Библиотека для работы с иерархией регулярного выражения
Какое нахрен дерево? Конечный автомат.
Вот, сложнее такого в регулярных выражениях не бывает в принципе:
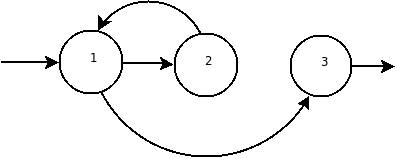
это не регулярное выражение.
и даже не конечный автомат.
и даже не конечный автомат.
Ну да, подразумевается, что переход происходит при сбрасывании на кружок буквы. Приведённый фрагмент тогда образуется РВ вида a*b
Ну так это же рекурсивное описание, правильно?
Вот и получается, что в каждом из кружков может сидеть такая же структура (как на рисунке).
Вот я и хочу иметь возможность работать как со всем выражением, так и с выражением, которое может быть в каждом из кружков (и так далее вглубь по иерархии).
Только вот как это сделать с минимумом вспомогательного кода?
Вот и получается, что в каждом из кружков может сидеть такая же структура (как на рисунке).
Вот я и хочу иметь возможность работать как со всем выражением, так и с выражением, которое может быть в каждом из кружков (и так далее вглубь по иерархии).
Только вот как это сделать с минимумом вспомогательного кода?
Нет, обычно регулярные выражения реализуются так, что кружки не содержат внутри себя других РВ, а только более низкоуровневые вещи. Проверки символов, реализации ветвлений (как №1 сохранения выделенных значений в проверяемой строке и т.п. Например, пусть URL представляется в виде: protocol://host_name. Для выделения protocol, user_name и host_name можно использовать следующее РВ: \s*(?:(.*?)://)?(?:(.*?)@)?(\S*?)\s*$. У моей реализации на паскале получается такой список:
Здесь Anything - соответствует точке в РВ, Simple atom соотв. простому символу, Complex atom соотв. значению в [] или одному из \s\S\d\D\w\W, Branch - ветвление, Group begin - это для сохранения значений группы, Anchor - это якори в РВ, ^, $
0: Group begin: 0. Next state: 1
1: Branch. On failure: 3. Next state: 2
2: Complex atom. Next state: 1
3: Branch. On failure: 11. Next state: 4
4: Group begin: 1. Next state: 5
5: Branch. On failure: 6. Next state: 7
6: Anything. Next state: 5
7: Group end. Next state: 8
8: Simple atom: :. Next state: 9
9: Simple atom: /. Next state: 10
10: Simple atom: /. Next state: 11
11: Branch. On failure: 17. Next state: 12
12: Group begin: 2. Next state: 13
13: Branch. On failure: 14. Next state: 15
14: Anything. Next state: 13
15: Group end. Next state: 16
16: Simple atom: @. Next state: 17
17: Group begin: 3. Next state: 18
18: Branch. On failure: 19. Next state: 20
19: Complex atom. Next state: 18
20: Group end. Next state: 21
21: Branch. On failure: 23. Next state: 22
22: Complex atom. Next state: 21
23: Anchor end. Next state: 24
24: Group end. Next state: 25
Здесь Anything - соответствует точке в РВ, Simple atom соотв. простому символу, Complex atom соотв. значению в [] или одному из \s\S\d\D\w\W, Branch - ветвление, Group begin - это для сохранения значений группы, Anchor - это якори в РВ, ^, $
Предположим наше РВ(0) описывает некоторый текст, в котором присутствуют и даты и диапазоны дат.
И я хочу уметь получать и все даты вообще (1 и либо только даты(2 либо только диапазоны дат(3 и обрабатывать текст этим самым РВ(0).
Получается, что для этого мне надо заводить 4 разных РВ (по одному на каждый случай).
Но зачем мне это делать, если первое РВ(1) содержится во всех остальных (0,2,3).
А в основном содержится какая-то комбинация из набора (1-3).
Как минимум, я хочу быть уверенным, что РВ, описывающее дату, во всех этих случаях одинаково. В том числе это аргумент работает и против простого дублирования.
А вообще, зачем мне это хранить порознь, если оно все связано - это не правильно.
Например, если у меня изменится РВ для даты (например оно строится в соответствии с региональными настройками я не хочу править все РВ, где присутствует дата.
В общем это что-то вроде ООП в РВ.
И я хочу уметь получать и все даты вообще (1 и либо только даты(2 либо только диапазоны дат(3 и обрабатывать текст этим самым РВ(0).
Получается, что для этого мне надо заводить 4 разных РВ (по одному на каждый случай).
Но зачем мне это делать, если первое РВ(1) содержится во всех остальных (0,2,3).
А в основном содержится какая-то комбинация из набора (1-3).
Как минимум, я хочу быть уверенным, что РВ, описывающее дату, во всех этих случаях одинаково. В том числе это аргумент работает и против простого дублирования.
А вообще, зачем мне это хранить порознь, если оно все связано - это не правильно.
Например, если у меня изменится РВ для даты (например оно строится в соответствии с региональными настройками я не хочу править все РВ, где присутствует дата.
В общем это что-то вроде ООП в РВ.
Правильно ли я понял, что в конце концов у тебя тоже получается регулярное выражение, но ты хочешь что-то типа макроподстановщика. Чтобы можно было написать
const string date = @"(\d{1,2}/\d{1,2}/\d{1,2})";
const string dateInterval = @"(" + dateRx + @"-" + dateRx + @")";
Regex myReges = new Regex(@"bla bla bla (?'date1'" + dateRx + @")* bla bla " + dateInterval + @" bla bla");
Так? Ну вот так и пиши! Даже, наверное, можно в интервале сразу обернуть именованными скобками startDate/endDate, отключив нафиг ExplicitCapture, и они даже возможно будут правильно обрабатываться, но это лучше проверить.
Если же тебе нужно что-то намного более сложное, то, боюсь, архитектура фиговая. Ты абсолютно уверен, что вот этот вот сложный составной регекс не придётся в какой-то момент менять на BNF?
Хотя если сильно парит, а писать много, то можешь действительно нафигачить простенький макроподстановщик, которому даётся словарег "name" - "regex string", а он строит большой такой регекс из этого всего, а потом применяет к самому себе. Никаких, кстати, причин говорить об этом всём как о "дереве" или "иерархии", я что-то не вижу!
const string date = @"(\d{1,2}/\d{1,2}/\d{1,2})";
const string dateInterval = @"(" + dateRx + @"-" + dateRx + @")";
Regex myReges = new Regex(@"bla bla bla (?'date1'" + dateRx + @")* bla bla " + dateInterval + @" bla bla");
Так? Ну вот так и пиши! Даже, наверное, можно в интервале сразу обернуть именованными скобками startDate/endDate, отключив нафиг ExplicitCapture, и они даже возможно будут правильно обрабатываться, но это лучше проверить.
Если же тебе нужно что-то намного более сложное, то, боюсь, архитектура фиговая. Ты абсолютно уверен, что вот этот вот сложный составной регекс не придётся в какой-то момент менять на BNF?
Хотя если сильно парит, а писать много, то можешь действительно нафигачить простенький макроподстановщик, которому даётся словарег "name" - "regex string", а он строит большой такой регекс из этого всего, а потом применяет к самому себе. Никаких, кстати, причин говорить об этом всём как о "дереве" или "иерархии", я что-то не вижу!
Никаких, кстати, причин говорить об этом всём как о "дереве" или "иерархии", я что-то не вижу!часто нужно, когда высокоуровневый парсер отличается от низкоуровневого.
допустим парсим текст:
первый парсер бьет на абзацы : (.*\n\n)*
второй парсер бьет на предложения: (.*[\.!\?])*
третий парсер бьет на слова: ...
и т.д.
причем каждый из парсеров может быть записан, в общем случае, как на regex, так и на BNF, так и в виде куска кода: например, парсер xml-я + парсер текстов записанных внутри тегов.
Правильно ли я понял, что в конце концов у тебя тоже получается регулярное выражение, но ты хочешь что-то типа макроподстановщика.Правильно.
Так? Ну вот так и пиши!Пока так и пишу.
архитектура фиговая. Ты абсолютно уверен, что вот этот вот сложный составной регекс не придётся в какой-то момент менять на BNF?А какая архитектура лучше подойдет?
Под работу с тем же BNF - какие есть библиотеки для этого (желательно под .net)?
Да и наверняка такая библиотека сама по тексту строить BNF не будет - все равно придется использовать регэкспы для предварительного анализа. Или нет?
часто нужно, когда высокоуровневый парсер отличается от низкоуровневого.А реализация для такого есть?
допустим парсим текст:
первый парсер бьет на абзацы : (.*\n\n)*
второй парсер бьет на предложения: (.*[\.!\?])*
третий парсер бьет на слова: ...
и т.д.
причем каждый из парсеров может быть записан, в общем случае, как на regex, так и на BNF, так и в виде куска кода: например, парсер xml-я + парсер текстов записанных внутри тегов.
И еще.
Есть библиотеки для работы с регулярными множествами?
Чтобы можно было над ними операции различные выполнять, регекспы по ним строить и тп?
Ну или хотя бы подходы к этому?
А то пока кроме общей теории ничего не попадалось
Есть библиотеки для работы с регулярными множествами?
Чтобы можно было над ними операции различные выполнять, регекспы по ним строить и тп?
Ну или хотя бы подходы к этому?
А то пока кроме общей теории ничего не попадалось
Я как-то давным давно рекламировал здесь хрень под названием ragel. Это как раз генератор конечных автоматов, в котором подавтоматы можно обозначать "именами", строить из них по всякому автоматы покрупнее и т.п. Можешь глянуть, правда он "С-шный", то есть действия при переходах там предлагается программировать на С.

Оставить комментарий
durka82
Желательно под .net(C# но варианты рассматриваются.Пишу программу для анализа текста.
Так получается, что регулярные выражения, используемые для анализа, образуют дерево.
То есть сначала используются выражения, которые потом входят в состав более крупных выражений, и так пока не получится регэксп, анализирующий весь документ (то есть процесс рекурсивен).
Вот и хочется все это хранить связно (тем же деревом).
При этом для получения регекспа очередного уровня нужно будет вшить регекспы предыдущего уровня в некий шаблон. Можно это все сделать через сами регекспы?
Только вот родная .net-овская библиотека так не умеет (или я не там искал?)
Существуют ли библиотеки, которые такое умеют?
Ну или как это лучше сделать самому?
Или почему это на самом деле не нужно, а делать надо так?..
Спасибо за внимание