перепишу через IPC и сравним.на первый взгляд, кажется, что треды хочется, когда есть состояние большого объема, которое необходимо поддерживать и отвечать на основе него.
как пример, можно взять соц. сеть и поддержку графа контактов, и формирование на основе контактов ленты сообщений
давай более конкретно поставим запрос.
Дайте мне приложение на тредах. Я перепишу его на IPC. И посмотрим, на сколько IPC будет медленнее.
Если я напишу тредовое сам, скажут, что я треды готовить не умею
Дайте мне приложение на тредах. Я перепишу его на IPC. И посмотрим, на сколько IPC будет медленнее.
Если я напишу тредовое сам, скажут, что я треды готовить не умею
а чем будет плоха шаредмемори? Скорость доступа?
Чето я теряю thread =)
Я так и не понял в чем сыр бор? К ТС пришло около 30 челов на собеседование, и никто не решил его задачки? Ну как бы что поделать. Люди глупы и ленивы по своей натуре (я не исключение ).
).
А вообще такие случаи сплошь и рядом:
Вон у нас на собеседование народ приходит и 1080 / 1000 считает на калькуляторе, при этом получает свои 80крур в месяц, быдлокодит на пехепе в быдлоконторе и ему до лампочки ваш мультитрединг.
Я так и не понял в чем сыр бор? К ТС пришло около 30 челов на собеседование, и никто не решил его задачки? Ну как бы что поделать. Люди глупы и ленивы по своей натуре (я не исключение
).А вообще такие случаи сплошь и рядом:
Вон у нас на собеседование народ приходит и 1080 / 1000 считает на калькуляторе, при этом получает свои 80крур в месяц, быдлокодит на пехепе в быдлоконторе и ему до лампочки ваш мультитрединг.
а чем будет плоха шаредмемори? Скорость доступа?а в чем тогда отличие от треда? будут нужны те же самые блокировки, но уже межпроцессные (они обычно дороже)
утверждалось то, что процесс лучше тем, что нет разделяемой памяти: а значит не нужно следить за блокировкой памяти, и можно легко перенести на другую машину
а чем будет плоха шаредмемори? Скорость доступа?Шаред мемори хреново скейлить, а так ничем не плоха.
MT - один процесс, одна память. Все потоки лезут в одну память. А это конкуренция и ожидание на уровне процессор-память.Не "все потоки лезут в одну память", а "если все потоки лезут в одну память". То же самое у тебя будет, если тебе понадобится IPC: процессы полезут в socket, pipe, shared memory и так далее. IPC тоже может снижать параллелизм, а не повышать его. А что касается решения распределённых задач, то я ещё раз повторю: многопоточность не означает отсутствие горизонтального масштабирования или SOA.
А с памятью ничего кроме кэша не придумали. Поэтому не верю, что "настолько же".
Если для тебя это не узкое место, как ты пишешь, То я не понимаю, в чём проблема всё в одном потоке делать вообще или с GIL. разработка и поддержка упрощается в разы.Проблем много и они разные, в зависимости от того, говорим мы про GIL или про однопоточную программу.
В случае с однопоточной программой ты, скорее всего, не сможешь использовать полный квант времени, выделенный одному потоку, для решения сразу нескольких задач. Отсутствие общей памяти может быть, наоборот, минусом, а не плюсом: например, мы не сможем сделать простейший кэш и будем вынуждены использовать IPC, что медленнее, чем общая память потоков. Ещё одна проблема: поддержка системы из нескольких потоков, каждый из которых может упасть. В случае многопоточных решений упадёт один процесс, который нужно будет перезапустить; в случае многопроцессных может быть всё что угодно, вплоть до навечно заблокированных мьютексов.
А про проблемы с GIL, даже в случае однопоточных программ, можно почитать в интернете. Думаю, что нет смысла сюда всё это копировать.
А то получается все потоки у тебя в IO сидят, то тут и GIL нормально справится.У меня потоки не сидят в IO; во время IO они используются для других целей.
Давай пример приложения, где необходимы треды. Я перепишу через IPC и сравним.Из простых примеров могу предложить любой десктоп с неблокирующимся во время вызовов на сервер GUI. Я вообще слабо представляю, зачем в этом случае использовать многопроцессное решение, если достаточно двух потоков. Из примеров средней сложности: использовать блокирующий API в асинхронном сервером коде, например, доступ к базе данных с примитивным кэшированием. Из сложных примеров: WEB сервер с edge driven IO, например, nginx или ядро IIS. Edit: я имею в виду Proactor pattern и могу ошибаться с конкретными примерами. Ещё из сложных примеров: рендеринг сцены в 3D игре отдельно от обсчёта состояния игрового мира или вообще распараллеленный рендеринг.
Не только я считаю, что проще купить железо в 2 раза мощнее, чем приложение переписать, которое на старом железе почему-то стало тормозить жутко.
Зависит от того, почему стало тормозить приложение. Со мной рядом сидят коллеги, которые офигевают, по какой причине тормозит 24хъядерный сервак, если у него потребляется только 10% процессоров. Решение с GIL вполне на такое способно, и докупать процессоры туда будет достаточно бессмысленно.
на первый взгляд, кажется, что треды хочется, когда есть состояние большого объема, которое необходимо поддерживать и отвечать на основе него.Всё проще: я думаю, что для написания качественного асинхронного кода под ASP.NET нужны знания по многопоточной тематике в ещё большем объёме, чем требует задачка, которую я давал порешать кандидатам. Иначе ты превратишь этот код в самую худшую из возможных моделей: синхронный код на асинхронном фреймворке.
как пример, можно взять соц. сеть и поддержку графа контактов, и формирование на основе контактов ленты сообщений
Дайте мне приложение на тредах. Я перепишу его на IPC. И посмотрим, на сколько IPC будет медленнее.это задачку надо придумывать...
у меня родилась вот такая искусственная задачка:
есть большой кусок памяти
для обработки поступает набор команд по перетасовыванию этой памяти вида
откуда копировать (начальный индекс, длина куда копировать(начальный индекс
если длина отрицательная, то блок копируется с переворачиванием,
если индекс (куда копировать) < 0, то это означает что блок надо выдать наружу
зы
для того, чтобы не измерять на сколько быстро оптимизировано в разных языках memcpy, можно добавить что при копировании заодно необходимо менять местами четные с нечетными элементы (нулевой копируется на 1, 1 на 0, 2 -> 3, 3 - 2 если длина нечетная, то последний копируется как есть.
Из простых примеров могу предложить любой десктоп с неблокирующимся во время вызовов на сервер GUI.здесь GIL.
nginxРазве там треды не для прикола(для винды) ввели?
здесь GIL.Но потока-то два. А что если после получения данных от сервера десктопу нужно выполнять вычисления, которые занимают 1-2 секунды? Будешь руками освобождать GIL, чтобы получить все озвученные тобой проблемы многопоточности? Или сделаешь два процесса, что, как мне кажется, намного сложнее двух потоков?
эээ, а расскажи, с каких пор у нас нгинкс на тредах вдруг стал?
1-2 сек. на куски по 50-100мс нельзя разбить?
какие ещё проблемы?
for i in range(100000)
{
if (i%1000) == 0
{
gil_unlock
gil_lock
}
}
А в ненавистном питоне, так это вообще автоматом делается.
один поток в селекте, второй выполняется.
Второй проснулся, выполнил там свои малюсенькие операции, принятое положил в память, из памяти взял начал передавать -> опять уснул.
какие ещё проблемы?
for i in range(100000)
{
if (i%1000) == 0
{
gil_unlock
gil_lock
}
}
А в ненавистном питоне, так это вообще автоматом делается.
один поток в селекте, второй выполняется.
Второй проснулся, выполнил там свои малюсенькие операции, принятое положил в память, из памяти взял начал передавать -> опять уснул.
Или сделаешь два процесса, что, как мне кажется, намного сложнее двух потоков?чем?
Хотя в общем случае "запрос-кудато" из гуйя- это классический случай исп потоков.
Но тут есть простейший вопрос - что делать, если ты хочешь отменить операцию?
Заметь, что броузеры стали сейчас выделять говнофлеш в отдельный процесс(что в реальной жизни помогает килять подвисшие флешки)
1-2 сек. на куски по 50-100мс нельзя разбить?т.е. другие потоки будут эти же 50-100мс висеть?
это может быть неприятно, если например при этом в главном потоке крутится анимация, да и любая плавность будет страдать.
Зависит от того, почему стало тормозить приложение. Со мной рядом сидят коллеги, которые офигевают, по какой причине тормозит 24хъядерный сервак, если у него потребляется только 10% процессоров. Решение с GIL вполне на такое способно, и докупать процессоры туда будет достаточно бессмысленно.
Ты все мои аргументы сам озвучиваешь
Там не GIL, а коряво спроектированное мультитредовое приложение. Которое нужно перепроектировать, чтобы избавиться от ненужного ожидания/простоя.
1-2 сек. на куски по 50-100мс нельзя разбить?Проблем нет, но есть более сложное решение без использования потоков. Ты же сам писал, что использование потоков хуже и сложнее, чем однопоточного кода. А теперь начинаешь играть с GIL руками.
какие ещё проблемы?
т.е. другие потоки будут эти же 50-100мс висеть?
какие другие?
есть первый, который постоянно крутится
есть второй, который в селекте и просыпается, чтобы данные принять на 1-2мс.
Ты все мои аргументы сам озвучиваешьТам криво спроектированное приложение с GIL. Но этот аргумент всё равно относился к теме закупки железа, а не к теме многопоточности. Я хотел сказать, что никаких преимуществ при наличии многопроцессной схемы ты не получаешь: её спроектировать как минимум так же сложно, как и многопоточную; да так, что закупка железа тебе не поможет.
Там не GIL, а коряво спроектированное мультитредовое приложение. Которое нужно перепроектировать, чтобы избавиться от ненужного ожидания/простоя.
есть первый, который постоянно крутитсяречь шла про то, что делать, если нужен поток, которые обрабатывает данные 1-2 секунды
есть второй, который в селекте и просыпается, чтобы данные принять на 1-2мс.
в твоем списке я этот поток не вижу
Ты же сам писал, что использование потоков хуже и сложнее, чем однопоточного кода. А теперь начинаешь играть с GIL руками.
Не всегда можно асинхронно в IO сидеть. Есть всякие закрытые либы. Как тут выше отметили, можно и в несколько процессов перейти.
речь шла про то, что делать, если нужен поток, которые обрабатывает данные 1-2 секунды
в твоем списке я этот поток не вижу
это первый. Он постоянно(долго) крутится и обрабатывает данные .
это первый. Он постоянно(долго) крутится и обрабатывает данные .а gui тогда где?
сформулируй задачу, плз.
сначала была задача 2 треда: гуи + запрос куда-то.
потом: местная обработка + запрос куда-то.
давай объединим. сделаем 3 треда: гуи + местная обработка + запрос куда-то.
всё тоже самое. 50-100 уменьшить до 5-10. или сколько там нужно, чтобы gui не лагало. Если сильно тормозить начнёт - то gui в отдельный процесс.
сначала была задача 2 треда: гуи + запрос куда-то.
потом: местная обработка + запрос куда-то.
давай объединим. сделаем 3 треда: гуи + местная обработка + запрос куда-то.
всё тоже самое. 50-100 уменьшить до 5-10. или сколько там нужно, чтобы gui не лагало. Если сильно тормозить начнёт - то gui в отдельный процесс.
эээ, а расскажи, с каких пор у нас нгинкс на тредах вдруг стал?Я честно не в курсе, как работает nginx: использует ли он level triggered или edge triggered. Думаю, что edge triggered, тогда даже при наличии одного рабочего потока его можно считать многопоточным. Но если ты так не считаешь, то давай не будем спорить (можешь считать, что я не прав давай просто рассматривать мой пример как решение задачи по паттерну Proactor.
Хотя в общем случае "запрос-кудато" из гуйя- это классический случай исп потоков.Я её отменяю, например, закрывая сокет или устанавливая событие из другого потока.
Но тут есть простейший вопрос - что делать, если ты хочешь отменить операцию?
Заметь, что броузеры стали сейчас выделять говнофлеш в отдельный процесс(что в реальной жизни помогает килять подвисшие флешки)А я не отрицаю, что при использовании многопроцессной схемы мы не получаем никаких плюсов. Я утверждаю, что она не может полноценно заменить многопоточную, и что в ней есть свои достаточно серьёзные минусы, примеры которых я и пытаюсь приводить.
всё тоже самое. 50-100 уменьшить до 5-10. или сколько там нужно, чтобы gui не лагало. Если сильно тормозить начнёт - то gui в отдельный процесс.Никто не спорит, что задача решается и в многопроцессной или однопоточной архитектуре. Но одним из твоих аргументов была простота реализации и поддержки. В случае двух потоков не нужен IPC для перекидывания результата запроса в GUI, ровно как и нет необходимости разбивать цикл или управлять GIL.
всё тоже самое. 50-100 уменьшить до 5-10. или сколько там нужно, чтобы gui не лагало.тогда вырастит оверхед на переключение потоков, это же как минимум, полная перегрузка всех кэшей процессора каждый раз. что не есть хорошо, если процессор узкое место.
Не всегда можно асинхронно в IO сидеть. Есть всякие закрытые либы. Как тут выше отметили, можно и в несколько процессов перейти.Зачем асинхронно? Мы сейчас ничего не усложняем и сидим в IO синхронно.
В случае двух потоков
Другие мутексы будут. и с ними нужно возиться. Здесь же в основной цикл каждого потока вставить Unlock;lock и всё.
сидим в IO синхронно.
да. это я и имел ввиду
Другие мутексы будут. и с ними нужно возиться. Здесь же в основной цикл каждого потока вставить Unlock;lock и всё.Вообще-то мьютекса не будет, но даже если его куда-то засунуть, то нет никакой разницы: точно так же "вставить" lock/unlock.
да. это я и имел ввидуЧто именно ты имел в виду? Ты хотел написать так?
Не всегда можно синхронно в IO сидеть. Есть всякие закрытые либы. Как тут выше отметили, можно и в несколько процессов перейти.
Вообще-то мьютекса не будет
Тогда они ничего общего не юзают? Тогда их в разные процессы.
точно так же "вставить" lock/unlock.
Т.е. GIL не сложнее.
значит вот эта мысль неверна:
ровно как и нет необходимости разбивать цикл или управлять GIL
Про GIL и простоту я имел ввиду прежде всего в контексте языков/реализаций, которые поддерживают GIL без дополнительных усилий.
Не всегда можно асинхронно в IO сидеть. Есть всякие закрытые либы.
я имел ввиду, что синхронно можно везде сидеть и мы рассматриваем этот вариант.
Если бы можно было сидеть ассинхронно, то можно было всё в одном потоке написать и всё бы шустро работало.
Тогда они ничего общего не юзают? Тогда их в разные процессы.Что для реализации хуже и сложнее двух потоков. Потому что в случае потоков результат вызова и обсчёта передаётся в GUI в одну-две строки кода на C#.
Т.е. GIL не сложнее.GIL как раз сложнее: даже если есть мьютекс, то его не надо периодически разлочивать. И не надо разбивать логику обсчёта на части, чтобы отдать время GUI.
значит вот эта мысль неверна:
Про GIL и простоту я имел ввиду прежде всего в контексте языков/реализаций, которые поддерживают GIL без дополнительных усилий.Ты определись, ты решаешь задачу с GIL или с IPC? Пока что оба случая у тебя получились сложнее двух потоков.
я имел ввиду, что синхронно можно везде сидеть и мы рассматриваем этот вариант.Хорошо, тогда ещё раз читай моё сообщение:
Если бы можно было сидеть ассинхронно, то можно было всё в одном потоке написать и всё бы шустро работало.
Проблем нет, но есть более сложное решение без использования потоков. Ты же сам писал, что использование потоков хуже и сложнее, чем использование однопоточного кода. А теперь начинаешь играть с GIL руками.
твои мутексы зашиты в c#-либу.
мой GIL зашит в cpython.
Так что усложнения я не вижу.
Но. Если в твоём случае, нужно будет использовать какую-то внутреннюю структуру, то тебе в ней придётся юзать мутексы или делать lock(myobject) { }
в моём случае по-прежнему ничего такого делать не нужно.
Даже если реализовывать GIL на C++/QT к примеру. То GIL один раз вставил в основной цикл каждого потока и готово.
мой GIL зашит в cpython.
Так что усложнения я не вижу.
Но. Если в твоём случае, нужно будет использовать какую-то внутреннюю структуру, то тебе в ней придётся юзать мутексы или делать lock(myobject) { }
в моём случае по-прежнему ничего такого делать не нужно.
Даже если реализовывать GIL на C++/QT к примеру. То GIL один раз вставил в основной цикл каждого потока и готово.
твои мутексы зашиты в c#-либу.Мне не нужно ничего разлочивать руками, мне не нужно разбивать циклы. До сих пор не видишь усложнения?
мой GIL зашит в cpython.
Так что усложнения я не вижу.
Но. Если в твоём случае, нужно будет использовать какую-то внутреннюю структуру, то тебе в ней придётся юзать мутексы или делать lock(myobject) { }Лично я обхожусь без lock как на сервере, так и на клиенте. Но даже если нужно будет один раз не в цикле что-то залочить, то это сделать намного проще, чем разбить цикл на куски, повставлять в него lock/unlock для GIL, и получить вообще фиг знает что при наращивании функциональности.
тогда вырастит оверхед на переключение потоков, это же как минимум, полная перегрузка всех кэшей процессора каждый раз. что не есть хорошо, если процессор узкое место.
если процессор один, переключение будет и так, и так.
Если несколько, то что им мешает параллельно крутиться?
Несколько по-уродски конечно, но если всё свободно-то.
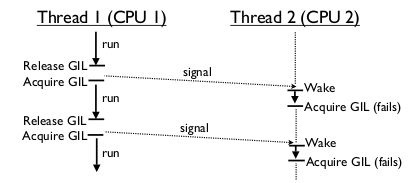
>Если несколько, то что им мешает параллельно крутиться?
а кто данные между потоками синхронизировать будет, у нас же GIL, а значит никаких кешей внутри одного потока не может быть, разве не так?
а кто данные между потоками синхронизировать будет, у нас же GIL, а значит никаких кешей внутри одного потока не может быть, разве не так?
Мне не нужно ничего разлочивать руками, мне не нужно разбивать циклы. До сих пор не видишь усложнения?
Если использовать только стандартные thread-safe либы, то да, нужно писать так, как "положено".
Я думал, мы говорим о более сложном варианте, где самому хоть что-то нужно писать.
Идея c GIL была в следующем: если уж заниматься локами и отладкой, то для IO-gui приложений вполне можно один раз сделать GIL и потом не заморачиваться.
Я не агитирую за GIL, но он даёт достаточно прозрачное поведение при падении производительстности всего на 10-20%.
Если несколько, то что им мешает параллельно крутиться?захват блокировки на gil приведет к тому, что остальные треды, которые тоже хотят GIL и повисли на этой блокировке освободят процессоры
возможны всякие ухищрения со spinlock-ами, но там возникают оверхеды, когда тредов больше, чем процессоров
см. картинку.
Параллельно- на разных ядрах, без перегрузки кэша для каждого конкретно.
но не в одно и то же время.
Может я гоню. и каждое такое переключение скидывает кэш у ядра. Тогда, да. Это равносильно работе на одном ядре.
Параллельно- на разных ядрах, без перегрузки кэша для каждого конкретно.
но не в одно и то же время.
Может я гоню. и каждое такое переключение скидывает кэш у ядра. Тогда, да. Это равносильно работе на одном ядре.
захват блокировки на gil приведет к тому, что остальные треды, которые тоже хотят GIL и повисли на этой блокировке освободят процессоры
возможны всякие ухищрения со spinlock-ами, но там возникают оверхеды, когда тредов больше, чем процессоров
Убедил.
если процессор один, переключение будет и так, и так.переключений будет меньше, из-за того, что они будут только в тех случаях, когда они действительно нужны.
твой же код с постоянными lock/release, переключает треды намного чаще чем есть такая необходимость.
это же классическая борьба с неопределенностью, пользователь то ли двигает мышку, то ли не двигает.
твое решение со вставкой lock/release необходимо рассчитывать на худший случай: пользователь активно что-то скроллит, и хочет чтобы это было плавно. но при этом lock/release будут происходить с той же частотой, даже если пользователь покурить вышел(или там зачитался, или задумался)
для варианта, когда нет необходимости вставлять лишние lock/release, переключение тредов происходит только когда это действительно необходимо: задача закончила выполнение, поступило еще одно событие от пользователя
Всё проще: я думаю, что для написания качественного асинхронного кода под ASP.NET нужны знания по многопоточной тематике в ещё большем объёме, чем требует задачка, которую я давал порешать кандидатам. Иначе ты превратишь этот код в самую худшую из возможных моделей: синхронный код на асинхронном фреймворке.В каком смысле ты называешь ASP.NET асинхронным фраймворком?
With technologies such as ASP.NET and WCF, you may be unaware that multithreading is even taking place — unless you access shared data (perhaps via static fields) without appropriate locking, running afoul of thread safety.
http://www.albahari.com/threading/#_Passing_Data_to_a_Thread
Shared data, доступ к которым надо синхронизовать, редко встречаются в обычных ASP.NET приложениях.
В каком смысле ты называешь ASP.NET асинхронным фраймворком?Я не называю ASP.NET асинхронным фреймворком. Я говорю про асинхронный код в прямом смысле: в ASP.NET есть возможность его писать.
Shared data, доступ к которым надо синхронизовать, редко встречаются в обычных ASP.NET приложениях.Я не пишу "обычные" (называемые эталоном тормознутости приложения на ASP.NET
Я не называю ASP.NET асинхронным фреймворком.А что ты назвал "асинхронным фреймворком" тут
?
А что ты назвал "асинхронным фреймворком" тутТо, что будет написано под ASP.NET
То, что будет написано под ASP.NETт.е. речь идет о том, что и прикладной код и фрайворк самописные, тогда в твоем посте содержится лишь банальная мысль, что если использовать треды, не зная тредов, то получится плохо. Решил побыть КО?
т.е. речь идет о том, что и прикладной код и фрайворк самописные, тогда в том твоем посте содержится лишь банальная мысль, что если использовать треды, не зная тредов, то получится плохо. Решил побыть КО?В том посте содержится ровно та мысль, которую я туда вложил в рамках дискуссии, которая ведётся в этой теме: не надо выдумывать какие-то сложные модельные задачи ради того, чтобы оправдать знания в области разработки многопоточного кода.
В том посте содержится ровно та мысль, которую я туда вложил в рамках дискуссии, которая ведётся в этой теме: не надо выдумывать какие-то сложные модельные задачи ради того, чтобы оправдать знания в области разработки многопоточного кода.Не надо придумывать модельные? Приведи пример реальной! Думаю, что по ходу этой дискуссии многие уже жаждут услышать требования для реального приложения.
P.S. Если речь идет всё о том же бизнес приложении для , то по тем сведениям, которые ты открыл, это сильно похоже на обычное бизнес приложение. Поэтому отход от стандартной/рекомендуемой стратегии для многопоточности вызывает вопросы и требуется обоснования.
A good strategy is to encapsulate multithreading logic into reusable classes that can be independently examined and tested. The Framework itself offers many higher-level threading constructs, which we cover later.
http://www.albahari.com/threading/#_Threadings_Uses_and_Misu...
То же самое озвучивал в постах выше.
Не надо придумывать модельные? Приведи пример реальной! Думаю, что по ходу этой дискуссии многие уже жаждут услышать требования для реального приложения.А что ты думаешь тут обсуждали в нескольких десятках сообщений? Изучи тему, в ней приведены достаточно реальные примеры, не вижу смысла делать персональную выжимку для ленивых.
Поэтому отход от стандартной/рекомендуемой стратегии для многопоточности вызывает вопросы и требуется обоснования.Какая стратегия многопоточности является стандартной и в каком стандарте она описана? Какая стратегия является рекомендуемой и кем, кроме тебя, она рекомендована?
А что ты думаешь тут обсуждали в нескольких десятках сообщений? Изучи тему, в ней приведены достаточно реальные примеры, не вижу смысла делать персональную выжимку для ленивых.Пока я увидел лишь, как тебе говорили, что бизнесу это не нужно/не выгодно, а ты оставлял это без ответа.
Какая стратегия многопоточности является стандартной и в каком стандарте она описана? Какая стратегия является рекомендуемой и кем, кроме тебя, она рекомендована?
Я ж специально привел цитату из достаточно популярной книги по многопоточности.
Пока я увидел лишь, как тебе говорили, что бизнесу это не нужно/не выгодно, а ты оставлял это без ответа.Значит, ты прочитал только часть сообщений, а не всю тему. Не вижу смысла возвращаться к троллингу, на который ты малость опоздал.
Я ж специально привел цитату из достаточно популярной книги по многопоточности.По этой цитате я не могу понять, какая стратегия является стандартной и в каком стандарте она описана. И не могу понять, какая модель является рекомедованной, а так же почему и кем она рекомендована.
По этой цитате я не могу понять, какая стратегия является стандартной и в каком стандарте она описана. И не могу понять, какая модель является рекомедованной, а так же почему и кем она рекомендована.Ты не понимаешь "to encapsulate multithreading logic into reusable classes that can be independently examined and tested"? Ты не понимаешь, что multithreading желательно отделить от реализации функциональных бизнес требований? Ты не понимаешь, что смесь multithreading-а с реализацией функциональных бизнес требований хуже развивается и сопровождается?
Вообще говоря соглашусь с мыслью, что чаще всего имеет смысл использовать именно стандартное API по причине того, что тогда приложение сможет улучшаться по мере развития стандартного фреймворка без непосредственных разработчиков (пример: в Java дописали нативную реализачию этого метода с чёрной магией для каждого вида процессоров, в результате чего стандартная реализация обогнала реализацию, над которой мучались 2 месяца).
Ты не понимаешь "to encapsulate multithreading logic into reusable classes that can be independently examined and tested"? Ты не понимаешь, что multithreading желательно отделить от реализации функциональных бизнес требований? Ты не понимаешь, что смесь multithreading-а с реализацией функциональных бизнес требований хуже развивается и сопровождается?Я не понимал ровно того, о чём написал: какая стратегия является стандартной и в каком стандарте она описана; какая модель является рекомедованной, а так же почему и кем она рекомендована. Теперь я ещё не понимаю, как ты умудрился придти к смеси многопоточности и функциональных требований, которые вообще рядом не стояли.
Вообще говоря соглашусь с мыслью, что чаще всего имеет смысл использовать именно стандартное API по причине того, что тогда приложение сможет улучшаться по мере развития стандартного фреймворка без непосредственных разработчиковНикто не говорит о том, что не нужно использовать стандартное API. Но если ты делаешь ошибки в реализации простых задач, то из этого можно сделать вывод, что ты не сможешь правильно и оптимально использовать готовые решения. Возможно, этот вывод следует не столько из факта наличия ошибок, сколько из характера этих ошибок.
Например, каждая из этих ошибок может говорить о разном уровне понимания устройства многопоточных программ: ошибочное использование событий без паттерна Monitor, синхронизация с помощью Thread.Sleep неверная трактовка атомарности записи в volatile поля.
Теперь я ещё не понимаю, как ты умудрился придти к смеси многопоточности и функциональных требований, которые вообще рядом не стояли.Раз не стояли рядом, значит, ты их тоже разделяешь. Тем самым, ты следуешь той стратегии, которую не понимаешь. Ок
. Тогда почему ты так близко к сердцу принял то, что многие плохо знают многопоточность? Народ занят на реализации бизнес требований, мало кому достается реализовать модуль обслуживающий multithreading. Это же такое простое объяснение тому, что ты наблюдаешь, почему у тебя такая реакция?Например, каждая из этих ошибок может говорить о разном уровне понимания устройства многопоточных программ: ошибочное использование событий без паттерна Monitor, синхронизация с помощью Thread.Sleep неверная трактовка атомарности записи в volatile поля.с этим не спорю, я уже включился в дискуссию о смысле собственной реализации многопоточных паттернов.
Раз не стояли рядом, значит, ты их тоже разделяешь. Тем самым, ты следуешь той стратегии, которую не понимаешь. Ок .Ты приписал меня к какой-то неизвестной стратегии, которую ты назвал "стандартной". Ок.
Народ занят на реализации бизнес требований, мало кому достается реализовать модуль обслуживающий multithreading. Это же такое простое объяснение тому, что ты наблюдаешь, почему у тебя такая реакция?Ответ на этот вопрос я уже описал в данной теме.
с этим не спорю, я уже включился в дискуссию о смысле собственной реализации многопоточных паттернов.Не все многопоточные паттерны реализованы, и не все они реализованы приемлемо. Особенно если мы ведём речь о .NET
Я немного опоздал к обсуждению GIL, но вот вам ссылка (надеюсь все любители GIL с ней уже знакомы): http://www.dabeaz.com/python/GIL.pdf
По ссылке рассказывают о том какие пиздецы в плане производительности можно словить в питоне, и какое понимание многопоточности требуется чтобы в них разобраться.
По ссылке рассказывают о том какие пиздецы в плане производительности можно словить в питоне, и какое понимание многопоточности требуется чтобы в них разобраться.
Чтобы уйти от GILa можно юзать stackless python. Серваки EVE Online так и делают
По ссылке рассказывают о том какие пиздецы в плане производительности можно словить в питоне, и какое понимание многопоточности требуется чтобы в них разобраться.Обожемой! Если захотеть, то плохо работающую программу можно написать даже на Питоне!
собственно, как и ожидалось, задачу широкой общественности зажали.
потому как иначе IT-специалисты могут разочароваться в майке
А ему кто-нибудь кроме меня решение прислал?
Чтобы уйти от GILa можно юзать stackless python. Серваки EVE Online так и делают
Bottom line: Code written in Stackless Python can only execute as fast as your fastest CPU core can go. A 4 or 8 CPU big-iron server will burn up a single CPU and leave the others idle, unless we span more nodes to harness the other CPUs, which works well for a lot of the logic in EVE which is stateless or only mildly reliant on shared state but presents challenges in logic which is heavily reliant on shared state, such as space simulation and walking around space stations.
CarbonIO is the natural evolution of StacklessIO. Under the hood, it is a completely new engine, written from scratch with one overriding goal tattooed on its forehead: marshal network traffic off the GIL and allow any c++ code to do the same. That second part is the big deal, and it took the better part of a year to make it happen.Резюмировать можно так: ребята написали свой движок на Си++, чтобы избавиться от тормознутого решения на питоне хотя бы в рамках IO. Логика игры до сих пор пашет под GIL и, судя по отзывам игроков, до сих пор дико лагает при наличии 50-100 кораблей в одном месте.
А ему кто-нибудь кроме меня решение прислал?Прислали много, я даже забыл посмотреть на некоторые решения. Пока что продолжаю обсуждать что к чему в приватах.
Вот кстати спасибо за хороший пример кривых рук к тезису "многопоточность скорее вредна при больших нагрузках" :-)
Вот кстати спасибо за хороший пример кривых рук к тезису "многопоточность скорее вредна при больших нагрузках" :-)Пожалуйста, только это хороший пример кривых рук при разработке платформы и кривых рук при выборе платформы.
Пожалуйста, только это хороший пример кривых рук при разработке платформы и кривых рук при выборе платформы.Кривыми руками вообще лучше писать на дотнете.
Кривыми руками вообще лучше писать на дотнете.Кривыми руками вообще лучше ничего не писать. Тем более язык программирования.
Кривыми руками вообще лучше ничего не писать. Тем более язык программирования.Дотнет это вроде не язык?
Я ж тебе говорю: ты привел пример когда кучка идиотов открыла для себя "вдруг" что многопоточность на питоне — зло и героически писала для этого костыль. Ну и чо, разочаровываться в IT-специалистах можно и в этом треде, не лазая в гугль и интернет.
Ты как будто тред не читал, в самом начале все это уже обсуждали.
Дотнет это вроде не язык?Зато Python - это язык.
Я ж тебе говорю: ты привел пример когда кучка идиотов открыла для себя "вдруг" что многопоточность на питоне — зло и героически писала для этого костыль.Так ты про это, или про то, что "многопоточность скорее вредна при больших нагрузках"? Если про первое, то я согласен, Python не подходит для больших нагрузок, которые создают MMORPG. Хотя в данном случае, Python с новым модулем IO не может потянуть и 100 игроков, которые находятся рядом друг с другом.
Если про первое, то я согласен, Python не подходит для больших нагрузок, которые создают MMORPG.Еще разок для тупых: для больших нагрузок не подходит многопоточность
Хотя в данном случае, Python с новым модулем IO не может потянуть и 100 игроков, которые находятся рядом друг с другом.
Еще раз: если многопоточных дебилов гнать тряпками, то оказывается что проблема не в Python. Наше решение этой задачки в тесте (на локацию загоняютя роботы и шныряют туда-сюда и проверяют что не лагают) показывает 100000 клиентов на сервер и упирается в ширину канала. На практике пока сказать не готов, к сожалению, естественно цифры будут хуже.
Еще разок для тупых: для больших нагрузок не подходит многопоточностьЕщё разок для тупых: если ты ограничен чем-то типа CPython, то да, не подходит. В других случаях - подходит, читай тему внимательно.
Наше решение этой задачки в тесте (на локацию загоняютя роботы и шныряют туда-сюда и проверяют что не лагают) показывает 100000 клиентов на сервер и упирается в ширину канала.Конечно, в то как время реальное решение этой задачки, не в тесте, одной из лучших компаний - разработчиков MMORPG, показывает 5000 клиентов на сервер. А я думал, что на Python нельзя программировать, если не умеешь писать тесты правильно.
Конечно, в то как время реальное решение этой задачки, не в тесте, одной из лучших компаний - разработчиков MMORPG, показывает 5000 клиентов на сервер. А я думал, что на Python нельзя программировать, если не умеешь писать тесты правильно.У них игра гораздо сложнее, думай верхней головой.
И тебе _Ss_ сказал русским языком что они в своей MMORPG от многопоточности отказываются везде где только можно.
У них игра гораздо сложнее, думай верхней головой.Да, кому-то явно нужно думать верхней головой. Я пишу про игру: "в данном случае, Python с новым модулем IO не может потянуть и 100 игроков, которые находятся рядом друг с другом". А ты отвечаешь, что ваше решение этой задачки в тесте показывает 100000 клиентов на сервер.
А. ок. Логично понимать что вряд ли мы делаем такую же игру
Что самое смешное — свою задачку ты так и не смог сформулировать, пока только привел примеры когда многопоточные приложения делать было не надо
Логично понимать что вряд ли мы делаем такую же игруЛогично было бы упомянуть, что вы решаете другую задачу, тогда бы я не стал спорить.
Что самое смешное — свою задачку ты так и не смог сформулировать, пока только привел примеры когда многопоточные приложения делать было не надоЧто самое смешное - ты продолжаешь спорить, не прочитав тему.
Логично было бы упомянуть, что вы решаете другую задачу, тогда бы я не стал спорить.Ты говорил про MMORPG. Я тебе привел пример про MMORPG.
Ты говорил про MMORPG. Я тебе привел пример про MMORPG.Я говорил про конкретную ситуацию в MMORPG, или ты читаешь только одно слово из сообщения, прежде чем броситься отвечать?
Что самое смешное - ты продолжаешь спорить, не прочитав тему.
Я говорил про конкретную ситуацию в MMORPG, или ты читаешь только одно слово из сообщения, прежде чем броситься отвечать?Ситуацию обсудили уже: нехрен было делать многопоточную фиговину.
Ты по сути скажешь что-нибудь или слился в сторону поливания питона грязью?
_Ss_ не на питоне ни разу пишет, у них Java и делают MMORPG. Так что остынь насчет GIL .
Вообще когда вы с серьезным видом тут начинаете message loop обсуждать — печалька, я все ждал когда ты свою хитрую задачку сформулируешь где многопоточность нужна, а вы какие-то детские проблемы обсуждаете.
Видимо хитрой задачки у тебя нет, есть только кривые руки
Ситуацию обсудили уже: нехрен было делать многопоточную фиговину.Уточняй: нехрен было делать многопоточную фиговину на Python.
Ты по сути скажешь что-нибудь или слился в сторону поливания питона грязью?По сути уже много раз сказал, но ты просто отказываешься почитать тему. У меня нет желания делать для тебя выжимку, ты всё равно пропустишь её мимо ушей и опять будешь требовать какой-то неизвестной сути.
_Ss_ не на питоне ни разу пишет, у них Java и делают MMORPG. Так что остынь насчет GIL.Не могу понять, при чём тут _Ss_, его проект и его мнение. Попытка уйти от многопоточности - это одно, грамотное использование - это другое, модельные задачи - это третье. Когда я прошёл собеседование в Аллоды и получил предложение, мне рассказывали про проект много интересных вещей, и у меня сложилось другое мнение на счёт использования в нём многопоточности. А ещё сказали, что они хотят стереть упоминание Java из текста вакансии на серверную часть.
Вообще когда вы с серьезным видом тут начинаете message loop обсуждать — печалька, я все ждал когда ты свою хитрую задачку сформулируешь где многопоточность нужна, а вы какие-то детские проблемы обсуждаете.Как я упоминал ранее, ты видишь только свои посты, а мнение и аргументы других людей пропускаешь мимо ушей. Я несколько раз написал, что моя задачка - простая, для проверки знаний, и не рассматривается как доказательство необходимости использовать многопоточные решения.
Видимо хитрой задачки у тебя нет, есть только кривые рукиВидимо способности к аргументации у тебя нет, есть только кривая способность оскорблять других людей.
Оставить комментарий
kokoc88
Недавно я искал разработчиков к себе в команду. Из-за того, что стал больше сомневаться в специалистах, придумал задачку, которую давал до или после собеседования. Требовалось написать многопоточный код с достаточно простой алгоритмической частью. Идеальное (по моим меркам) решение задачки можно написать примерно за 1 час, оно укладывается в 200-300 строк кода брутто.Из более чем 30-ти присланных мне решений менее половины были сделаны приемлемо алгоритмически. Правильный многопоточный код не написали ни разу, и всего три решения могли бы хоть как-то работать в production. Надо сказать, что такого результата я совсем не ожидал. Мне всегда казалось, что необходимость писать многопоточный код возникает намного раньше, чем понимание важности алгоритмической сложности.
Вот сижу и думаю, а будут ли среди Development желающие решить мою задачку? Может быть, порешаем её в приватах с качественным feedback в обе стороны? А своё решение я обязательно выложу в открытый доступ, пусть это и активизирует троллей.