(ЗАКРЫТО) Кодировка содержимого PDF
А тебе зачем?
Если вкратце, то кодировка определяется в Font Dictionary, в котором описываются шрифты. За это отвечает запись Encoding в описании шрифта.
То, как описывется кодировка, зависит от типа шрифта.
Для Type 1, TrueType и Type 3 шрифтов можно указать либо одну из стандартных кодировок (MacRomanEncoding, MacExpertEncoding, WinAnsiEncoding) или указать кодировку, которая описывается в Encoding Dictionary.
Кодировки в этом словаре описываются тремя записями: Type (опционально, должно быть значение "Encoding" BaseEncoding, Differences.
В записи Differences описываются отличия от кодировки, указанной в BaseEncoding (может принимать те же значения, что и запись Encoding при описании шрифта, либо может быть опущена). Формат поля Differences немного различается для разных типов шрифтов. Тут еще есть некоторые тонкости с cmap'ами, которые могут быть описаны в TrueType шрифтах.
Если у нас Type 0 или CIDFont (композитные шрифты для иероглифов то в Encoding шрифта можно записывать либо предопределенный CMap (их довольно много либо CMap, который описан в pdf-файле.
Возвращаясь к твоему вопросу.
У тебя используется шрифт /F1, по-русски это значит, что это один из 14 стандартных Adobe'овских Type 1 шрифтов (конкретно, вроде это должен быть Times Roman который не нужно встраивать в PDF.
Поэтому примером объекта Encoding для для такого шрифта будет
Запись
означает, что символу /guillemotleft из StandardEncoding соответствует код 199, /guillemotright — 200 и т. д.
Таким образом, тебе надо либо сразу вставлять символы в одной из трех базовых кодировок, либо построить нужные тебе записи Differences для определенных кодировок и вставлять эту запись для нужных шрифтов. Описание 3-х стандартных кодировок, которые используются в PDF, описываются в Appendix D PDF Reference.
P. S. Не забывай, что для самого текстового блока используется либо PDFDocEncoding, либо UTF-16BE.
То, как описывется кодировка, зависит от типа шрифта.
Для Type 1, TrueType и Type 3 шрифтов можно указать либо одну из стандартных кодировок (MacRomanEncoding, MacExpertEncoding, WinAnsiEncoding) или указать кодировку, которая описывается в Encoding Dictionary.
Кодировки в этом словаре описываются тремя записями: Type (опционально, должно быть значение "Encoding" BaseEncoding, Differences.
В записи Differences описываются отличия от кодировки, указанной в BaseEncoding (может принимать те же значения, что и запись Encoding при описании шрифта, либо может быть опущена). Формат поля Differences немного различается для разных типов шрифтов. Тут еще есть некоторые тонкости с cmap'ами, которые могут быть описаны в TrueType шрифтах.
Если у нас Type 0 или CIDFont (композитные шрифты для иероглифов то в Encoding шрифта можно записывать либо предопределенный CMap (их довольно много либо CMap, который описан в pdf-файле.
Возвращаясь к твоему вопросу.
У тебя используется шрифт /F1, по-русски это значит, что это один из 14 стандартных Adobe'овских Type 1 шрифтов (конкретно, вроде это должен быть Times Roman который не нужно встраивать в PDF.
Поэтому примером объекта Encoding для для такого шрифта будет
Example 5.9
25 0 obj
<< /Type /Encoding
/Differences
[ 39 /quotesingle
96 /grave
128 /Adieresis /Aring /Ccedilla /Eacute /Ntilde /Odieresis /Udieresis
/aacute /agrave /acircumflex /adieresis /atilde /aring /ccedilla
/eacute /egrave /ecircumflex /edieresis /iacute /igrave /icircumflex
/idieresis /ntilde /oacute /ograve /ocircumflex /odieresis /otilde
/uacute /ugrave /ucircumflex /udieresis /dagger /degree /cent
/sterling /section /bullet /paragraph /germandbls /registered
/copyright /trademark /acute /dieresis
174 /AE /Oslash
177 /plusminus
180 /yen /mu
187 /ordfeminine /ordmasculine
190 /ae /oslash /questiondown /exclamdown /logicalnot
196 /florin
199 /guillemotleft /guillemotright /ellipsis
203 /Agrave /Atilde /Otilde /OE /oe /endash /emdash /quotedblleft
/quotedblright /quoteleft /quoteright /divide
216 /ydieresis /Ydieresis /fraction /currency /guilsinglleft /guilsinglright
/fi /fl /daggerdbl /periodcentered /quotesinglbase /quotedblbase
/perthousand /Acircumflex /Ecircumflex /Aacute /Edieresis /Egrave
/Iacute /Icircumflex /Idieresis /Igrave /Oacute /Ocircumflex
241 /Ograve /Uacute /Ucircumflex /Ugrave /dotlessi /circumflex /tilde
/macron /breve /dotaccent /ring /cedilla /hungarumlaut /ogonek
/caron
]
>>
endobj
Запись
199 /guillemotleft /guillemotright /ellipsis
означает, что символу /guillemotleft из StandardEncoding соответствует код 199, /guillemotright — 200 и т. д.
Таким образом, тебе надо либо сразу вставлять символы в одной из трех базовых кодировок, либо построить нужные тебе записи Differences для определенных кодировок и вставлять эту запись для нужных шрифтов. Описание 3-х стандартных кодировок, которые используются в PDF, описываются в Appendix D PDF Reference.
P. S. Не забывай, что для самого текстового блока используется либо PDFDocEncoding, либо UTF-16BE.
ЗаписьА что значит "символ /guillemotleft" итп?
code:--------------------------------------------------------------------------------
199 /guillemotleft /guillemotright /ellipsis
--------------------------------------------------------------------------------
означает, что символу /guillemotleft из StandardEncoding соответствует код 199, /guillemotright — 200 и т. д.
Таким образом, тебе надо либо сразу вставлять символы в одной из трех базовых кодировокКоторые не поддерживают кириллицу, насколько я понял?
либо построить нужные тебе записи Differences для определенных кодировок и вставлять эту запись для нужных шрифтовА как её строить, для cp-1251, например?
P. S. Не забывай, что для самого текстового блока используется либо PDFDocEncoding, либо UTF-16BE.Я, к сожалению, в самом pdf не разбираюсь, просто хочу понять, что надо изменить, чтобы в вместо этих U показывались буквы "Щ"... а, чтобы посмотреть приложение к pdf reference, надо сначала скачать все тридцать метров этого reference, чего я сделать не могу

Респект! Отец PDF.
Пользуясь случаем, задам вопрос. У меня GNUPlot создает файлы, которые как-то криво отображаются.
Например, вот такой файл (архив, внутри 1.pdf).
При просмотре его с помощью ghostview все нормально:
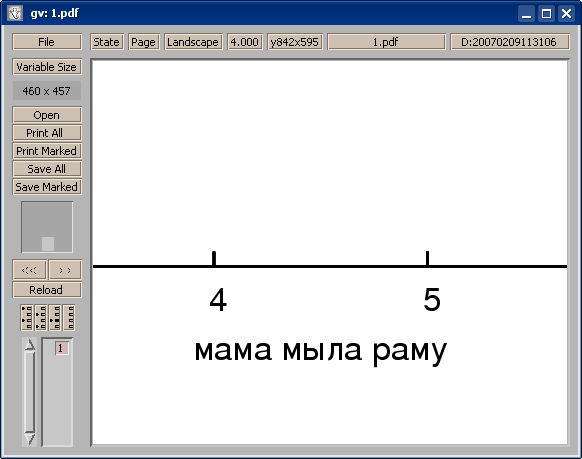
При просмотре его в xpdf буквы склеиваются:
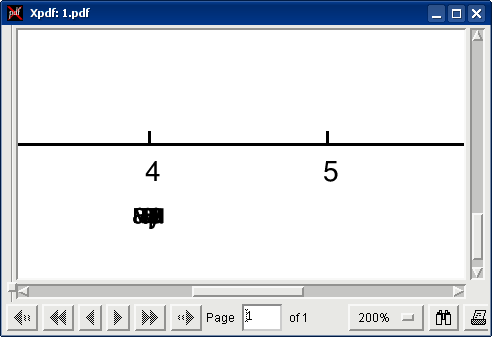
А в Acrobat Reader 7 буквы вообще исчезают:
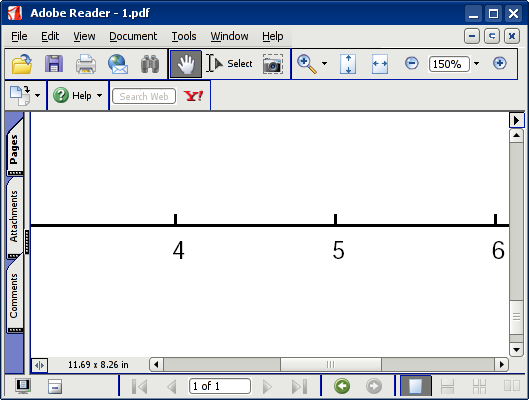
В чем дело? И как это можно исправить?
Пользуясь случаем, задам вопрос. У меня GNUPlot создает файлы, которые как-то криво отображаются.
Например, вот такой файл (архив, внутри 1.pdf).
При просмотре его с помощью ghostview все нормально:
При просмотре его в xpdf буквы склеиваются:
А в Acrobat Reader 7 буквы вообще исчезают:
В чем дело? И как это можно исправить?
А что значит "символ /guillemotleft" итп?Это текстовое название символов, эти названия используются для платформонезависимости PDF. Возможно, их можно посмотреть в каком-то отдельном документе, а не в PDF Reference.
А как её строить, для cp-1251, например?Очень просто. Скачиваем Adobe Standard Cyrillic Font Specification (335 Кб, надеюсь, что осилишь такой трафик берем таблицу cp-1251 и строим Differences. Например, когда я игрался с твоим файликом, я сделал такую Encoding
<<
/Type /Encoding
/BaseEncoding /WinAnsiEncoding
/Differences [217 /afii10043]
>>
Это значит, что символу "Щ" (afii10043) соответствует код 217. Остальные символы можешь дописать сам или попробовать найти готовый pdf-файл в cp-1251 кодировке и выдрать из него.
Возвращаясь к твоему файлу.
1. Оказывается, что кириллические символы из стандартных шрифтов каждый pdf-просмотрщик трактует по-своему. На деле у меня получилось увидеть буквы "Щ" только в Adobe Reader со шрифтами Helvetica и Times-Roman. Остальные просмотрщики (xpdf, kpdf и ghostscript) либо не выводили ничего, либо квадратики.
2. В Adobe Reader у букв "Щ" был неправильный кернинг (межсимвольный интервал). Я точно не знаю, как Adobe Reader выбирает эту информацию для произвольной кодировки, но видимо этой информации для кириллических символов у него нету. Попытка исправить положение с помощью установки в FontDescriptor значения MissingWidth успеха не принесла (файл test_times_width.pdf Adobe Reader заругался, что файл попорчен, т. к. по спецификации для стандартных шрифтов нельзя устанавливать это значение, оно предопределено. Та же самая история с массивом межсимвольных расстояний Widths в описании шрифта.
Так что вывод отсюда такой: стандартные шрифты не годятся, нужно использовать какой-нибудь отдельный кириллический шрифт и встраивать его в pdf-файл.
Тесты, которые я делал, можно взять по ссылке
нужно использовать какой-нибудь отдельный кириллический шрифт и встраивать его в pdf-файлЭто я сделать могу. Тогда, если проделать такие манипуляции, всё будет работать?

по спецификации для стандартных шрифтов нельзя устанавливать это значение, оно предопределеноО, кажется, я начинаю понимать, почему у меня была проблема при генерации pdf-ов в нескольких случаях...
А как оно определяет, стандартный шрифт или нет - по какому-то id или по имени?
То есть, могу ли я после каких-то манипуляций встроить в pdf стандартный times/helvetica/courier?
А как оно определяет, стандартный шрифт или нет - по какому-то id или по имени?Если FontName одно из
Times−Roman, Times−Bold, Times−Italic, Times−BoldItalic,
Helvetica, Helvetica−Bold, Helvetica−Oblique, Helvetica−BoldOblique,
CourierSymbol, Courier−Bold, Courier−Oblique, Courier−BoldOblique,
ZapfDingbats
Symbol
и для этого шрифта не указан его Content (внутри pdf-файла или снаружи то считается, что это один из стандартных шрифтов.
То есть, могу ли я после каких-то манипуляций встроить в pdf стандартный times/helvetica/courier?Можешь.
Пока что не знаю, чем помочь.
Я PDF почти не знаю.
У меня вообще только в Adobe Reader хоть что-то показалось (сжатые русские буквы в остальных случаях все было чисто.
Ты хочешь понять, что происходит на уровне самого PDF или что надо сделать с GNUPlot, чтобы такого не было?
Я PDF почти не знаю.
У меня вообще только в Adobe Reader хоть что-то показалось (сжатые русские буквы в остальных случаях все было чисто.
Ты хочешь понять, что происходит на уровне самого PDF или что надо сделать с GNUPlot, чтобы такого не было?
АЕ! Заработало!
Теперь DOMPDF работает и с русским языком! (Правда, в html-е приходится писать не по-человечески, а через html-entities - буду ковырять domdocument...)
Если кому интересно: (ну и тяжёлые же эти шрифты - целых 400кб в несжатом состоянии!)
Огромное спасибо !
Теперь DOMPDF работает и с русским языком! (Правда, в html-е приходится писать не по-человечески, а через html-entities - буду ковырять domdocument...)
Если кому интересно: (ну и тяжёлые же эти шрифты - целых 400кб в несжатом состоянии!)
Огромное спасибо !
ну и тяжёлые же эти шрифты - целых 400кб в несжатом состоянии!Это потому, что они у тебя много лишних символов из Unicode содержат.
Есть два решения:
1. PDF позволяет хранить не весь шрифт, а только CharSet — в этот набор символов нужно включать только те, что реально используются в pdf-файле.
2. Можно использовать кириллический неюникодный TrueType (раз уж ты его стал использовать) шрифт. Пример такого шрифта
Оставить комментарий
kruzer25
Кто-нибудь знает, как сказать, как в таких блоках:определяется, в какой кодировке надо это выводить на экран?
Сейчас на экране выводится Hello ÙÙÙWorld! (какой-то там ISO а хочется, чтобы acrobat reader понял, что это cp1251 (а лучше - utf-8).
Это где-то в заголовках определяется? Или где?
Просто возможности качать 30метровый refman с офсайта и потом всё это читать нет... мб тут кто знает?