А как вы боретесь с deadlock-ами?
мы юзаем оракл и живем не парясь 
А можно поподробнее?
Что-то я не пойму, каким образом использование какой-нибудь СУБД магически избавит ваше приложение, с которым одновременно работает дохуя клиентов, от дедлоков.
Что-то я не пойму, каким образом использование какой-нибудь СУБД магически избавит ваше приложение, с которым одновременно работает дохуя клиентов, от дедлоков.
1) Долго думаем перед тем, как писать код
2) Внимательно изучаем логи. У вменяемых БД по ним все можно выяснить.
2) Внимательно изучаем логи. У вменяемых БД по ним все можно выяснить.
может я чего не понимаю
приведи пример дедлока
приведи пример дедлока
Долго думаем перед тем, как писать кодМетод AAA класса BBB выполняет запрос к таблице xxx (если больше запросов к ней в этой транзакции не было - она залочится сейчас) и зовёт метод CCC объекта класса DDD. Он, в свою очередь, при выполнении какого-то условия, позовёт метод EEE класса FFF. А ещё этот метод EEE класса FFF может быть вызван методом GGG класса HHH. Метод EEE класса FFF иногда зовёт метод III класса JJJ - а там выполняется запрос к таблице yyy.
И ты никак не можешь сказать, что в такой-то транзакции мы лочим сначала таблицу xxx, а потом - yyy, ты этого просто не знаешь.
2) Внимательно изучаем логи. У вменяемых БД по ним все можно выяснить.Даже самая вменяемая БД не знает больше того, что ей скажут.
Пусть в логи пишется абсолютно всё - и ты узнаешь, какие именно запросы были в тех двух транзакциях, которые организовали дедлок. Что дальше? Как искать нужное место в коде?
Классический пример - в одной транзакции, при обработке какого-то запроса пользователя, выполняется запрос к таблице X, а затем - к таблице Y. В другой, при обработке другого запроса другого пользователя - выполняется запрос к таблице Y, и только потом - к таблице X.
При неудачном стечении обстоятельств может оказаться так, что первая транзакция успела залочить таблицу X, а вторая - таблицу Y (под сильной нагрузкой, когда одновременно идёт куча транзакций - такое очень даже реально). Результат - первая транзакция будет ждать, пока вторая не освободит Y, а вторая - пока первая не освободит X.
В реальности, СУБД убьёт одну из этих транзакций - но, во-первых, только через некоторое время; а во-вторых - у нас в этой транзакции всё сдохло, и это довольно неприятно.
При неудачном стечении обстоятельств может оказаться так, что первая транзакция успела залочить таблицу X, а вторая - таблицу Y (под сильной нагрузкой, когда одновременно идёт куча транзакций - такое очень даже реально). Результат - первая транзакция будет ждать, пока вторая не освободит Y, а вторая - пока первая не освободит X.
В реальности, СУБД убьёт одну из этих транзакций - но, во-первых, только через некоторое время; а во-вторых - у нас в этой транзакции всё сдохло, и это довольно неприятно.
я попроще пример приведу
транзакция 1:
транзакция 2:
ну найти последовательность запросов - уже полдела. grep в помощь и вперед по сырцам.
транзакция 1:
update tbl set foo = foo + 1 where bar = 1;
update tbl set foo = foo - 1 where bar = 2;
транзакция 2:
update tbl set foo = foo + 1 where bar = 2;
update tbl set foo = foo - 1 where bar = 1;
ну найти последовательность запросов - уже полдела. grep в помощь и вперед по сырцам.
ну найти последовательность запросов - уже полдела. grep в помощь и вперед по сырцам.Ты видишь, что конфликтуют запросы вроде:
select * from "Accounts" where "Id" = ?
и
select * from "Emails" where "AccountId" = ?
Нагрепав по сырцам (точнее, не нагрепав, а догадавшись - потому что приличные люди голый SQL не пишут ты узнаёшь, что эти запросы берутся из CAccount::loadById и EmailSelector::selectByAccount(CAccount). А эти методы зовутся, соответственно, первый - в тысяче мест, а второй - только в сотне.
Дальнейшие действия?
Ну во-первых, далеко не все СУБД накладывают блокировки на таблицу целиком (я так понимаю у вас MySQL, где для популярных storage engine действительно блокируется таблица целиком). Например MS SQL Server, DB2 используют более мелко гранулированные блокировки, на уровне записей, страниц. Правда обычно есть механизм lock escalation, который при определенном критическом количестве мелкогранулярных блокировок заменяет их на более грубые, чтобы не было перерасхода ресурсов (памяти). И еще не все СУБД используют блокировки как единственный механизм для изоляции транзакций. Например Orable, Firebird, частично MS SQL Server 2005 используют кроме блокировок механизм версий записей.
сорри, не прочитал первую часть, думал не мне
ну вот это к вопросу о том, что надо сначала думать, а потом писать. но если не получается, то залочить сразу все, что надо - фигово, но надо выбирать - либо быстро писать код, либо писать быстрое приложение
ну вот это к вопросу о том, что надо сначала думать, а потом писать. но если не получается, то залочить сразу все, что надо - фигово, но надо выбирать - либо быстро писать код, либо писать быстрое приложение
во-первых, я вижу, что две транзакции вошли в деадлок и вижу что в этих транзакций делалось. дальше найти это место в коде гораздо легче
я так понимаю у вас MySQLНеправильно понимаешь.
Тем не менее, при ловле дедлоков легче считать, что блокируется вся таблица - ничего лишнего не пропустишь, зато, может, поймаешь что-то лишнее, что в обычной жизни не приведёт к дедлоку, но всё равно сделано нехорошо.
И еще не все СУБД используют блокировки как единственный механизм для изоляции транзакций. Например Orable, Firebird, частично MS SQL Server 2005 используют кроме блокировок механизм версий записей.И что?
Механизм версий, афаик, помогает в том случае, когда кто-то пытается заселектить без блокировки ту запись, которая уже заблокирована в другой транзакции - и тогда его не заставят ждать, а отдадут старую версию.
Как это поможет в случае с запросами:
update table "A" set "SomeField" = ? where "Id" = ?
update table "B" set "SomeField" = ? where "Id" = ?
и
update table "B" set "SomeField" = ? where "Id" = ?
update table "A" set "SomeField" = ? where "Id" = ?
? (с одинаковыми Id, конечно).
я привел пример дедлока для rowlevel locks. и, кстати, в этом простейшм случае версионность тоже не поможет
и вижу что в этих транзакций делалось. дальше найти это место в коде гораздо легчеПохоже, у вас очень простой и линейный код.
Метод AAA класса BBB выполняет запрос к таблице xxx (если больше запросов к ней в этой транзакции не было - она залочится сейчас) и зовёт метод CCC объекта класса DDD. Он, в свою очередь, при выполнении какого-то условия, позовёт метод EEE класса FFF. А ещё этот метод EEE класса FFF может быть вызван методом GGG класса HHH. Метод EEE класса FFF иногда зовёт метод III класса JJJ - а там выполняется запрос к таблице yyy.Если эти все методы просто отрабатывают без участия пользователя, то это обычно короткие транзакции, и даже при больших нагрузках дедлоков мало.
И ты никак не можешь сказать, что в такой-то транзакции мы лочим сначала таблицу xxx, а потом - yyy, ты этого просто не знаешь.
залочить сразу все, что надоСверху мы не знаем о том, что понадобится снизу.
Так что залочить можно либо только то, что требуется на этом уровне (и тогда появляются дедлоки либо сразу всё (и тогда наступает полный превед, потому что мы можем обслужить только один запрос за раз).
Я понимаю, что версионность не панацея, но по моему на версионнике все равно сложнее получить дедлок, вот что я хочу сказать. А проще всего, когда локи всегда уровня таблицы.
Например Orable, Firebird, частично MS SQL Server 2005да, но этот механизм не обеспечивает полной изоляции

Да, я и не хочу сказать, что обеспечивает, см отмазки в предыдущем посте.
тогда я не понял вопроса. если вопрос "Как отловить дедлок, т.е. найти последовательнось действий, которые к нему приводят", то я ответил. Если вопрос в том, что "есть код, который приводит к дедлокам и что с ним делать", то я тоже ответил - думать!
Если эти все методы просто отрабатывают без участия пользователяКонечно.
то это обычно короткие транзакции, и даже при больших нагрузках дедлоков мало.Судя по моему опыту - необязательно мало.
Если вопрос в том, что "есть код, который приводит к дедлокам и что с ним делать", то я тоже ответил - думать!Это не ответ, а отмазка.
Судя по моему опыту - необязательно мало.видимо, действительно, проблема в том что MySQL лочит крупными кусками. Мы проводили небольшое нагрузочное тестирование, дедлоков получили менее 2%, в реальности еще меньше. База под MSSQL2005.
ок.
1) попытаться узнать заранее, что лочить, пусть и путем небольшого оверхеда. лишний селект никого не убьет
2) использовать локи помягче, тот же rowlevel, что бы дать возможность другим что-то делать.
на самом деле надо реальный случай, иначе всегда можно придумать ситуацию, когда будет жопа.
1) попытаться узнать заранее, что лочить, пусть и путем небольшого оверхеда. лишний селект никого не убьет
2) использовать локи помягче, тот же rowlevel, что бы дать возможность другим что-то делать.
на самом деле надо реальный случай, иначе всегда можно придумать ситуацию, когда будет жопа.
У нас не MySQL
Наверное, у вас либо нагрузка была небольшая, либо код лёгким (т.е. транзакции простыми либо логика - лёгкой и на низкоуровневом языке (т.е. транзакции быстро завершались)...
А при нагрузке даже порядка десяти хитов во время исполнения одной транзакции уже запросто вылезет дедлок на общих ресурсах.
Наверное, у вас либо нагрузка была небольшая, либо код лёгким (т.е. транзакции простыми либо логика - лёгкой и на низкоуровневом языке (т.е. транзакции быстро завершались)...
А при нагрузке даже порядка десяти хитов во время исполнения одной транзакции уже запросто вылезет дедлок на общих ресурсах.
1) попытаться узнать заранее, что лочить, пусть и путем небольшого оверхеда. лишний селект никого не убьетКажется, ты не понял. Я же тут уже приводил пример...
Дело не в том, что мы не знаем, какие именно ряды нужно лочить.
Дело в том, что на высоком уровне мы понятия не имеем, какие таблицы понадобятся тому, что находится на низком уровне.
На высоком уровне мы меняем данные пользователя, и понятия не имеем, что при этом будет запрос к таблице email-ов, потому что пользователю надо отправить уведомление об изменении пароля (и этот запрос будет выполняться не всегда, а только если изменился пароль).
Ну скажи уже, что там у вас, интересно же. PostreSQL ? И приведи конкретный пример, может что-то подскажут люди, а разговоры вообще ничего не дадут, мне кажется.
ваш код долго работает? почему?
И приведи конкретный примерВ смысле - конкретный пример?
может что-то подскажут люди, а разговоры вообще ничего не дадут, мне кажется.Мы эту проблему уже решаем, как - я описал в первом посте.
Было интересно, что с этим делают другие люди.
а у вас язык высокого уровня какой используется?
ваш код долго работает? почему?Потому что делается очень много действий на относительно высокоуровневом языке, с использованием по полной ООП.
Как я уже сказал, долго - это меньше секунды.
а у вас язык высокого уровня какой используется?Видимо, ты редко появляешься в этом разделе

Потому что делается очень много действий на относительно высокоуровневом языке, с использованием по полной ООП.это ни как не может служить оправданием, давай уже говори че он делает, что у вас там в ТЗ прописано?
У нас нет ТЗ 
А что он делает - можешь посмотреть, см.подпись
А что он делает - можешь посмотреть, см.подпись
А что он делает - можешь посмотреть, см.подписьбиллинг для скайлинка?..
Чуть-чуть промахнулся
Не очень въехал во все твои AAA, BBB и т.д.
В Oracle update можно так сделать
У тебя какой-то аналог есть похожий?
В Oracle update можно так сделать
declare
vTmp table%rowType;
begin
begin
select *
into vTmp
from table t
where t.id = ID
for update;
exception
when others then
[действия в случае блокированной записи]
end;
update table
set t.sNAme = sName || '+'
where t.id = ID;
end;
У тебя какой-то аналог есть похожий?
>видимо, действительно, проблема в том что MySQL лочит крупными кусками.
чего вы все на мускуль наговариваете :-\
MyISAM: лочится вся таблица на апдейт, транзакции не поддерживаются
InnoDb: лочится строка, есть транзакции
Falcon: не помню
чего вы все на мускуль наговариваете :-\
MyISAM: лочится вся таблица на апдейт, транзакции не поддерживаются
InnoDb: лочится строка, есть транзакции
Falcon: не помню
У тебя какой-то аналог есть похожий?Я тут не очень понял, что эти строки делают, но, похоже, что ты выбираешь ряд из таблицы с FOR UPDATE, если он залочен - материшься, если нет - обновляешь?
У нас все UPDATE идут после SELECT ... FOR UPDATE, и единственное отличие, выходит - что там, где ты материшься, мы ждём (потому что если падать, когда ряд уже кем-то залочен - вообще ничего работать не будет).
from table t
where t.id = ID
for update;
NOWAIT забыл
 - иначе exception не поднимется и сессия будет ждать пока другая освободит ресурс.
- иначе exception не поднимется и сессия будет ждать пока другая освободит ресурс.Пенартур, ты когда нибудь перерастешь подростковый сленг?
Где-то в обсуждении, ты писал, что вся группа операций по времени ~1 секунда. Как вы так умудрились систему постоить, что такие операции лочат друг друга и не получается выстроить из них очередь...
материшьсяВ блоке явно указано место где должна быть логика в случае блокированной записи. Это может быть как ожидание и последующие несколько попыток, так и что-нибудь еще, а уж потом сообщение пользователю: "Мы пытались выполнить Вашу операцию 5 раз, но данные недоступны. Попробуйте повторить свое действие позже."
Где-то в обсуждении, ты писал, что вся группа операций по времени ~1 секунда. Как вы так умудрились систему постоить, что такие операции лочат друг друга и не получается выстроить из них очередь...
Ага
похоже ловлю постоянные дедлоки в джава-коде при дебаге
ну или дебаггер глючит по страшному, что вряд ли
и тут коллега подсказывает: там же есть кнопочка: Suspend Policy
и там выбор: стопить только текущий поток или стопить всю программу
поменял ее на стопить только тек. процесс и дедлоки прекратились
ну или дебаггер глючит по страшному, что вряд ли
и тут коллега подсказывает: там же есть кнопочка: Suspend Policy
и там выбор: стопить только текущий поток или стопить всю программу
поменял ее на стопить только тек. процесс и дедлоки прекратились
А можно поподробнее?
Что-то я не пойму, каким образом использование какой-нибудь СУБД магически избавит ваше приложение, с которым одновременно работает дохуя клиентов , от дедлоков.
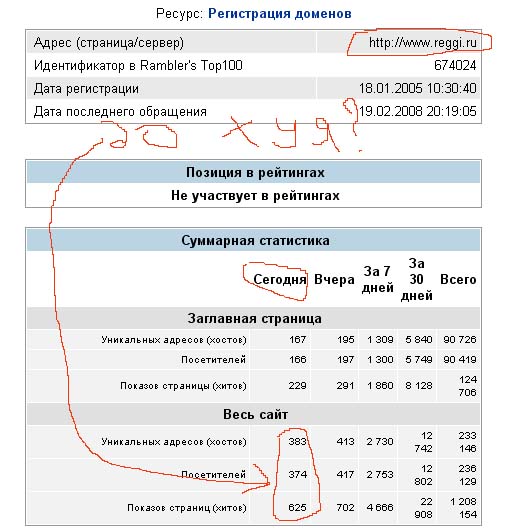
Это не те хиты
Остальные не смогли зайти на сайт из-за проблем с дедлоками, вестимо
а какие тогда те?
1. А в чем великий смысл использования https-протокола при проверке зарегенности домена?
2. Зачем так насиловать собственный сервер? Чем это оправдано? Для чего больше десятка пост-запросов на этой странице?
2. Зачем так насиловать собственный сервер? Чем это оправдано? Для чего больше десятка пост-запросов на этой странице?
так принято похоже http://www.nic.ru/cgi/na.cgi
чтобы никто не подсмотрел, какой ты домен проверяешь и не занял его раньше
чтобы никто не подсмотрел, какой ты домен проверяешь и не занял его раньше
Ted Turner's highly anticipated MyTube™ social network for men is having sizing problems, according to media analysts. The new social networking site is Turner Broadcasting's answer to Oprah Winfrey's highly acclaimed and successful Oxygen television network aimed at young women. Unfortunately, MyTube, which is implemented entirely in Ruby on Rails, is hitting a scaling barrier at peak usage hours, which are reportedly between midnight and 2am PST. An insider at MyTube tells us confidentially that they get up to 100 users before the system slows to a crawl, causing bored users to delete random files from their servers by requesting well-formed URLs like http://mytube.com/database/delete and http://mytube.com/debugger/start. "It's just so rude", MyTube engineers were overheard saying in their Atlanta office. "Some of our users are just plain wankers."
(c) Стиви. Steve Yegge
(c) Стиви. Steve Yegge
а какие тогда те?Те, которые на сайте самой панели. А на нём нет никаких баннеров, так что никакой рамблер статистику не соберёт.
Начиная с сентября 2007, reggi - просто порносайт.
2. Зачем так насиловать собственный сервер? Чем это оправдано? Для чего больше десятка пост-запросов на этой странице?Странно, что у тебя так долго проверялись шесть доменов.
В исходниках JS ведь всё написано
Один из этих запросов - длинный коннект к серверу, где идёт собственно проверка доменов; а остальные - короткие, они выполняются с какой-то периодичностью, и смотрят, не появились ли новые результаты проверки.
Сделано для того, чтобы при проверке сразу пятидесяти имён у пользователя не грузилась бы долго страница, а загрузилась сразу, а в ней постепенно появлялись бы результаты проверки.
Остальные не смогли зайти на сайт из-за проблем с дедлоками, вестимоУж на reggi-то зайти не проблема, там, как можно видеть, вообще практически статика
1. А в чем великий смысл использования https-протокола при проверке зарегенности домена?А у нас не различается проверка зарегенности и какое-нибудь другое действие.
Вся панель работает по https.
Чтобы, например, никто не перехватил пароль.
>>Вся панель работает по https.
>>Чтобы, например, никто не перехватил пароль.
а как у вас с sidejacking`ом?
>>Чтобы, например, никто не перехватил пароль.
а как у вас с sidejacking`ом?
А причём тут оно?
Вся панель работает по https.
Sidejacking, where the attacker uses packet sniffing to read network traffic between two parties to steal the session cookie. Many web sites use SSL encryption for login pages to prevent attackers from seeing the password, but do not use encryption for the rest of the site once authenticated. This allows attackers that can read the network traffic to intercept all the data that is submitted to the server or web pages viewed by the client. Since this data includes the session cookie, it allows him to impersonate the victim, even if the password itself is not compromised.[1] Unsecured Wi-Fi hotspots are particularly vulnerable, as anyone sharing the network will generally be able to read most of the web traffic between other nodes and the access point.
почитай как гмейл к нему уязвим
Дай ссылку.
Вообще, я не понимаю, как можно что-то перехватить, если весь обмен с панелью идёт по https, по http она тупо недоступна.
Вообще, я не понимаю, как можно что-то перехватить, если весь обмен с панелью идёт по https, по http она тупо недоступна.
как происходит идентификация сессии?
cookie.
А cookies передаются внутри HTTP-запроса, который сам - внутри SSL.
А cookies передаются внутри HTTP-запроса, который сам - внутри SSL.
ищи по словам Роберт Грехем (Robert Graham)
Ага, спасибо.
У нас панель не по SSL не работает вообще; и единого центра логина, как у гугля, тоже нет... но вот о флаге secure узнал только сейчас.
fixed, в общем.
У нас панель не по SSL не работает вообще; и единого центра логина, как у гугля, тоже нет... но вот о флаге secure узнал только сейчас.
fixed, в общем.
> Затем натравливаем на получившийся лог анализатор, который строит граф порядка
> блокировки, и после добавления каждой транзакции к графу ищет в нём циклы,
> и если найдёт - матерится. После чего можно понять, в какой из транзакций случилась
> жопа и фиксить, раскатывать, очищать лог и ждать, пока в нём не наберётся опять
> достаточно сведений...
представте меня пожалуйста вашему драгдиллеру
> блокировки, и после добавления каждой транзакции к графу ищет в нём циклы,
> и если найдёт - матерится. После чего можно понять, в какой из транзакций случилась
> жопа и фиксить, раскатывать, очищать лог и ждать, пока в нём не наберётся опять
> достаточно сведений...
представте меня пожалуйста вашему драгдиллеру
Оставить комментарий
kruzer25
А?Мы вот подумали об этом, когда было уже слишком поздно.
В результате, сейчас написали специальный логгер - при запросе к какой-нибудь (за некоторыми исключениями) таблице считаем, что она залочена целиком, и на каждую транзакцию - пишем в лог список залоченных таблиц (в порядке блокировки) и стек вызова начала транзакции.
Затем натравливаем на получившийся лог анализатор, который строит граф порядка блокировки, и после добавления каждой транзакции к графу ищет в нём циклы, и если найдёт - матерится. После чего можно понять, в какой из транзакций случилась жопа и фиксить, раскатывать, очищать лог и ждать, пока в нём не наберётся опять достаточно сведений...