встройте lorien в вашу программу
А снаружи к нему доступ получить можно?
пока не зафайрволлено => можно юзать lorien.s2s.msu.ru:4111
Спасибо 
ты бы лучше самбу пропатчил у себя, чтоб мой комп нормально индексировался :-)
а как фтпшки выделяются?
2: лучче попатч имена своих шар.
2: лучче попатч имена своих шар.
а у меня с именами все в порядке, виндовз их прекрасно видит и заходит
сделал бы как google - запрос в специальном xml и ответ в нем же. А показывай как хочешь
в попу xml там где он не нужен.
запрос выражение - ответ таблица, зачем тут xml?
запрос выражение - ответ таблица, зачем тут xml?
1. парсер не нужен
2. совместимость по версиям лучше
2. совместимость по версиям лучше
ответ таблица, зачем тут xml?Чтобы писать к нему xsl, типа...
>Чтобы писать к нему xsl, типа...
чтоб потом так разогнуть понты?
разогнуть понты?
чтоб потом так
разогнуть понты?да и пора SDK делать
надо привинтить его на z80 =)
>Чтобы писать к нему xsl, типа...Подозреваю, что ты путаешь xsl с dtd.
чтоб потом так разогнуть понты?
 Я прав?
Я прав?Просто потому, что делать всё стандартно - это круто.
сделал дополнительное поле в конце '0' -> smb, '1' -> ftp
простой текстовый файл - более стандартная форма представления информация, чем xml
Как может xml помочь в проблеме версий? Если у меня куда-то исчезло поле, а в xsl на него ссылаются, будут глюки. Если появилось новое поле автоматически оно обрабатываться тоже не станет. Так что все равно надо править xsl.
Большой плюс текстового формата с разделителями '\t' в том, что его можно перенаправлять в другие программы, например писать вещи типа
Большой плюс текстового формата с разделителями '\t' в том, что его можно перенаправлять в другие программы, например писать вещи типа
smbsearch 'SUBSTR "file"'|awk -F '\t' '{print $1;}'}|grep ^172.16.1[678]|xargs smbgetС xml такое конечно тоже можно, но так элегантно не получается.да что ты говоришь? Где-нить можно почитать стандарт простого текстового файла? И каким стандартным образом в нем хранят таблицы?
про csv слышал что-нибудь?
стандартное текстовое представление таблиц
стандартное текстовое представление таблиц
М.б. CSV?
да вот только разделитель в csv не регламентирован... чаще всего - запятая, но не обязательно
Преобразовать xml в csv-таблицу - это простой xslt-запрос вида:
Обратное делается с намного большим геморром.
<xsl:template match="Line"><xsl:apply-templates select="*" mode="Child"/>#0D;</xsl:template>
<xsl:template match="*" mode="Child"><xsl:value-of select="."/>#09;</xsl:template>
Обратное делается с намного большим геморром.
В xml-представлении таблиц не регламентировано тоже много чего.
И даже стандартного способа кодирования бинарных данных нет.
То есть, примерно то же самое, но длиннее, и парсер жирнее.
И даже стандартного способа кодирования бинарных данных нет.
То есть, примерно то же самое, но длиннее, и парсер жирнее.
> В xml-представлении таблиц не регламентировано тоже много чего.
> И даже стандартного способа кодирования бинарных данных нет.
Разве в xsd это не задается?
> И даже стандартного способа кодирования бинарных данных нет.
Разве в xsd это не задается?
прописываешь в XSD как именно у тебя хранятся бинарные данные (hexBinary или base64Binary). Насчет парсера, он обычно уже стоит на компе
имён элементов (аналога символа-разделителя) там нет, выбирай любые имена
есть несколько способов кодирования, опять же, выбирай любые
есть несколько способов кодирования, опять же, выбирай любые
Миллионы веб-девелоперов не могут ошибаться.
отказался даже от HTTP (вот тут я не понимаю, почему какой же тут веб?
Для "почти бинарных" имён файлов я бы предпочёл RFC 2396.
> Для "почти бинарных" имён
для имен?
почему не просто utf8/uft16?
для имен?
почему не просто utf8/uft16?
Потому что в именах бывают всякие странные символы, которые ни в XML, ни в CSV, ни куда либо ещё без эскейпинга не засунешь.
> которые ни в XML, ни куда либо ещё без эскейпинга не засунешь
берешь стандартный xml-генератор и он сам все заэскейпит, а xml-парсер - потом нормально прочитает (уже без эскейпов).
берешь стандартный xml-генератор и он сам все заэскейпит, а xml-парсер - потом нормально прочитает (уже без эскейпов).
а где по язык запросов посмотреть можно?
гугель тоже порт выдает и без http
У стандартного xml-парсера интерфейс понять сложнее, чем написать свой парсер для такой простой таблицы.
А что я делаю не так?
выдает SocketException: No connection could be made because the target machine actively refused it
TcpClient tcpClient = new TcpClient("lorien.local", 41111)
> У стандартного xml-парсера интерфейс понять сложнее, чем написать свой парсер для такой простой таблицы
зачем тебе интерфейс парсера?
юзай или сразу xslt, или xml serializer-ы для своего любимого языка, которые тебе сразу развернут xml в стандартные структуры/массивы твоего любимого языка.
зачем тебе интерфейс парсера?
юзай или сразу xslt, или xml serializer-ы для своего любимого языка, которые тебе сразу развернут xml в стандартные структуры/массивы твоего любимого языка.
в оригинале 3 единицы, а не 4
> гугель тоже порт выдает и без http
google web service (http://api.google.com/search/beta2) через http работает
google web service (http://api.google.com/search/beta2) через http работает
Блин. Точно.
Но на запрос выдает ERROR - не очень информативно
Но на запрос выдает ERROR - не очень информативно
ну, если делать сервис для "больших пацанов", то наверное так и надо
а для простых людей и без xml можно
а для простых людей и без xml можно
описание соотношения между деревом и действительно полезной структурой
вполне сопоставимо по сложности с парсером простого формата (собственно парсер - 2 строчки, дальше - работа с конкретной структурой)
вполне сопоставимо по сложности с парсером простого формата (собственно парсер - 2 строчки, дальше - работа с конкретной структурой)
Но и XML действительно вполне пригоден тут,
несмотря на потерю в читаемости.
несмотря на потерю в читаемости.
Блин. Там подстроку в кавычки врать надо.
А каким там символом в результате перенос строки делается? А то я пихаю в textbox, там вместо переноса на новую строчку квадратик.
А каким там символом в результате перенос строки делается? А то я пихаю в textbox, там вместо переноса на новую строчку квадратик.
>несмотря на потерю в читаемости.
несмотря на отсутствие потребности.
несмотря на отсутствие потребности.
сохрани результат в бинарный файл - да посмотри
Xml бы я в таблицу сразу запихнул, а так нужно результат еще парсить
А есть ограничение на кол-во возвращаемых записей?
У меня запрос SEARCH 0 1000 ALL SUBSTR "music"
Выдает 40-200 записей, хотя находит больше 10000.
У меня запрос SEARCH 0 1000 ALL SUBSTR "music"
Выдает 40-200 записей, хотя находит больше 10000.
А зачем тут может быть полезен HTTP? Идея была сделать что-то а-ля SQL. Он же тоже ходит по своему собственному протоколу.
Пока к сожалению, не успел написать
Общее можно почитать тут http://lorien.local/internals.html
Пиши конкретные вопросы, отвечу.
Общее можно почитать тут http://lorien.local/internals.html
Пиши конкретные вопросы, отвечу.
Уже кто-то что-то делает, это радует
> Блин. Там подстроку в кавычки врать надо.
Сделано по типу SQL. Там пишут SELECT WHERE column = "sample". Здесь примерно также.
> А каким там символом в результате перенос строки делается? А то я пихаю в textbox, там вместо
> переноса на новую строчку квадратик.
? Никаким не делается. Зачем тебе потребовался перенос строки? Посылай одну длинную строчку.
Сделано по типу SQL. Там пишут SELECT WHERE column = "sample". Здесь примерно также.
> А каким там символом в результате перенос строки делается? А то я пихаю в textbox, там вместо
> переноса на новую строчку квадратик.
? Никаким не делается. Зачем тебе потребовался перенос строки? Посылай одну длинную строчку.
Основной минус от XML - невозможность легко его обрабатывать стандартными текстовыми методами типа awk, sed, grep итп. Писать каждый раз приложения, линковать их c xml-либой, или писать xsl слишком долго.
Если это представляет интерес, то можно рядом, например на порту 4112, повесить сервер который выдает то же самое в XML-формате. Тогда скажите какого вида XML вам нужен.
Если это представляет интерес, то можно рядом, например на порту 4112, повесить сервер который выдает то же самое в XML-формате. Тогда скажите какого вида XML вам нужен.
Может ты не все данные из сокета получаешь? Только что проверял - все ок:
[laputa ~]$ while true; do smbsearch -end 1000 'SUBSTR "music"'|wc; done
1003 12369 111174
1003 12369 111174
1003 12369 111174
1003 12369 111174
1003 12369 111174
1003 12369 111174
> Обратное делается с намного большим геморром.
while (<SOCK>) {
split('\t');
}
Где гемор?
while (<SOCK>) {
split('\t');
}
Где гемор?
да, ты прав
посмотри как сделали яндекс или гугель. тебе, наверное, надо несколько проще сделать.
И лучше, наверное, повесить на HTTP всё же.
стандартными ... awk, sed, grep
 А ну если ты _намерено_ ограничиваешь потенциальную аудиторию...
А ну если ты _намерено_ ограничиваешь потенциальную аудиторию... 
> А ну если ты _намерено_ ограничиваешь потенциальную аудиторию...
Какие средства для этих целей применяют в windows-системах? (cygwin не в счет)
Какие средства для этих целей применяют в windows-системах? (cygwin не в счет)
Вот я тебе о том и говорю, что никакие. А xml библиотеки есть естественно, IE умеет xslt делать и т.д.
Огромное спасибо за фичу!
Но вот возник вопрос: что за числа идут между размером и именем компа в ответе?
E.g.:
Но вот возник вопрос: что за числа идут между размером и именем компа в ответе?
E.g.:
(путь) 172.16.38.217/Music/îÅ ÎÁÛÅ/pink floid/The Wall (CD1)/Pink Floyd - 01 - In The Flesh.mp3Плюс, хотелось бы иметь поле - "сеть" (V, Hackers, GZ-V, MSU, ...)
(размер) 3161443
(директория или файл?) 0
(тип - музыка, архив, ...?) 2
(имя компа) A-KOSTYUNCHIK
(статус) online
(ftp или нет) 0
> Но вот возник вопрос: что за числа идут между размером и именем компа в ответе?
сначала is_dir (0 или 1 затем тип файла
MOVIE = 1,
MUSIC = 2,
DOC = 3,
PICTURE = 4,
UNIX_FILE = 5,
CLIP = 6,
CD_IMAGE = 7,
CD_INDEX = 8,
ARCHIVE = 9,
WIN_EXE = 10
> Плюс, хотелось бы иметь поле - "сеть" (V, Hackers, GZ-V, MSU, ...)
Можно сделать конечно, но разве IP недостаточно для этих целей?
сначала is_dir (0 или 1 затем тип файла
MOVIE = 1,
MUSIC = 2,
DOC = 3,
PICTURE = 4,
UNIX_FILE = 5,
CLIP = 6,
CD_IMAGE = 7,
CD_INDEX = 8,
ARCHIVE = 9,
WIN_EXE = 10
> Плюс, хотелось бы иметь поле - "сеть" (V, Hackers, GZ-V, MSU, ...)
Можно сделать конечно, но разве IP недостаточно для этих целей?
> Вот я тебе о том и говорю, что никакие. А xml библиотеки есть естественно, IE умеет xslt делать и т.д.
Вопрос вот какой. Предположим у пользователя под windows есть несколько программ. Одна умеет искать файлы в поисковике, другая умеет делать фильтрацию, третья умеет их скачивать. Каким способом можно их связать, вывод одной пусть на вывод другой? В UNIX для этого используется текстовый формат + pipe. А windows как? Данные передаются через xml и каждый их сначала парсит, обрабатывает, потом в результат в xml? Или как? Что мне нужно куда написать, или тыкнуть мышкой или еще чего-то, чтобы связать программы.
Вопрос вот какой. Предположим у пользователя под windows есть несколько программ. Одна умеет искать файлы в поисковике, другая умеет делать фильтрацию, третья умеет их скачивать. Каким способом можно их связать, вывод одной пусть на вывод другой? В UNIX для этого используется текстовый формат + pipe. А windows как? Данные передаются через xml и каждый их сначала парсит, обрабатывает, потом в результат в xml? Или как? Что мне нужно куда написать, или тыкнуть мышкой или еще чего-то, чтобы связать программы.
> Предположим у пользователя под windows есть несколько программ. Одна умеет искать файлы в поисковике, другая умеет делать фильтрацию, третья умеет их скачивать.
Предположение характерно в основном только для Unix-а.
Под windows-ом скорее будет так: есть несколько библиотек/модулей...
Каким способом можно их связать?
Предположение характерно в основном только для Unix-а.
Под windows-ом скорее будет так: есть несколько библиотек/модулей...
Каким способом можно их связать?
? request
"(SUBSTR \"test\") AND (ISDIR 0)"
? response
"ERROR Invalid query"
что-то не так?
Если пишешь в сокет то посылай полный запрос
SEARCH <min> <max> <HOSTS> <QUERY>
например SEARCH 0 100 ONLINE SUBSTR "test" AND ISDIR 0
SEARCH <min> <max> <HOSTS> <QUERY>
например SEARCH 0 100 ONLINE SUBSTR "test" AND ISDIR 0
> Под windows-ом скорее будет так: есть несколько библиотек/модулей...
Хм. Интересный подход.
Пусть так - вместо программ библиотеки. Все равно, что тогда делать? С помощью какого языка и каких средств я могу делать связки? И как соответственно должны быть написаны компоненты? Предполагается что действие разовое (писать что-то большое ради одного раза неудобно).
Хм. Интересный подход.
Пусть так - вместо программ библиотеки. Все равно, что тогда делать? С помощью какого языка и каких средств я могу делать связки? И как соответственно должны быть написаны компоненты? Предполагается что действие разовое (писать что-то большое ради одного раза неудобно).
так... а теперь что не верно?
? request
"SEARCH 0 100 ONLINE (SUBSTR \"test\") AND (ISDIR 0) AND (RESTYPE 1)"
? response
"ERROR"
С помощью какого языка и каких средств я могу делать связки? И как соответственно должны быть написаны компоненты?Обычно для этого используют технологии COM или .NET, языки - любые
Если сделаешь так, чтобы работало через HTTP и возвращало XML, связать все было бы не проблема
> Предполагается что действие разовое
Мышой перенесёшь из одного окошка в другое.
Мышой перенесёшь из одного окошка в другое.
сорри, ошибся, надо писать RES_TYPE а не RESTYPE
> Обычно для этого используют технологии COM или .NET, языки - любые
Это надо что ли каждый раз программу новую писать? Открывать редактор, писать, компилировать итп. Неужели нет каких-то простых методов типа "туда мышкой тыкнул и туда тыкнул и все"? В UNIX же не надо никаких программ писать, просто делаешь program1|program2.
> Если сделаешь так, чтобы работало через HTTP и возвращало XML, связать все было бы не проблема
Образец результирующего XML? Запрос как получать?
Это надо что ли каждый раз программу новую писать? Открывать редактор, писать, компилировать итп. Неужели нет каких-то простых методов типа "туда мышкой тыкнул и туда тыкнул и все"? В UNIX же не надо никаких программ писать, просто делаешь program1|program2.
> Если сделаешь так, чтобы работало через HTTP и возвращало XML, связать все было бы не проблема
Образец результирующего XML? Запрос как получать?
Запрос наверное пост-запросом отсылать то что сейчас в сокет пихается :
ЗЫ или проще GET-ом будет... http://lorien.local/service.php?from=0&to=100&status=online&query=ONLINE(SUBSTR"test")
А ответ, например, такой:
<html>
<body>
<form name="SEARCH">
<input type="text" name="REQUEST">
</form>
</body>
</html>
ЗЫ или проще GET-ом будет... http://lorien.local/service.php?from=0&to=100&status=online&query=ONLINE(SUBSTR"test")
А ответ, например, такой:
<?xml version="1.0" encoding="utf-8" ?>
<Results found="1">
<Item name="10.0.0.0/share/dir/file.mp3" size="12345" type="2" host="HOST" status="online" isDirectory="false" />
</Results>
Можно вопрос?
Ты этот сервис для чего повесил?
Чтобы ЛЮДИ коннектились через сокет, писали ебанутый запрос, потом читали ответ(для этого "читабельность"? или чтобы сервисом можно было воспользоваться из проги?
Для людей вроде есть веб-интерфейс.
Вообще дискуссия по поводу взаимодействия человек-компьютер, компьютер-компьютер уже была... зачем тут повторять?
Ты этот сервис для чего повесил?
Чтобы ЛЮДИ коннектились через сокет, писали ебанутый запрос, потом читали ответ(для этого "читабельность"? или чтобы сервисом можно было воспользоваться из проги?
Для людей вроде есть веб-интерфейс.
Вообще дискуссия по поводу взаимодействия человек-компьютер, компьютер-компьютер уже была... зачем тут повторять?
> Можно вопрос?
> Ты этот сервис для чего повесил?
Читай внимательно первый тред - там написано. Для автоматизированных поисков. Типа search|grep|xargs smbget.
> Чтобы ЛЮДИ коннектились через сокет, писали ебанутый запрос, потом читали ответ(для этого
> "читабельность"? или чтобы сервисом можно было воспользоваться из проги?
Умные люди любят автоматизировать свой труд. Например, если они выполняют какое-то действие часто написать для него скрипт. Тот же пример с smbsearch|smbget - очень часто встречающаяся задача.
> Для людей вроде есть веб-интерфейс.
Уеб-интерфейс не позволяет в полной мере автоматизировать использование поисковика.
> Ты этот сервис для чего повесил?
Читай внимательно первый тред - там написано. Для автоматизированных поисков. Типа search|grep|xargs smbget.
> Чтобы ЛЮДИ коннектились через сокет, писали ебанутый запрос, потом читали ответ(для этого
> "читабельность"? или чтобы сервисом можно было воспользоваться из проги?
Умные люди любят автоматизировать свой труд. Например, если они выполняют какое-то действие часто написать для него скрипт. Тот же пример с smbsearch|smbget - очень часто встречающаяся задача.
> Для людей вроде есть веб-интерфейс.
Уеб-интерфейс не позволяет в полной мере автоматизировать использование поисковика.
Ок. Попробую сделать в ближайшее время. Не совсем так, но похоже.
> Образец результирующего XML? Запрос как получать?
Правильнее (стандартнее) всего, как web service
Правильнее (стандартнее) всего, как web service
Умные люди любят автоматизировать свой труд. Например, если они выполняют какое-то действие часто написать для него скрипт. Тот же пример с smbsearch|smbget - очень часто встречающаяся задача.Для умных пользователей винды есть JavaScript и VBScript. Он как раз для связки COM-компонент замечательно подходит.
это ему надо спецификацию SOAP рюхать... а вообще да, самое то что надо
!
Что за косяк с кодировками в результатах поиска?
Такое впечатление, что путь идёт KOI-8, а вот имя файла - в WINDOWS-1251!
Что за косяк с кодировками в результатах поиска?
Такое впечатление, что путь идёт KOI-8, а вот имя файла - в WINDOWS-1251!
10.0.0.21/MUSIC/бТЙС/бТЙС - 2001 - иЙНЕТБ/Ария-Штиль.mp (Win-1251)
10.0.0.21/MUSIC/Ария/Ария - 2001 - Химера/юПХЪ-уХЛЕПЮ.mp3 (KOI-8r)
Это файлы такие кривые, походу моя работа
Это один и тот же результат, только разная кодировка (см. пост)
Как файл называется, так и выдается. Если у человека лежат файлы с кривыми названиями - его и спрашивайте
Извиняюсь, не посмотрел
Кстати, откуда такие штуки берутся? Я один раз видел но так и не понял.
Не знаю...
вероятно, когда чел копировал себе, у него неправильно была настроена самба, а потом заломало переименовывать...
Ещё вопросы:
1) В какой кодировке посылать запрос?
2) В какой кодировке приходит ответ?
1) В какой кодировке посылать запрос?
2) В какой кодировке приходит ответ?
В обоих случаях KOI8-R
Итак, на всеобщее растерзание выкладывается первая бета-версия программы,
использующей новую фичу:
Что прога может:
Что прога не умеет:
использующей новую фичу:
Что прога может:
- Формировать запрос к серверу с указанием типа файла, и флага "директория":
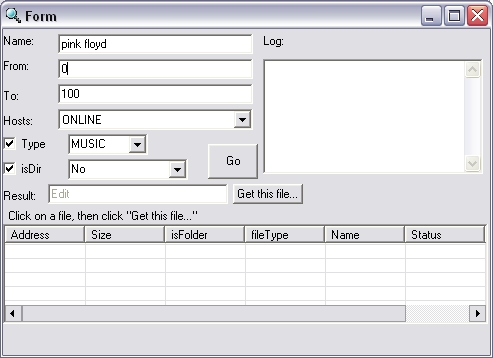
- Обрабатывать ответ сервера на запрос
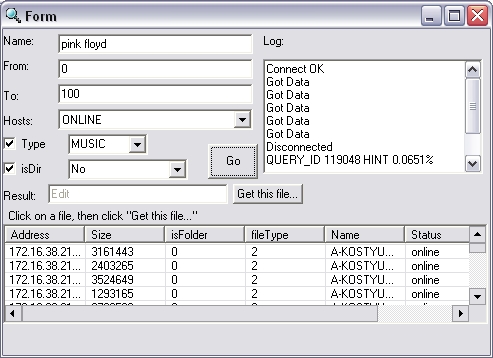
- Сохранять выбранный (из списка результатов) файл на локальный компьютер
Что прога не умеет:
- При сохранении файла не проверяется флаг "директория", последствия скачивания директории непредсказуемы
- Нет фильтрации по имени сети, по размеру
- Нет Path Traverse
- Нет сортировки результатов
- Не тянет большие (~1000 ответов) запросы --- зависает...
Очень интересно! К соажалению под рукой нет винды - могу только посмотреть скриншот.
Как сделать path traverse:
вместо A AND B AND C AND D писать PATHMATCH(A, B, C, D)
Сортировка результатов - SORTORDER дальше набор параметров, по которым сортировать (возможно несколько). Добавить REVERSE если нужно по убыванию.
Искать только в опр. рабочей группе - вместо ALL, ONLINE написать WKG номергруппы (число от 1 до 5).
PS. Вообще посмотри CGI-скрипт, через который идет поиск с web-server-а, - там видно как строится запрос по введеным в HTML-форме параметрам.
PPS. Искать через сервер можно гораздо больше чем можно ввести через web-форму. Например, в web-интерфейсе не поддерживается OR.
Как сделать path traverse:
вместо A AND B AND C AND D писать PATHMATCH(A, B, C, D)
Сортировка результатов - SORTORDER дальше набор параметров, по которым сортировать (возможно несколько). Добавить REVERSE если нужно по убыванию.
Искать только в опр. рабочей группе - вместо ALL, ONLINE написать WKG номергруппы (число от 1 до 5).
PS. Вообще посмотри CGI-скрипт, через который идет поиск с web-server-а, - там видно как строится запрос по введеным в HTML-форме параметрам.
PPS. Искать через сервер можно гораздо больше чем можно ввести через web-форму. Например, в web-интерфейсе не поддерживается OR.
All workgroups in network:
--------------------------------------------------------------------------------
1 GZ-V
2 HACKERS
3 MSU
4 V
когда-то давно было B. оно потом ушло, а wkg_id остались.
Объясни что не так, плз:
REQUEST = SEARCH 0 100 ONLINE (SUBSTR "avi") AND (ISDIR 0) AND (MAXSIZE 717381632) AND (MINSIZE 717381632)
RESPONSE = FULLSCANREQUIRED
По дефолту не дают выполнять запросы, по которым не удается построить индекс (т.к. может занять очень большое время). Нужно специально разрешать. Я сейчас разрешил, попробуй снова.
теперь пашет, сенькс!
качалку файлов сделал под .NET 1.1
консольная прилага: первый параметр - откуда качать, второй - куда записывать. Пока умеет только один файл дергать. Определяет все копии файла, имеющиеся в сети, начинает качать сразу со всех которые нашла... Если коннект отрубается - качает с других компов, появляется новый - начинает качать и с него
консольная прилага: первый параметр - откуда качать, второй - куда записывать. Пока умеет только один файл дергать. Определяет все копии файла, имеющиеся в сети, начинает качать сразу со всех которые нашла...
Если коннект отрубается - качает с других компов, появляется новый - начинает качать и с негоА исходники
гуи - дело десятое
а исходники потом будут, я еще не все доделал, что хотел Можно рефлектором посмотреть
а исходники потом будут, я еще не все доделал, что хотел
Можно рефлектором посмотретьПочему иногда приходит пустой ответ (или это только у меня так, ещё не проверял) ?
У меня только 100-200 первых записей ответа получается получить. Плюс как-то проблемы с кодировкой. Короче хотелось бы глянуть на ту часть, где ты через сокеты с лориеном работаешь.
Это не есть хорошо. Я так тоже пробовал делать, даже когда не было такого сервиса Ты не можешь гарантировать что это будут одни и те же файлы. Хотя для фильмов например это подходит. Но для фильмов лучше интегрировать с films.hackers, так как у фильмов могут быть разные названия.
Ты не можешь гарантировать что это будут одни и те же файлы. Хотя для фильмов например это подходит. Но для фильмов лучше интегрировать с films.hackers, так как у фильмов могут быть разные названия.когда ожидать klorien? 
Всё, разобрался - у меня сокет неблокирующий, поэтому пишу так:
Кто-нибудь знает, при использовании неблокирующего сокета так правильно писать ?
PROCEDURE Read (stream: CommStreams.Stream; OUT buf: ARRAY OF BYTE; offset, len: INTEGER; OUT bytes: INTEGER);
VAR sleep: INTEGER;
BEGIN
sleep := 0;
stream.ReadBytes(buf, offset, len, bytes);
WHILE ~(bytes > 0) & (sleep < timeout (* 3000 * & (stream.IsConnected DO
WinApi.Sleep(sleepTime (* 10 *; INC(sleep, sleepTime);
client.stream.ReadBytes(buf, offset, len, bytes)
END;
IF bytes > 0 THEN
Debug.Int("wait time", sleep)
ELSIF sleep >= timeout THEN
Debug.String("timeout")
ELSE
Debug.String("end of data")
END
END Read;
PROCEDURE Search;
(* ... *)
BEGIN
(* ... *)
str := "SEARCH " + minStr + " " + maxStr + " " + hosts + " " + query + 0AX;
(* ... str -> buf ... *)
client.stream.WriteBytes(buf, 0, LEN(str$) + 1, bytes); ASSERT(bytes > 0);
Read(client.stream, buf, 0, bufSize (* 4096 * bytes);
WHILE bytes > 0 DO
(* ... обработка buf ... *)
Read(client.stream, buf, 0, bufSize, bytes)
END;
(* ... *)
END Search;
Я ж говорю, рефлектором глянь. Кодировку KOI8-R юзаю. Я получаю первые 100 записей, а для параллельной закачки больше 10 наверное и не нужно.
ну я могу с большой вероятностью определить, что это тот самый файл. По идее, можно обмануть систему: в avi-шке один байт заменить, тогда z80 тоже будет думать что это тот же файл, но они будут разные. Короче, для фильмов и музыки должно нормально фурыкать
dvd-файлы, например, почти все как братья близнецы.
в смысле? совпадают во всех битах?
так скажем: разные файлы имеют много общего.
Интересует конкретный пример пары файлов, которые бы путались...
Нужно делать GUI и чтобы пользователь сам выбирал
дык фишка в том, что ты поставил качаться и ушел, если все компы выключили (проверял по выниманию сети она будет ждать, как только что-то найдет новое - подключит его к закачке.
короче, лень мне что-то этим заниматься да и некогда держите сорцы:
только чтоб чур если что получится - меня в копирайтах указали!
держите сорцы:только чтоб чур если что получится - меня в копирайтах указали!
1. парсер не нуженИМХО XML хорошо подходит для представления слабоструктурированной информации. То есть когда есть много неструктурированного текста в котором иногда встречаются тэги. В этом случае сохраняется неплохая читабельность (для человека) и объём служебной информации (имена тэгов, имена атрибутов, всякие скобки и кавычки) получается небольшой по сравнению с объёмом полезной информации. Для хорошо структурированной информации XML подходит плохо, так как читабельность просто никакая, а объём служебной информации может в разы превышать объём полезной.
2. совместимость по версиям лучше
Для таблиц (частный случай хорошо структурированной информации) ИМХО лучше всего (по соотношению читабельность/объём/лёгкость разбора) подходит формат "comma separated values" или "tab separated values".
Если выбирать между читабельностью(и улучшенной версионностью) и увеличением объема данных в 2-3 раза, то я выбираю первое.
Т.к. увеличение читабельности - это улучшение качественное, а увеличение/уменьшение объема данных - это улучшение/ухудшение количественное.
Количественные проблемы (особенно, когда разница в 2-3 раза) обычно легко решаются кол-венным наращиванием техники.
Недостаток читабельности настолько просто не решается.
Т.к. увеличение читабельности - это улучшение качественное, а увеличение/уменьшение объема данных - это улучшение/ухудшение количественное.
Количественные проблемы (особенно, когда разница в 2-3 раза) обычно легко решаются кол-венным наращиванием техники.
Недостаток читабельности настолько просто не решается.
можно ли сделать так, чтобы в конце ответа сервера шла строка типа "END"?
>можно ли сделать так, чтобы в конце ответа сервера шла строка типа "END"?
А вот этого не надо. Хочешь, сам добавляй.
А вот этого не надо. Хочешь, сам добавляй.
а зачем ?
Очень просто: при большой загруженности сети (напр., качаю что-нить и параллельно хочу юзать Лориен) сначала происходит Disconnect, а последний пакет-два приходят после этого,
поэтому трудно ловить момент "всё передано, начинай жевать" (сначала ставил начало обработки по Disconnect, но выяснил, что это неправильно). А если это будет добавлено,
то я смогу просто ловить "END", и если пришёл пакет с ним --- значит все остальные тоже пришли
PS. Если будет XML то эта фишка станет ненужна
поэтому трудно ловить момент "всё передано, начинай жевать" (сначала ставил начало обработки по Disconnect, но выяснил, что это неправильно). А если это будет добавлено,
то я смогу просто ловить "END", и если пришёл пакет с ним --- значит все остальные тоже пришли
PS. Если будет XML то эта фишка станет ненужна
А если это будет добавлено,А если не придёт, что будешь делать ?
то я смогу просто ловить "END", и если пришёл пакет с ним --- значит все остальные тоже пришли
Э-э... Ещё не решил...
Ничего не понял.
Во-первых, протокол TCP обеспечивает надежную передачу данных. Данные всегда приходят в правильном порядке, не может конец придти раньше чем часть данных.
Во-вторых, возвращается строчка типа COUNT 155 100 0.21. При этом: 155-общее число найденных записей, 100 - возвращаенных в запросе. Просто получай записи, пока их не наберется 100.
В-третьих, в чем тут может помочь xml? Если соединение порвется, тебе придет не well-formed xml и ты не сможешь его пропарсить. Чем это лучше.
Во-первых, протокол TCP обеспечивает надежную передачу данных. Данные всегда приходят в правильном порядке, не может конец придти раньше чем часть данных.
Во-вторых, возвращается строчка типа COUNT 155 100 0.21. При этом: 155-общее число найденных записей, 100 - возвращаенных в запросе. Просто получай записи, пока их не наберется 100.
В-третьих, в чем тут может помочь xml? Если соединение порвется, тебе придет не well-formed xml и ты не сможешь его пропарсить. Чем это лучше.
1) Эксперимент показал обратное --- по "любимому" запросу 'pink floyd'
при параллельном выкачивании iso-шки сначала пришло событие "Disconnect", а затем уже
последний пакет. Хотя, возможно, это особенности реализации...
2) Видимо, так и сделаю (только сейчас додумал, как )
3) Очень просто: я не буду ловить событие Disconnected, а буду искать в пришедшем пакете закрывающий тег всего документа
при параллельном выкачивании iso-шки сначала пришло событие "Disconnect", а затем уже
последний пакет. Хотя, возможно, это особенности реализации...
2) Видимо, так и сделаю (только сейчас додумал, как
)3) Очень просто: я не буду ловить событие Disconnected, а буду искать в пришедшем пакете закрывающий тег всего документа
1) Эксперимент показал обратное --- по "любимому" запросу 'pink floyd'Бедняга
при параллельном выкачивании iso-шки сначала пришло событие "Disconnect", а затем уже
последний пакет. Хотя, возможно, это особенности реализации...

3) Очень просто: я не буду ловить событие Disconnected, а буду искать в пришедшем пакете закрывающий тег всего документаПиздец
1) Что за события такие? В протоколе TCP их нет, там только функции могут ошибки возвращать.
Ты уверен, что Disconnect приходит именно от сокета, который общается с поисковым сервером, а не от того, который выкачивает .iso-файл?
Если да, то скорее всего, это глюки той реализации сокетов, которую ты используешь. В TCP не могут данные приходить после разрыва соединения.
2) IMHO это самый простой вариант
3) Это не меняет проблемы: что делать, если ни в одном из пришедших пакетов нету закрывающего тега?
Ты уверен, что Disconnect приходит именно от сокета, который общается с поисковым сервером, а не от того, который выкачивает .iso-файл?
Если да, то скорее всего, это глюки той реализации сокетов, которую ты используешь. В TCP не могут данные приходить после разрыва соединения.
2) IMHO это самый простой вариант
3) Это не меняет проблемы: что делать, если ни в одном из пришедших пакетов нету закрывающего тега?
1) Скорее всего, глюк в реализации.
PS. обсуждение закрываю
PS. обсуждение закрываю
Оставить комментарий
Landstreicher
В экспериментальном режиме открыт прямой доступ к поисковому серверу lorien.local (порт 4111). Вы можете посылать туда поисковые запросы, сервер будет отвечать. IMHO может быть полезно при написании разного рода качалок, индексаторов, и проч.Для примера реализован простой скрипт на Perl показывающий как можно пользоваться этим интерфейсом (лежит тут). Мне представляется, что он может быть полезен при использовании из shell-скриптов.
В запросе можно проверять наличие подстрок (SUBSTR "abcdef" использовать операторы AND, OR, NOT. Для избежания неоднозначностей с приоритетом операторов рекомендуется использовать скобки.
Другие проверки:
RESTYPE [0-6] - тип файла (музыка,видео,картинки итп).
ISDIR [01] - файл/каталог
MINSIZE N - размер не менее N байт
MAXSIZE N - размер не более N байт
Пример:
Сортировку можно указывать при помощи 'SORTORDER s1, s2, ... sn'. Доступны такие варианты:
HOSTSTATUS, HOSTWKG, HOSTNAME, FILESIZE, FILEDIR, FILENAME, FILENAMECASE, FILEPATH
Если у кого-то есть предложения по более удобному формату запроса - пишите.