Нахождение обратной матрицы методом вращений.
Компилятор?
Вариант использовать из проги Матлаб не катит? Там все алгоритмы уже написаны и работают со всеми возможными оптимизациями.
MSVC из 2005 и GCC. Дают примерно одинаковую скорость.
Это мне по учёбе, так что не катит.
gprof делал? где затык?
еще бы код сюда кинул
еще бы код сюда кинул
Что такое gprof не знаю, затык в методе вращений, версия, что я сейчас выложил, работает медленее чем 36 сек., но это легко исправляется путём замены аргументов в вызове нескольких функций, т.е. сам метод вращения что и в последнем варианте (который я только что испортил исправлениями).
Под PIV Надо icc попробовать...
36 секунд это что?
на Athlon XP 2500+ она выдаёт следующее и подвисает (не дождался ответа в течении двух минут):
на Athlon XP 2500+ она выдаёт следующее и подвисает (не дождался ответа в течении двух минут):
Inversion: clocks: 7160000, seconds: 7.160000
Multiplication: clocks: 1990000, Seconds: 1.990000
Residual norm: 4.383545e-10
Это scanf, чтобы увидеть (ну не догадался я консоль запускать) Не забудь изменить константу N, сейчас она равно 1000, в файле Bogachev.cpp - это размерность матрицы.
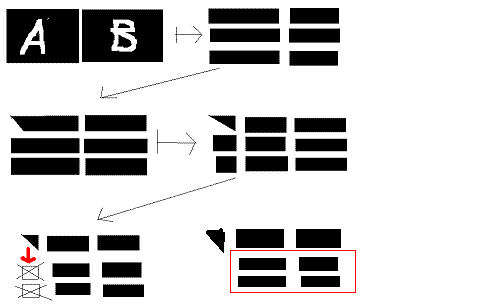
(1) Диагонализуем главный минор какого-то порядка (небольшого вычисляем соотв. матрицу вращений
(2) Умножаем эту матрицу на полосу A_0 справа от минора
(3) Делим матрицу ниже полосы, в которой лежит главный минор на полосы A_1, ..., A_n
(4) Обнуляем первые n столбцов текущей полосы, находим соотв. м-цу вращений и умножаем её на полосы A_0 A_k, которые мы считаем склееными в одну матрицу, так пробегаем все полосы
Задолбался! Пишу уже месяц, собственно, написал дня за три включая оптимизацию (блочный метод, развёртка циклов). Но достигнуть нужной скорости не могу - нужно считать на P4 2400 или AXP 2500 матрицу порядка 2000x2000 примерно за 20 секунд, но как я ни старался, быстрее чем за 36 у меня не получается. Дайте советы по алгоритму!а переделай ка ты свою программку на C вместо C++ (уж надеюсь ты знаешь как это сделать)
у C компиляторов вполне может оптимизатор быть гораздо качественнее.
И перекомпили GCC с опцией -O3 (если ты умудрился раньше не включить оптимизацию)
MSVC - отстой
ICC - хорош, так что если юзать MSVS, то с ICC
ну ты конечно, надеюсь, сам догадался в MSVC выбрать Release, вместо Debug (который по умолчанию).
вообще не понимаю почему твоя программа на плюсах, а не на сях, когда ты не используешь ООП и вообще вся программа с стиле C, что для плюсов является паршивым стилем.
MSVC давал код чуть быстрее чем у GCC, естественно, все оптимизации были включены как у того, так и другого. А вот C - попробую.
Попробуй использовать уже написанные алгоритмы. Вроде бы здесь есть все необходимое тебе.
Study FAQ?
---
...Я работаю антинаучным аферистом...
---
...Я работаю антинаучным аферистом...
MSVC - отстойСотри и не позорься. GCC проигрывает студии по качеству оптимизации.
Сотри и не позорься. GCC проигрывает студии по качеству оптимизации.видать у вас была галимая версия GCC (а если вы лично не проверяли с нужными опциями оптимизации, то вообще не о чем говорить) - какая-нибудь 3.0, 3.1.
GCC (ясно последние версии, либо 2.95.3) совершенно определенно не проигрывает MSVC6 (а очень даже выигрывает) - из личного опыта измерений производительности и просмотра ассемблерного кода.
VC7, VC8 - не проверял, проверю
ICC оптимизирует хорошо - это да.
вы ведь уже по этому вопросу
вы ведь уже спорили по этому вопросуразве ж это спор
каждый высказал по мнению и все
да и смысл как бы не в споре, а в том, чтобы опытом поделиться
с нужными опциями оптимизацииНу если тюнить GCC как-то помимо -O3, то и студию надо тюнить, чтобы сравнивать. Я пользуюсь 3.4, (4.0 со своим буквальным пониманием стандарта идет лесом
 ). Я конечно систематического исследования никакого не проводил, но вот совсем недавно проверяли, gcc не смог свернуть for(...){a[i]=b[i];} в rep movsb, а студия сворачивает. Не знаю, может сейчас такие процессоры пошли, что movsb медленне чем цикл
). Я конечно систематического исследования никакого не проводил, но вот совсем недавно проверяли, gcc не смог свернуть for(...){a[i]=b[i];} в rep movsb, а студия сворачивает. Не знаю, может сейчас такие процессоры пошли, что movsb медленне чем цикл  но memcpy работал вдвое быстрее чем то, что нагенерил gcc, а на студии не было разницы. Такая мелочь, конечно, не показатель, но нексолько похожих примеров и сформировали мое мнение...
но memcpy работал вдвое быстрее чем то, что нагенерил gcc, а на студии не было разницы. Такая мелочь, конечно, не показатель, но нексолько похожих примеров и сформировали мое мнение...Он сказал, что проверял на VC6, а я пользовался VC2003 и VC2005. 2003, по моему, чуть побыстрее, но они оба быстрее чем GCC, причем иногда очень значительно, порядка 15% (6.6 сек на GCC и 5.8-6 на 2005).
Оставить комментарий
Olenenok
Задолбался! Пишу уже месяц, собственно, написал дня за три включая оптимизацию (блочный метод, развёртка циклов). Но достигнуть нужной скорости не могу - нужно считать на P4 2400 или AXP 2500 матрицу порядка 2000x2000 примерно за 20 секунд, но как я ни старался, быстрее чем за 36 у меня не получается. Дайте советы по алгоритму!