Вопрос про оптимизацию работы
А сколько примерно вы пишете до проверки.Зависит от языка. На java обычно сразу пишешь много кода, потом запускаешь. На Scala — зависит от сложности используемых сущностей. На DSL обычно пишешь код понемногу.
Люди со схожими проблемами придумали TDD. Имхо, отличный способ научиться кодить.
Если по теме - сначала пишу весь код, только потом запускаю саму прогу. Если кода много - то использую TDD.
Если по теме - сначала пишу весь код, только потом запускаю саму прогу. Если кода много - то использую TDD.
Я взял за правило писать до тех пор, пока могу держать в голове всё написанное и не скомпилированное. Как только "оперативная память" заканчивается, компилирую и отлаживаю написанные куски, после чего забываю про их внутреннее устройство и пишу дальше.
Да, ещё лучше писать так (если позволяет используемый ЯП чтобы из синтаксической корректности программы как можно в большей степени следовала её семантическая корректность. Это позволяет экономить время ещё и на отладке мелких ошибок/опечаток.
Да, ещё лучше писать так (если позволяет используемый ЯП чтобы из синтаксической корректности программы как можно в большей степени следовала её семантическая корректность. Это позволяет экономить время ещё и на отладке мелких ошибок/опечаток.
Конечно же надо писать маленькими частями, постоянно компилировать и всё проверять.
Я практически никогда отладчиками не пользуюсь.
Я практически никогда отладчиками не пользуюсь.
тут всё сложно, иногда бывает полезно быстро наваять нерабочий прототип чтоб найти проблемы в формулировке и начальном дизайне.
главное потом никому этот прототип не показывать, а то вдруг он окажется вполне рабочим доказывай потом что ты не виноват
доказывай потом что ты не виноват
главное потом никому этот прототип не показывать, а то вдруг он окажется вполне рабочим
доказывай потом что ты не виноватпостоянно компилироватьошибки компиляции IDE на лету подсвечивает же

... и всё проверять.да, проверять надо, однако, запуск программы помогает в этом, но не сильно, поскольку вариантов работы программы экспоненциально большое количество. Надо доказывать корректность программ по коду, а запуск программы это как проверка твоих логических построений (использованных при доказательстве) на частном случае.
ошибки компиляции IDE на лету подсвечивает жеахаха, напиши для C++ такую IDE, разбогатеешь
ахаха, напиши для C++ такую IDE, разбогатеешьVisual Assist в этом плане самая продвинутая штука из попадавшихся мне. Иногда кажется, что разработчики VA запросто могли бы превратить свой парсер C++ в front-end компилятора.
Visual Assist в этом плане самая продвинутая штука из попадавшихся мне. Иногда кажется, что разработчики VA запросто могли бы превратить свой парсер C++ в front-end компилятора.поэтому можно ли на этом разбогатеть, это еще большой вопрос, не факт что сиппешники создают большой спрос
ошибки компиляции IDE на лету подсвечивает жеЯ использую vim. Только пидорасы используют IDE.
Уточни, пожалуйста, как ты проверял этот факт.
Не пишешь большими кучками, а ебашишь по 2-3 строчки, запускаешь прогу, смотришь чо получось.Изучай TDD, что
А сколько примерно вы пишете до проверки.
> Изучай TDD
А что там изучать то "практикуй" тогда уж.
"практикуй" тогда уж.
А что там изучать то
"практикуй" тогда уж.Не, бездумная практика ТДД приводит к тестам, которые падают от малейшего изменения все. Я видел тесты, которые количество вызовов функций проверяли.
Хорошее же ТДД, очевидно, должно генерировать и полное, и слабо пересекающееся покрытие тестами, чтобы не приходилось продираться сквозь них, как сквозь болото.
Хорошее же ТДД, очевидно, должно генерировать и полное, и слабо пересекающееся покрытие тестами, чтобы не приходилось продираться сквозь них, как сквозь болото.
а что такое полное, по строчкам кода?
а что такое полное, по строчкам кода?Вот кстати пример, когда просто практиковать опасно.
В идеальном случае полного покрытия тест с одной стороны не должен знать ничего о коде, а с другой проверять все бизнес случаи использования класса.
проверять все бизнес случаи использования классатут экспоненциальная зависимость от количества параметров класса
минус поставил не я
минус поставил не яМинус за предыдущий пост тебе поставил я.

с одной стороны не должен знать ничего о коде, а с другой проверять все бизнес случаи использования классакстати, противоречивое предложение. Класс это элемент кода, т.е. не должен знать о классе?

кстати, противоречивое предложение. Класс это элемент кода, т.е. не должен знать о классе?Он не должен знать о реализации. Только об интерфейсе и, возможно, об ограничениях данных.
Он не должен знать о реализации. Только об интерфейсеа ты знаешь откуда и зачем это?
Он не должен знать о реализации.в такой постановке чистый TDD в топку
я за black box + white box testing
http://agiletesting.blogspot.ru/2005/08/white-box-vs-black-b...
Он не должен знать о реализации. Только об интерфейсе и, возможно, об ограничениях данных.Еще вопросы вдогонку. Что ты называешь интерфейсом, сигнатуру методов(*1)? комментарии к методам входят в интерфейс?
знать ... и, возможно, об ограничениях данных.эти знания записываются или остаются только в голове разработчика? если записываются, то где и как?
(*1) не забываем о динамических языках
я за black box + white box testingwhite box тесты очень плохо себя ведут на изменяющихся требованиях
white box тесты очень плохо себя ведут на изменяющихся требованияхбольшинство тестов как black box так и white это дублирование информации о бизнес правилах, а дублирование всегда ведет себя плохо при изменяющихся требованиях (если нельзя поручить отслеживание дублирования машине).
Вот кстати пример, когда просто практиковать опасно.Тесты бизнес фич - это как правило систем-тесты.
В идеальном случае полного покрытия тест с одной стороны не должен знать ничего о коде, а с другой проверять все бизнес случаи использования класса.
А тдд на мой взгляд больше, все-таки, о юнит-тестах. В которых мочится все окружение, и тестируются "бизнес-фичи" одного класса. И в таких условиях считать количество вызовов методов у моков совершенно не зазорно. Более того, все mock фреймворки поддерживают рестрикт на количество вызовов метода.
дублирование ведёт себя плохо, но зато надёжно. При этом тесты лишь дублируют некоторые аспекты правила, для них не надо писать параллельно работающего приложения, как в случае дублирования управления летающими машинами
одно дело автоматизированные тесты для повышения надежности софта, другое дело разработка
тестами; что является бредом.
управляемый, ведомый, гонимый, приводной, приводимый в действие, запускаемый, нанесенный, вед `омый, работающий от привода
что является бредом.это я к началу разговора, когда посоветовали использовать TDD
что является бредом.Расскажи это этим парням.
Расскажи это этим парням.Да, обязательно!

А вот как выглядит разработка управляемая просто чтением условия задачи. Читаем условие задачи:
The function returns the string, but with line breaks inserted at just the right places to make sure that no line is longer than the column number. You try to break lines at word boundaries.
You mean like a word processor, right? You break the line by replacing the last space in a line with a newline.
В условии есть "слова", есть разделители слов. Поэтому граница колонки может попасть на разделитель слов, либо внутрь слова (*1). Может так x|_, а может так x_|. Положим, что во втором случае пробел тоже удаляется (это в требованиях явно не отражено, поэтому смотрим как действуют текстовые редакторы). Если попали внутрь слова, то возвращаемся до ближайшего пробела. Если ближайшего пробела нет, режем слово (*2). Записываем два if-а (*1) и (*2) в коде:
static void Main
{
Console.WriteLine(string.Join(Environment.NewLine, Wrap("wor d word", 5;
}
private static IEnumerable<string> Wrap(string s, int columnSize)
{
if (columnSize >= s.Length) return Enumerable.Repeat(s, 1);
var line = s.Substring(0, columnSize);
var firstLine = Enumerable.Repeat(line, 1);
if (s[columnSize] == ' ') return firstLine.Concat(Wrap(s.Substring(columnSize + 1 columnSize; //(*1)
var lastSpacePosition = line.LastIndexOf(' ');
return lastSpacePosition >= 0 //(*2)
? Enumerable.Repeat(s.Substring(0, lastSpacePosition 1)
.Concat(Wrap(s.Substring(lastSpacePosition + 1 columnSize
: firstLine.Concat(Wrap(s.Substring(columnSize columnSize;
}
Позапускали программку для проверки логических построений.
Сравним с кодом из статьи. Видим, что у них if-ы идут в другом порядке. Тут же находим случай, на котором их код фейлится. Wrap("wor d word", 5). У них выдает wor|d|word, а должен wor d|word. Полный Win!
Расскажи это этим парням.Ссылка здоровская, спасибо
. По перекрестной ссылки открыл вот это http://cleancoder.posterous.com/the-transformation-priority-...Чуваки дошли до вот это "Refactorings have counterparts called Transformations" (*1). И тупят, TDD съел их мозг

Просто диву даешься, как люди легко теряют здравомыслие под воздействием идеологии что ООП, что TDD.
(*1) у меня тоже в open source проекте где-то это было
По перекрестной ссылки открыл вот это http://cleancoder.posterous.com/the-transformation-priority-...Ребята молодцы, супер:
Implications
If my suspicions turn out correct, then a number of things become possible.
Tool support for transformations similar to the current tool support for refactorings.
Tool support for suggesting transformations that follow priority order.
The sequence of tests, transformations, and refactorings may just be a formal proof of correctness.
Formal Proof of Correctness
That last point requires a bit more amplification. If you can describe the desired behavior of a program with a suite of tests, and if you can show step by step how each test is passed by using formal transformations and refactorings, then you have created a proof.
Oddly, the proof is attained by constructing the algorithm in a stepwise fashion. It is interesting to compare this to Dijkstra’s approach of proving correctness by taking the algorithm apart.
Я это в свое время назвал Deducible architecture by code transformation. Единственно, что у них плохо это: "you can describe the desired behavior of a program with a suite of tests". Прелесть в том, что требования (desired behavior of a program) тоже конструируются поэтапно (a stepwise fashion). Этапы настолько маленькие, что человек (программист, аналитик и т.д.) способен с ними работать при неспособности делать много (on our inability to do much, на русском).
Большинство информации сохраняется в коде в самой реализации, а не в тестах. То, что не отражается в коде, отображается в дополнительных документах, но стараемся по максимуму информацию закладывать в код; причем так, чтобы с помощью инструментов можно было быстро выделить фрагменты кода, которые соответствуют задаваемым subset-ам of a program's behavior, ref.
Тесты пишем для автоматизации прогона программы для разумного количества случаев. Но, конечно, не полагаемся на тесты и, тем более, не делаем из них управляющих процессом разработки.
Теперь думаю понятно, почему я так сильно настаиваю на статической типизации, поскольку цитируемые выше инструменты (tool) играют важную роль в описанном процессе.
а с каким языком работают?
а с каким языком работают?о program slicing стоит набрать в гугле
http://en.wikipedia.org/wiki/Program_slicing
http://research.cs.wisc.edu/wpis/html/#summary
По поводу языков встречал вот такое:
But slicing techniques which work for
procedural languages do not adapt well to OO languages
since dynamic binding and polymorphism make it difficult
to obtain precise control flow information. Some of these
techniques have recently been extended to handle features
of statically typed OO languages [22][31].
http://scholar.google.com/scholar_url?hl=en&q=http://cit...
а то вдруг он окажется вполне рабочимага, и его хуяк в продакшн. а потом через полгода вылезет проблема масштабируемости или еще чего.
Отлично, теперь давай подведем итог.
Ты загрузил задачу целиком себе в контекст, подумал как бы можно было обобщить все кейсы, придумал и заимплементил.
ТДД достиг почти того же самого без необходимости держать в голове цельную картину. Код, можно сказать, "родился" сам.
То есть твой способ не подходит, если задача не умещается целиком в голове.
И показательно, что ребята посадили багу. Говорит нам всего лишь о том, что если пользоваться ТДД совсем бездумно, и не компенсировать это бОльшим количеством тестов, то вы получите условно-работающий код.
Впрочем, твое обдумывание задачи целиком тоже тебе ничего не гарантирует, зависит от способностей конкретного индивида держать кратинку в голове и ничего не упустить, и при обнаружении багов непонятно что делать, тестов то нету. Загружать картинку опять целиком в мозг?
Еще то, что не было продемонстрировано в данном примере - это то, что разбиение по классам / их паблик интерфейс точно так же вырастает, как в примере выше вырос код.
Это решило мою личную проблему того, что до ТДД, к концу работы над куском кода, тот дизайн, который я придумал в начале, мне переставал нравиться.
С ТДД, через некоторое время я стал замечать, что, во-первых, первоначальный дизайн, получаемый при ТДД, не хуже того, что получался часовыми обдумываниями задачи в голове, а во-вторых, по мере работы над фичей в случае с тдд дизайн магическим образом менялся, пока ты писал тесты, оставаясь красивым до конца.
Ты загрузил задачу целиком себе в контекст, подумал как бы можно было обобщить все кейсы, придумал и заимплементил.
ТДД достиг почти того же самого без необходимости держать в голове цельную картину. Код, можно сказать, "родился" сам.
То есть твой способ не подходит, если задача не умещается целиком в голове.
И показательно, что ребята посадили багу. Говорит нам всего лишь о том, что если пользоваться ТДД совсем бездумно, и не компенсировать это бОльшим количеством тестов, то вы получите условно-работающий код.
Впрочем, твое обдумывание задачи целиком тоже тебе ничего не гарантирует, зависит от способностей конкретного индивида держать кратинку в голове и ничего не упустить, и при обнаружении багов непонятно что делать, тестов то нету. Загружать картинку опять целиком в мозг?
Еще то, что не было продемонстрировано в данном примере - это то, что разбиение по классам / их паблик интерфейс точно так же вырастает, как в примере выше вырос код.
Это решило мою личную проблему того, что до ТДД, к концу работы над куском кода, тот дизайн, который я придумал в начале, мне переставал нравиться.
С ТДД, через некоторое время я стал замечать, что, во-первых, первоначальный дизайн, получаемый при ТДД, не хуже того, что получался часовыми обдумываниями задачи в голове, а во-вторых, по мере работы над фичей в случае с тдд дизайн магическим образом менялся, пока ты писал тесты, оставаясь красивым до конца.
Тесты пишем для автоматизации прогона программы для разумного количества случаев. Но, конечно, не полагаемся на тесты и, тем более, не делаем из них управляющих процессом разработки.У тебя, похоже, какое-то свое восприятие этих слов - "Управляющие Процессом Разработки". И ты сейчас противишься не столько преимуществам, которые вижу я, сколько этому восприятию, которое есть только у тебя и тебе не нравится.
Не знаю, что там у тебя в голове и кем управляет, но лично мне частичное перенятие ТДД в итоге позволило не думать слишком долго над дизайном и уменьшить куски, которые надо целиком запихивать в голову.
Голову я совсем по-прежнему не отключаю, маленькие куски по-прежнему пишутся тем способом, что описал ты.
Просто в итоге этого всего моя производительность возросла раза в два, и побочным эффектом я еще получил красивый дизайн.
То есть твой способ не подходит, если задача не умещается целиком в голове.тоже самое можно делать и программно. Это же фактически проверка инвариантов для всех вариантов работы кода. Похожей проверкой занимается статическая типизация.
Единственно, что у них плохо это: "you can describe the desired behavior of a program with a suite of tests". Прелесть в том, что требования (desired behavior of a program) тоже конструируются поэтапно (a stepwise fashion). Этапы настолько маленькие, что человек (программист, аналитик и т.д.) способен с ними работать при неспособности делать много (on our inability to do much, на русском).Так почему плохо-то? Пускай поэтапно - как раз идеально подходит под дополняемый по прицнипу TDD test suite. Нужно добавить новое требование - добавляем новый тест, вуаля.
Большинство информации сохраняется в коде в самой реализации, а не в тестах.То есть ты предлагаешь требования к коду хранить в самом коде (кстати, как? или выпихивать их в какое-то свое место.
Потом для этих способов изобрести какую-то тулзу специально для того, чтобы метчить требования с кусками их реализации.
Потом, видимо, написать тулзу, которая будет проверять, подходит ли реализация под требования.
И, наконец, понять, что все это время мы занимались переизобретением юнит-тестирования. Так, что ли?
Я где-то видел то ли идеи, то ли уже готовые тулзы, которым на вход даешь готовый код, а они генерят набор входных данных, который покрывает все ифы / кейсы / итд. Ты, похоже, об этом.
Но, еще раз, это когда уже у тебя _есть_ готовый код.
А мы же сейчас обсуждаем проблему как быстро писать красивый правильно работающий код.
Но, еще раз, это когда уже у тебя _есть_ готовый код.
А мы же сейчас обсуждаем проблему как быстро писать красивый правильно работающий код.
Я где-то видел то ли идеи, то ли уже готовые тулзы, которым на вход даешь готовый код, а они генерят набор входных данных, который покрывает все ифы / кейсы / итд. Ты, похоже, об этом.не совсем или совсем не так. Такой подход даст лишь покрытие, но не проверку правильности.
Проверка правильности начинается с инвариантов, например, следующих:
1. результат является правильным(необходимое условие если каждая строка не больше, чем заданная длина
2. результат является правильным(необходимое условие если в каждую предыдущую строчку нельзя добавить слово из следующей строки.
и т.д.
А дальше проверяется, что при всех вариантах поведения кода, эти инварианты будут выполнимы.
А, дошло о чем ты.
Да, именно, об этом же и речь.
В идеале TDD юнит-тесты должны как раз в это и выродиться.
Проблема только в том, что непонятно, на каких языках писать эти инварианты, и кто будет заниматься автоматической проверкой.
На ВМК, кажется, даже целый семестровый курс был посвящен проблемам верификации программ, где в итоге это решалось для предикативных спецификаций (предусловие+постусловие) и программ на коне-сферически-ваккумном предикативном же языке.
К сожалению, современные языки, видимо, не допускают такой автоматизированной верификации, что делает всю эту красивую теорию совершенно непрактичной.
А юнит-тесты худо-бедно являются практическим решением этой задачи. И, допустим, совершенно естественно увидеть два решения задачи - одно простое но квадратичное, другое сложное, но линейное, и юнит-тест верифицирующий быстрый алгоритм по простому на псевдорандомных инпутах.
Да, именно, об этом же и речь.
В идеале TDD юнит-тесты должны как раз в это и выродиться.
Проблема только в том, что непонятно, на каких языках писать эти инварианты, и кто будет заниматься автоматической проверкой.
На ВМК, кажется, даже целый семестровый курс был посвящен проблемам верификации программ, где в итоге это решалось для предикативных спецификаций (предусловие+постусловие) и программ на коне-сферически-ваккумном предикативном же языке.
К сожалению, современные языки, видимо, не допускают такой автоматизированной верификации, что делает всю эту красивую теорию совершенно непрактичной.
А юнит-тесты худо-бедно являются практическим решением этой задачи. И, допустим, совершенно естественно увидеть два решения задачи - одно простое но квадратичное, другое сложное, но линейное, и юнит-тест верифицирующий быстрый алгоритм по простому на псевдорандомных инпутах.
То есть твой способ не подходит, если задача не умещается целиком в голове.Это не мой способ, а Дейкстры
Вот статья Дейкстры про ограниченность головы on our inability to do much, на русском
Summarizing: as a slow-witted human being I have a very small head and I
had better learn to live with it and to respect my limitations and give them full
credit, rather than to try to ignore them, for the latter vain effort will be
punished by failure.
То есть твое замечание Дейкстра явно принимал во внимание, при этом опубликовал свою методологию.
Он полагается на использования нашей способности к абстракции. Он пишет об этом
тут http://khpi-iip.mipk.kharkiv.edu/library/extent/dijkstra/ewd...
и тут http://www.cs.utexas.edu/~EWD/transcriptions/EWD03xx/EWD340....
We all know that the only mental tool by means of which a very finite piece of reasoning can cover a myriad cases is called “abstraction”; as a result the effective exploitation of his powers of abstraction must be regarded as one of the most vital activities of a competent programmer.
Ты загрузил задачу целиком себе в контекст, подумал как бы можно было обобщить все кейсы, придумал и заимплементил.Нет же. Я тратил еще меньше умственных усилий, чем при TDD.
И показательно, что ребята посадили багу. Говорит нам всего лишь о том, что если пользоваться ТДД совсем бездумно, и не компенсировать это бОльшим количеством тестов, то вы получите условно-работающий код.Это говорит нам о том, что такие программисты мучают пользователей багами, которых можно было избежать. Еще раз повторю свой поин: я просто записал условие задачи на языке программирования. Мне стоит прописать мою активность по этой задаче до скучных деталей?
Это решило мою личную проблему того, что до ТДД, к концу работы над куском кода, тот дизайн, который я придумал в начале, мне переставал нравиться.Это не только у тебя так. Похожая ситуация встречается, если не у всех, то у очень многих. Упомянутые выше code transformations (Refactorings have counterparts called Transformations) не связаны с TDD, их можно выполнять не полагаясь на тесты.
делает всю эту красивую теорию совершенно непрактичнойТо, о чем говорит это, да, теория. известный теоретик, он даже существующими инструментами (ReSharper) не пользуется. Я же говорю о реальной практике.
> Это не мой способ, а Дейкстры (1)
> Вот статья Дейкстры про ограниченность головы on our inability to do much (2)
> Он полагается на использования нашей способности к абстракции. Он пишет об этом (3)
Ты как-то очень интересно аргументируешь свою точку зрения, которая, если я правильно понял "ваше TDD-BDD - неэффективное говно".
Давай я постараюсь прояснить некие моменты твоей позиции.
Я так понимаю, тебе не нравится то, что написание тестов вперед ограничивает твое мышление, заставляя иначе смотреть на проблему. Ты же предпочитаешь "просто писать условие задачи на языке программирования".
Хорошо. Теперь давай разберемся в твоих ссылках.
(2) - всего лишь утверждение, что мы ограничены в своей способности вмещать много инфы. Согласен, принято. Ничему не противоречит.
(3) - абстракции. Замечательно. Абстракции у нас сейчас везде, их кучи этих уровней, от физического с электрончиками до высокого юзерспейса со всеми его либами и апями. Вещь, безусловно, полезная и спасающая нас от кучи телодвижений, ибо думать о логических уровнях на проводках витой пары во время написания движка своего блога было бы утомительно.
Имеет ли это какое-то отношение к разговору TDD vs "я просто выразил условие" - не очень понятно.
Рождение каждого нового уровня абстракции не такая уж простая и очевидная вещь. Например, если, скажем, дать тебе в руки завод, который может изготовить по твоей схеме печатные платы и микросхемы, изъять из твоей головы знания про современную архитектуру компов (в принципе, каждый программист при написании нового приложения / куска приложения сталкивается именно с этой ситуацией - уровни абстракции еще не изобретены, их предполагается придумать и воплотить самому и поставить задачу - написать приложение, ну сетевой дум, например. Мне будет очень интересно послушать, на основании каких мыслей ты начнешь строить свои уровни абстракции.
В случае с TDD, кстати, эти уровни абстракции как раз будут боле-мене выстраиваться, так как там двигаются сверху вниз - пишут маленький красивый тест для общей хотелки, что-нить типа нажал клавишу на этом компе, на том компе мой игрок свдинулся. Тест в таких случаях принято писать так, как будто у тебя есть под рукой любые абстракции. Код теста поначалу не будет компилироваться, и не надо. Зато мы на этом этапе как раз и будем строить верхний уровень абстракций, не задумываясь о деталях внизу. Как раз то, что Дейкстра прописал.
Если же мы, немного забегая вперед, как ты говоришь в (1 будем думать о каких-то доказательствах того, что это должно работать корректно, то, боюсь, нам придется сразу держать картинку вплоть до логических уровней в витой паре.
(1) - здесь как раз описан способ. Дейкстра там пишет, что нужно подумать о том, как бы мы могли доказать корректность программы, и потом подогнать код так, чтобы он удовлетворял этому мысленному доказательству. При этом, Дейкстра там же оговаривается, что способ работает, очевидно, только для intellectually-manageable programs. Что это такое не очень объясняется, однако приводится пример, что программы с оператором goto таковыми не являются. Соответственно, это совпадает и с моей точкой зрения, что этот способ идеален для маленьких кусочков, но не подходит для больших, когда детали доказательства или условия, или даже их части просто не помещаются в голове.
Если тебе нужна демонстрация этого поинта, то можешь прописать до скучных деталей, как ты руководствуясь своим принципом будешь строить, ну там, софт для биржевой площадки, например (отобранные выше уровни абстракции я тебе, разумеется, здесь возвращаю). Я не очень понимаю, как и в какой очередности будут протекать процессы уточнения условия, создание уровней абстракции, подгонка кода под условие. Не очень понимаю, с чего вообще начать.
А вот в случае с TDD понимаю отлично - например, завести какой-нибудь класс ticker, тикнуть в него ценой, и убедиться, что все слушатели его получили. Потом написать тесты со случаем слушателей на другом компе. Потом написать какие-нибудь пефоманс тесты. етц. ...
> Упомянутые выше code transformations (Refactorings have counterparts called Transformations) не
> связаны с TDD, их можно выполнять не полагаясь на тесты.
Potato-tomato. Transformations/refactorings связаны с TDD ровно так же, как TDD связано с тестами - одно есть часть другого.
Другое, что меня интересует - не хочешь ли ты этой фразой сказать, что и юнит-тестирование вообще такая же бесполезная хрень, как и TDD?
> Вот статья Дейкстры про ограниченность головы on our inability to do much (2)
> Он полагается на использования нашей способности к абстракции. Он пишет об этом (3)
Ты как-то очень интересно аргументируешь свою точку зрения, которая, если я правильно понял "ваше TDD-BDD - неэффективное говно".
Давай я постараюсь прояснить некие моменты твоей позиции.
Я так понимаю, тебе не нравится то, что написание тестов вперед ограничивает твое мышление, заставляя иначе смотреть на проблему. Ты же предпочитаешь "просто писать условие задачи на языке программирования".
Хорошо. Теперь давай разберемся в твоих ссылках.
(2) - всего лишь утверждение, что мы ограничены в своей способности вмещать много инфы. Согласен, принято. Ничему не противоречит.
(3) - абстракции. Замечательно. Абстракции у нас сейчас везде, их кучи этих уровней, от физического с электрончиками до высокого юзерспейса со всеми его либами и апями. Вещь, безусловно, полезная и спасающая нас от кучи телодвижений, ибо думать о логических уровнях на проводках витой пары во время написания движка своего блога было бы утомительно.
Имеет ли это какое-то отношение к разговору TDD vs "я просто выразил условие" - не очень понятно.
Рождение каждого нового уровня абстракции не такая уж простая и очевидная вещь. Например, если, скажем, дать тебе в руки завод, который может изготовить по твоей схеме печатные платы и микросхемы, изъять из твоей головы знания про современную архитектуру компов (в принципе, каждый программист при написании нового приложения / куска приложения сталкивается именно с этой ситуацией - уровни абстракции еще не изобретены, их предполагается придумать и воплотить самому и поставить задачу - написать приложение, ну сетевой дум, например. Мне будет очень интересно послушать, на основании каких мыслей ты начнешь строить свои уровни абстракции.
В случае с TDD, кстати, эти уровни абстракции как раз будут боле-мене выстраиваться, так как там двигаются сверху вниз - пишут маленький красивый тест для общей хотелки, что-нить типа нажал клавишу на этом компе, на том компе мой игрок свдинулся. Тест в таких случаях принято писать так, как будто у тебя есть под рукой любые абстракции. Код теста поначалу не будет компилироваться, и не надо. Зато мы на этом этапе как раз и будем строить верхний уровень абстракций, не задумываясь о деталях внизу. Как раз то, что Дейкстра прописал.
Если же мы, немного забегая вперед, как ты говоришь в (1 будем думать о каких-то доказательствах того, что это должно работать корректно, то, боюсь, нам придется сразу держать картинку вплоть до логических уровней в витой паре.
(1) - здесь как раз описан способ. Дейкстра там пишет, что нужно подумать о том, как бы мы могли доказать корректность программы, и потом подогнать код так, чтобы он удовлетворял этому мысленному доказательству. При этом, Дейкстра там же оговаривается, что способ работает, очевидно, только для intellectually-manageable programs. Что это такое не очень объясняется, однако приводится пример, что программы с оператором goto таковыми не являются. Соответственно, это совпадает и с моей точкой зрения, что этот способ идеален для маленьких кусочков, но не подходит для больших, когда детали доказательства или условия, или даже их части просто не помещаются в голове.
Если тебе нужна демонстрация этого поинта, то можешь прописать до скучных деталей, как ты руководствуясь своим принципом будешь строить, ну там, софт для биржевой площадки, например (отобранные выше уровни абстракции я тебе, разумеется, здесь возвращаю). Я не очень понимаю, как и в какой очередности будут протекать процессы уточнения условия, создание уровней абстракции, подгонка кода под условие. Не очень понимаю, с чего вообще начать.
А вот в случае с TDD понимаю отлично - например, завести какой-нибудь класс ticker, тикнуть в него ценой, и убедиться, что все слушатели его получили. Потом написать тесты со случаем слушателей на другом компе. Потом написать какие-нибудь пефоманс тесты. етц. ...
> Упомянутые выше code transformations (Refactorings have counterparts called Transformations) не
> связаны с TDD, их можно выполнять не полагаясь на тесты.
Potato-tomato. Transformations/refactorings связаны с TDD ровно так же, как TDD связано с тестами - одно есть часть другого.
Другое, что меня интересует - не хочешь ли ты этой фразой сказать, что и юнит-тестирование вообще такая же бесполезная хрень, как и TDD?
я просто записал условие задачи на языке программированияВот тебе условие задачи из реальной жизни : "Сделай чтобы всё было заебись !" (c)
Запиши ка его сходу на языке программирования.
Вот тебе условие задачи из реальной жизни : "Сделай чтобы всё было заебись !" (c)Да, отлично. Этой формулировкой заказчик запрашивает у программиста произвести/создать абстракции, которые удовлетворют заказчика. Т.е. он запрашивает у программиста одну из (жизненно) важных деятельностей программиста:
We all know that the only mental tool by means of which a very finite piece of reasoning can cover a myriad cases is called “abstraction”; as a result the effective exploitation of his powers of abstraction must be regarded as one of the most vital activities of a competent programmer. (c) DijkstraЕсли в ответ на такой запрос программист генерирует finite piece of cases/тестов вместо finite piece of reasoning, которые cover a myriad cases. Тогда программист сработал херово.
Запиши ка его сходу на языке программирования.Последовательность такая:
1. Программист производит/создает/генерирует абстракции. Для вывода абстракций удобно использовать код и ReSharper (как для решения математического уравнения/теоремы использумем преобразования выражений на листе бумаги и карандаш, сейчас, наверное, и компы используют).
2. Записывает их в коде.
(можно повторять многократно с пункта 1)
Для задачки Word Wrap первый шаг оказался пустым.
И показательно, что ребята посадили багу. Говорит нам всего лишь о том, что если пользоваться ТДД совсем бездумно, и не компенсировать это бОльшим количеством тестов, то вы получите условно-работающий код.Если тебе дадут решить уравнение. Ты угадаешь пару корней. Тоже будешь говорить, что ты условно-решил, и надо бОльшее количество попыток угадывания?
Впрочем, твое обдумывание задачи целиком тоже тебе ничего не гарантируетКонечно, гарантирует. У меня строгое доказательство корректности, т.е. соответствию условию задачи. И это даже позволило найти баг в их "условном решении".
зависит от способностей конкретного индивида держать кратинку в голове и ничего не упустить, и при обнаружении багов непонятно что делать, тестов то нету. Загружать картинку опять целиком в мозг?
От способностей зависит, да. Но что делать, если встречаются индивиды, которые за два часа не могут написать набросок программы для инвертации массива. К нам на собеседовании приходил такой. При этом рассказывал о большом опыте. Но я верю, что большое количество людей способны использовать силу абстракций (powers of abstraction). В подходе Дейкстры голова загружается меньше.
И показательно, что ребята посадили багу. Говорит нам всего лишь о том, что если пользоваться ТДД совсем бездумно, и не компенсировать это бОльшим количеством тестов, то вы получите условно-работающий код.Вопрос почему они остановились писать тесты? Ошибка есть, остановились рано. Почему не остановились после первого шага или второго шага? Я им указал на ошибку, пусть не останавливаются и пишут больше тестов. За 10 лет с 2002 года не написали достаточное количество тестов, пусть пишут дальше.
Конечно, гарантирует. У меня строгое доказательство корректности, т.е. соответствию условию задачи. И это даже позволило найти баг в их "условном решении".Строгое доказательство? Ты совсем издеваешься?
Я думаю, эти люди очень заинтересуются твоим способом проведения "строгих доказательств корректности".
Ты сначала из условия задачи построил новое условие вида "может попасть \ может не попасть", но не доказал, что оно идентично исходному.
Потом записал это в код. Опечатался ли ты там в коде, не пропустил ли чего, соответствует ли код условию - доказать в принципе невозможно.
Ни о каком строгом доказательстве речи идти не может. Не обманывай себя и других, пожалуйста.
Скажи, я где-то утверждал, что TDD неминуемо тебя приведет к абсолютно правильному решению задачи? Я утверждал совершенно другие вещи, и нигде не рассматривал TDD как способ построения строго корректных программ.
Если ты меня спросишь, как строить корректные программы - я скажу, что надо комбинировать тесты и твой способ. Замечу, что это нам даст некую приемлемую best-effort корректность, но никак не строгую. А TDD тут уже совершенно вторичен.
И еще. Твой способ и TDD вполне можно применять одновременно. Просто условием задачи каждый раз будет не исходное условие, а только та часть, что проверяется тестом.
Если ты меня спросишь, как строить корректные программы - я скажу, что надо комбинировать тесты и твой способ. Замечу, что это нам даст некую приемлемую best-effort корректность, но никак не строгую. А TDD тут уже совершенно вторичен.
И еще. Твой способ и TDD вполне можно применять одновременно. Просто условием задачи каждый раз будет не исходное условие, а только та часть, что проверяется тестом.
Но я верю, что большое количество людей способны использовать силу абстракций (powers of abstraction). В подходе Дейкстры голова загружается меньше.Я правильно понимаю, что в твоем "строгом доказательстве" ты воспользовался "силой абстракции"? Можешь показать, в каком месте?
И еще. Твой способ и TDD вполне можно применять одновременно. Просто условием задачи каждый раз будет не исходное условие, а только та часть, что проверяется тестом.В моем подходе тесты играют всегда второстепенную роль. А второстепенные вещи не выносят в название методологии. В TDD вынесены. В порядки приоритета идут:
1. Построение системы абстракций.
2. Преобразование кода (code transformation). Тут играют важную роль возможности языка и наличие инструментов типа ReSharper-а.
3. Тесты.
С развитием () значимость третьего пункта падает. Кстати, это уже видно. TDD это идеология 15-летней давности. Тогда инструментов уровня ReSharper-а не было. Сейчас можно многое делать без тестов.
Строгое доказательство? Ты совсем издеваешься?ок, будет время, распишу всё детально
при обнаружении багов непонятно что делать, тестов то нетуИсправлять багу, не внося в код новых ошибок. Для этого обязательно нужны тесты? Мой ответ, нет, тесты отнюдь не всегда обязательны для этого. Строится доказательство того, что правка кода исправляет багу и не приносит новых ошибок.
Тесты не нужны. Я понял, так бы сразу и сказал.
На этом позволю себе закончить дискуссию. Спасибо.
На этом позволю себе закончить дискуссию. Спасибо.
Тесты не нужны. Я понял, так бы сразу и сказал.Я такого не говорил.
Хм. Окей.
На самом деле, мне в любом случае любопытно послушать про твой способ с доказательством через чтение условий и силу абстракций, потому что ты меня в конец запутал и я ничего не понимаю.
С тестами - в каких случаях они тогда, по-твоему, полезны?
На самом деле, мне в любом случае любопытно послушать про твой способ с доказательством через чтение условий и силу абстракций, потому что ты меня в конец запутал и я ничего не понимаю.
С тестами - в каких случаях они тогда, по-твоему, полезны?
Расскажи это этим парням.а этот Uncle Bob оказывается известный авторитет. История становится всё интереснее
. Обещаю (сегодня вечером или завтра) расписать свое решение. Начал прикидывать изложение и нашел еще одну ошибку у них .На самом деле, мне в любом случае любопытно послушать про твой способ с доказательством через чтение условий и силу абстракций, потому что ты меня в конец запутал и я ничего не понимаю.http://dl.dropbox.com/u/82980501/WordWrap/20130304/WordWrap....
С тестами - в каких случаях они тогда, по-твоему, полезны?
не красиво разобьет следующую строку, где _ = space, а columnSize = 3
____!_!_!_!_!_!___!___!_!_!__!_!___
____!_!_!_!_!_!___!___!_!_!__!_!___
а что не так?
MS Word:
Item2
_
!_!@_
!_!@_
!
!__
!_
!_!@_
!
!_!@___
MS Word:
исходно оно было так
я к тому, что всё Ascii-граффити плывет.
ps
и та же VS 100к пробелов при word wrap разобьет на ~1000 строк, а у тебя будет одна строка
___
_!_
!_!
_!_
!_!
!__
_!_
__!
_!_
!__
!_!
___
я к тому, что всё Ascii-граффити плывет.
ps
и та же VS 100к пробелов при word wrap разобьет на ~1000 строк, а у тебя будет одна строка
исходно оно было так
не пойму слово "исходно" в контексте задачи.
я к тому, что всё Ascii-граффити плывет.не пойму, что ты этим хочешь сказать?
VS
да, я смотрел её. В ней пробелы не скрываются, соответственно во второй и последующих строчках в начале получаются пробелы. Я же выбрал в качестве условия, что перенесенные строки не начинаются с пробела, так работаю перечисленные в том посте редакторы.
так работаю перечисленные в том посте редакторы.notepad, например, хавает только один пробел
notepad, например, хавает только один пробелда. Несколько пробелов я пробовал только в Chrome и MS Word.
в Chromeв textarea Chrome оказалось, что ширина знака "!" отличается от "5". "5" на строчке уже не умещается, а "!" еще может влесть.
notepad, например, хавает только один пробелон его не хавает, пробел остается (нажми End просто он остается на первой строчке, т.е. как бы не дает вклад в длину строчки.
подведу итог. Оказалось, что редакторы имеют свои правила:
Chrome, MS Word, Skype, WordPad не переносят любое количество пробелов,
Notepad не переносит только один пробел,
Visual Studio, IE переносят все лишние пробелы.
Естественно, это всё легко реализуется.
Chrome, MS Word, Skype, WordPad не переносят любое количество пробелов,
Notepad не переносит только один пробел,
Visual Studio, IE переносят все лишние пробелы.
Естественно, это всё легко реализуется.
Chrome, MS Word, Skype, WordPad не переносят любое количество пробелов,О
Notepad не переносит только один пробел,
Visual Studio, IE переносят все лишние пробелы.
Естественно, это всё легко реализуется.
, история имеет продолжение. Пусть заказчику отгрузили первый вариант (Chrome и др.). Через некоторое время заказчик заказывает и оплачивает доработку по замене варианта Chrome на вариант Notepad или Visual Studio. Чуть позже я напишу сравнение насколько дорого вносятся изменения при методологии TDD и при методологии Дейкстры. ... Не терпится забежать в перед и спросить. Как вы определите какой объем тестов надо поправить? Вы будете пересматривать все тесты? Или сначала поправите алгоритм (возможно перед этим написав несколько новых тестов а потом будете править красные тесты? Т.е. всё таки работа с тестами будет уже после написания алгоритма? Т.е. водитель Тесты не справился с управлением и передал управление тому, кто способен с этим справиться? Т.е. водитель Тесты не справился с управлением и передал управление тому, кто способен с этим справиться?не употребляй наркотических веществ перед написанием постов на форум, пожалуйста.
Зануда
ну не все же такие
Не терпится забежать в перед и спросить. Как вы определите какой объем тестов надо поправить? Вы будете пересматривать все тесты? Или сначала поправите алгоритм (возможно перед этим написав несколько новых тестов а потом будете править красные тесты?Сначала будут дописаны тесты, которые направлены на выделение требуемого эффекта, что пробелы после изменения разбиваются новым требуемым способом.
А после внесения изменения идет разборка с тестами, которые стали красными. Первопричины может быть две: тест стал красным, потому что внесли ошибку после изменения, тогда код надо еще раз поправить. Либо тест стал красным, потому что он был завязан на конкретную реализацию, тогда необходимо тест переписать и обеспечить, чтобы он был зеленым и на исходном коде и на текущем.
В целом, ситуация полностью аналогична статической проверке. После внесения изменения часть статических правил может начать fail-иться, и необходимо будет проверить - это произошло из-за того, что была внесена ошибка, или это из-за того, что правила были изначально неточно сформулированы.
Плюсуюсь.
(пдф пока не осилил, но он в очереди)
(пдф пока не осилил, но он в очереди)
Плюсуюсь.PDF лучше не смотреть, там IEnumerable головного мозга.
(пдф пока не осилил, но он в очереди)
На самом же деле, спорить по теме абсолютно бессмысленно, ведь .
PDF лучше не смотреть, там IEnumerable головного мозга.тут ты, кстати, зря.
Описание и код вполне хороши, и, в целом, в духе TDD: начинаем с простого и пишем только то, что необходимо для получения результата.
ps
И это уже больше вопрос религиозный (и зависит от способа использования кода): стоит ли в примере заменить рекурсию на цикл, а склейку IEnumerable на заполнение List-а?
И это уже больше вопрос религиозный (и зависит от способа использования кода): стоит ли в примере заменить рекурсию на цикл, а склейку IEnumerable на заполнение List-а?Код с циклом очень часто и записывается короче, и читается проще. Многие ленятся и не замечают этого.
Проверить формальную работоспособность кода, написанного под такую простыню, не представляется возможным.
Ровно как и строить подобные "доказательства" под рефакторинг, который может затрагивать десятки файлов.
Я уверен, что посылку автора понял правильно - см. ссылку в моём сообщении.
Проверить формальную работоспособность кода, написанного под такую простыню, не представляется возможным.Спорное утверждение.
Доказательство мат. теорем выглядит также, и имеет при этом формальную верифицируемость.
Доказательство мат. теорем выглядит также, и имеет при этом формальную верифицируемость.Мат. теорем меньше, чем кода в одном крупном проекте; и возятся с ними годами.
Мат. теорем меньше, чем кода в одном крупном проекте; и возятся с ними годами.Дейкстра сравнивает код не с теоремами, а с доказательствами теорем:
On the Structure of Convincing Programs
The technique of mastering complexity has been known since ancient times: Divide et impera ("Divide and rule"). The analogy between proof construction and program construction is, again, striking. In both cases, the available starting points are given (axioms and existing theory versus primitives and available library programs in both cases the goal is given (the theorem to be proved versus the desired performance in both cases the complexity is tackled by division into parts (lemmas versus subprograms and procedures).
http://hp.fciencias.unam.mx/~jloa/CC/dijkstra1i.html
Третий аргумент основывается на конструктивном подходе к проблеме корректности программ. ... Единственный эффективный способ значительно поднять уровень доверия к программам — предоставить убедительное доказательство их корректности. Но не следует сначала писать программу, а затем доказывать ее корректность, потому что тогда требование предоставить доказательство только увеличит обузу бедного программиста. Наоборот, программист должен позволять расти доказательству корректности и программе совместно. Третий аргумент в основном основывается на следующем наблюдении. Если кто-то сначала спросит себя, какова будет структура убедительного доказательства и, найдя ее, затем построит программу, удовлетворяющую требованиям этого доказательства, тогда эти заботы о корректности обернутся весьма эффективным эвристическим указателем пути. По определению этот подход применим только в случае, если мы ограничиваемся интеллектуально-управляемыми программами, но он дает нам эффективные средства для поиска удовлетворительного решения среди них.
http://club.shelek.ru/viewart.php?id=155
А объем доказательств уже сравним с объемом кода.
И большинство частей проектов следует сравнивать не с уникальными (новыми) теоремами, а с типовыми задачками, например, решить уравнение — найти корни и предъявить доказательство того, что других нет. Доказательства строгие, но с ними справляется один студент в течении получаса.
psIEnumerable хорош тем, что компилятор контролирует, что return есть в каждой ветке if/else. При написании и внесении изменений это помогает. При заполнении List-а такого нет. Вариант IEnumerable похож на read only состояние:
И это уже больше вопрос религиозный (и зависит от способа использования кода): стоит ли в примере заменить рекурсию на цикл, а склейку IEnumerable на заполнение List-а?
int a;
if (someCondition)
{
a = b + c;
}
else
{
a = d + e;
}
Console.WriteLine(a);
в то время как заполнение List-а похоже на изменяемое состояние:
int a = 0;
if (someCondition)
{
a = b + c;
}
else
{
a = d + e;
}
Console.WriteLine(a);
С натяжкой, но допустим. Но чем лучше рекурсия?
Попробуйте переписать это через цикл.
Имхо, будет немало работы с изменяемым состоянием.
static IEnumerable<Tuple<string, string>> Wrap(string s, int columnSize)
{
if (columnSize <= 0) throw new ArgumentOutOfRangeException("columnSize");
if (columnSize >= s.Length) return Enumerable.Repeat(Tuple.Create(s, string.Empty 1);
var line = s.Substring(0, columnSize);
if (s[columnSize] == ' ')
{
var rightSymbols = s.Substring(columnSize);
var trimedRightSymbols = rightSymbols.TrimStart(' ');
return trimedRightSymbols == string.Empty
? Enumerable.Repeat(Tuple.Create(line, rightSymbols 1)
: Enumerable.Repeat(
Tuple.Create(
line, rightSymbols.Substring(0, rightSymbols.Length - trimedRightSymbols.Length
1).Concat(Wrap(trimedRightSymbols, columnSize;
}
else
{
var lastSpacePosition = line.LastIndexOf(' ');
return lastSpacePosition >= 0
? Enumerable.Repeat(Tuple.Create(s.Substring(0, lastSpacePosition + 1 string.Empty 1)
.Concat(Wrap(s.Substring(lastSpacePosition + 1 columnSize
: Enumerable.Repeat(Tuple.Create(line, string.Empty 1)
.Concat(Wrap(s.Substring(columnSize columnSize;
}
}
Имхо, будет немало работы с изменяемым состоянием.
yield же есть
да, неплохо
static IEnumerable<Tuple<string, string>> Wrap2(string s, int columnSize)
{
if (columnSize <= 0) throw new ArgumentOutOfRangeException("columnSize");
while (true)
{
if (columnSize >= s.Length)
{
yield return Tuple.Create(s, string.Empty);
yield break;
}
var line = s.Substring(0, columnSize);
string newS;
if (s[columnSize] == ' ')
{
var rightSymbols = s.Substring(columnSize);
var trimedRightSymbols = rightSymbols.TrimStart(' ');
if (trimedRightSymbols == string.Empty)
{
yield return Tuple.Create(line, rightSymbols);
yield break;
}
else
{
yield return Tuple.Create(
line, rightSymbols.Substring(0, rightSymbols.Length - trimedRightSymbols.Length;
newS = trimedRightSymbols;
}
}
else
{
var lastSpacePosition = line.LastIndexOf(' ');
if (lastSpacePosition >= 0)
{
yield return Tuple.Create(s.Substring(0, lastSpacePosition + 1 string.Empty);
newS = s.Substring(lastSpacePosition + 1);
}
else
{
yield return Tuple.Create(line, string.Empty);
newS = s.Substring(columnSize);
}
}
s = newS;
}
}
правда строчек на 75% больше
Сначала будут дописаны тесты, которые направлены на выделение требуемого эффекта, что пробелы после изменения разбиваются новым требуемым способом.Таким образом, полезный выхлоп от тестов, оставшихся от предыдущего релиза, это только то, что выделено жирным, так? Какая от них еще польза? Больше они нам ни чем не помогают?
А после внесения изменения идет разборка с тестами, которые стали красными. Первопричины может быть две: тест стал красным, потому что внесли ошибку после изменения, тогда код надо еще раз поправить. Либо тест стал красным, потому что он был завязан на конкретную реализацию, тогда необходимо тест переписать и обеспечить, чтобы он был зеленым и на исходном коде и на текущем.
О , история имеет продолжение. Пусть заказчику отгрузили первый вариант (Chrome и др.). Через некоторое время заказчик заказывает и оплачивает доработку по замене варианта Chrome на вариант Notepad или Visual Studio. Чуть позже я напишу сравнение насколько дорого вносятся изменения при методологии TDD и при методологии Дейкстры. ..как обещал http://dl.dropbox.com/u/82980501/WordWrap/20130308/WordWrapC...
зачем так жестоко new string(' ', 1) ?
думаешь лучше заменить на s.Substring(columnSize, 1) или " "?
пробел нагляднее
В целом, ситуация полностью аналогична статической проверке. После внесения изменения часть статических правил может начать fail-иться, и необходимо будет проверить - это произошло из-за того, что была внесена ошибка, или это из-за того, что правила были изначально неточно сформулированы.Аналогия получается только при поверхностном рассмотрении. Если же рассмотреть подробнее, то всё по-другому. Статические правила образуют множество векторов в трехмерном пространстве (File, Ln, Col). Этого множества векторов достаточно (*1) для выполнения большинства задач при development-е и при maintenance-е программного обеспечения. Множество векторов позволяет to find semantically meaningful decompositions of programs, where the decompositions consist of elements that are not textually contiguous (*2). Позволяет выделять фрагменты кода, которые соответствуют subset-ам of a program's behavior, которые интересны при выполнении фиксированной задачи. Множество векторов часто позволяет выстроить цепочку из мелких шагов для внесения изменений. Каждый шаг либо полностью делается автоматическим рефакторингом, либо настолько мелкий, что умещается в ограниченную голову человека, и человек может это проконтролировать с хорошей степенью уверенности.
Пример Word Wrap Change Request a>. Читаем в CR-е раздел “Текущая ситуация”. Используя информацию из этого раздела и посредством навигации по множеству векторов Value Origin, находим фрагменты кода, которые соответствуют Change Request-у. Вносим изменения в код. Запускаем два три раза, чтобы проверить опечатки, и всё, задача выполнена.
Как этот Change Request выполнялся бы по TDD? Информация из раздела “Текущая ситуация” не используется. (1) Пишем новые тесты на основании раздела “Предлагаемые изменения”. Запускаем. Новые тесты – красные. Что дальше? Допустим, с момента написания метода Wrap прошло полгода, или его писал другой разработчик. (2) Придется читать и понимать весь метод Wrap. Человек анализирует и находит места, в которые надо внести изменения. Вносим изменения. Новые тесты стали зелеными. Часть старых тестов стала красными. (3) Анализируем каждый красный тест на предмет того, что он относится к описанию в разделе “Текущая ситуация” или нет. Если, да, то тест удаляем.
Таким образом, шаги (1 (2 (3) это дополнительные (лишние) выполняемые человеком действия, которые приносит TDD.
(*1) При соблюдении правильного и естественного стиля.
(*2) Интересный вопрос, code coverage по тестам может тоже это позволяет? Видел инструменты близкие к этому. Надо подумать…..
Статические правила образуют множество векторов в трехмерном пространстве (File, Ln, Col).Тесты образуют множество векторов в трехмерном пространстве (вход, код, выход благодаря тому, что (вход, код, выход) можно разбить на (вход, код1, выход1 (вход2, код2, выход где выход1==вход2, а код1+код2=код.
Дальше все рассуждения аналогичны твоим.
что такое "вход" и "выход"? Дай определение.
что такое "вход" и "выход"? Дай определение.последовательность байт подаваемая на вход коду, и последовательность байт получаемая от кода.
ps
Если код имеет несколько логических потоков управления, то последовательностей на вход и выход будет несколько, а не по одной.
Как в твоем пространстве векторов выполнить следующие?
1. Встать на начало вектора.
2. Дать машине команду снавигироваться в конец вектора.
3. Оказаться в конце вектора.
1. Встать на начало вектора.
2. Дать машине команду снавигироваться в конец вектора.
3. Оказаться в конце вектора.
чем третье от второго отличается?
ну в случае обычного Go To Definition второе это выбрать пункт меню, а третье это курсор попал в определенную позицию.
Возьмем код и способ его декомпозиции.
1. загрузить случайную (или запомненную ранее) последовательность байт
2. взять декомпозированный код и последовательно применить к начальной последовательности
3. взять последний код из декомпозиции и подгрузить случайную (или запомненную ранее) последовательность байт
1. загрузить случайную (или запомненную ранее) последовательность байт
2. взять декомпозированный код и последовательно применить к начальной последовательности
3. взять последний код из декомпозиции и подгрузить случайную (или запомненную ранее) последовательность байт
случайную (или запомненную ранеев пространстве (File, Ln, Col) ни каких случайностей и ранних запоминаний нету
Короче, давай покажи на примере, как твое пространство помогает реализовать WordWrap Change Request Я для своего расписал выше.
для начала хочется видеть, как происходит поиск ошибки или опечатки в твоем случае
например, что будет, если в исходном коде вместо строки:
line, rightSymbols.Substring(0, rightSymbols.Length - trimedRightSymbols.Length
по каким-то причинам оказалась строка
line, rightSymbols.Substring(1, rightSymbols.Length - trimedRightSymbols.Length
?
например, что будет, если в исходном коде вместо строки:
line, rightSymbols.Substring(0, rightSymbols.Length - trimedRightSymbols.Length
по каким-то причинам оказалась строка
line, rightSymbols.Substring(1, rightSymbols.Length - trimedRightSymbols.Length
?
Запускаем два три раза, чтобы проверить опечатки, и всё, задача выполнена.
Запускаем два три раза, чтобы проверить опечатки, и всё, задача выполнена.на каких данных? можно же привести примеры и более тонких ошибок/опечаток, которые не видны на первых попавшихся данных.
например, следующая опечатка
if (columnSize < 0) throw new ArgumentOutOfRangeException("columnSize");
довольно серьезна, т.к. приводит к зацикливанию кода, а возникает только если какой-то другой алгоритм или человек явно или косвенно передал вырожденные настройки.
на каких данных?данные для интересных веток написанного кода, в данном случае я прогонял для Wrap("wor d word", 5)
более тонких ошибок/опечатокИдеального механизма отлова всех ошибок человечество пока не знает. И тесты таковым тоже не являются. Что тут можно сделать? Вводить какую-то метрику качества программного обеспечения? Уже тут будет затык. Нет хороших метрик. Есть только внутренне ощущение программистов, что код работает, и они в состоянии управляться с кодом, либо что код уходит из-под их контроля (требует много время на простые вещи). Например, после прочтения статьи Uncle Bob-а у меня не создалось впечатление, что задача выполнена. Более того, не было понятно насколько проделанные действия далеки/близки от решения. А вот по моему коду можно восстановить убедительные рассуждения (для непростых моментов надо оставлять комментарии в коде).
Лучше потратить усилия программиста на внимательное написание кода, чем на написание тестов. Можно и то и другое, но это бюджет увеличивает. Причем прирост надежности от внимательности будет выше, чем от написания тестов.
Идеального механизма отлова всех ошибок человечество пока не знает.доказательство правильности - ты же об этом до этого сам об этом упоминал.
один из пунктов доказательства правильности решения - это проверка на полноту: что все варианты входа обрабатываются адекватно требуемому решению.
доказательство правильностиА если в доказательстве ошибка? Разве твой пример ошибки это не ошибка доказательства?
А если в доказательстве ошибка? Разве твой пример ошибки это не ошибка доказательства?конечно же в доказательствах и расчетах могут быть ошибки. Именно поэтому расчеты и доказательства постоянно перепроверяют: приблизительным расчетами, обратными, проверками в отдельных точках, проверками на полноту и т.д.
Соответственно, вопрос какие есть способы перепроверки твоего доказательства?
что проще догадаться написать тест:
или догадаться и найти ошибку в строчке if (columnSize < 0) throw new ArgumentOutOfRangeException("columnSize"); ?
[ExpectedException(typeof(ArgumentOutOfRangeException]
public void BlaBlaBla
{
Wrapper.Wrap("tes test", 0);
}
или догадаться и найти ошибку в строчке if (columnSize < 0) throw new ArgumentOutOfRangeException("columnSize"); ?
что проще догадаться написать тест:конечно же тест. С этим даже простая автоматика справится.
ты какой автоматикой для этого пользуешься?
сейчас младшим научным тестировщиком
конечно же тест. С этим даже простая автоматика справится.И так, ни какой автоматики у тебя нет. Теперь сравним человеческие усилия.
Если не пишем тест. Я меняю один символ 5->0
Wrap("wor d word", 5);
Wrap("wor d word", 0);
Запускаю. Получаю StackOverflowException. Понимаю, что для columnSize==0 задача не имеет смысла. Меняю код на if (columnSize < 0) throw new ArgumentOutOfRangeException("columnSize");. Вопрос решен.
Если пишем тесты. Человек придумывает как назвать тест
, печатает СolumnSizeIsZero.
[Test]
public void СolumnSizeIsZero
{
}
Далее пытаемся написать тест

что указывать в качестве expected значения? Какие дальнейшие действия младшего научного тестировщика?
А вот что у нас на Python-е. В интернете можно найти попытки решить эту задачку на разных языках, в частности, на Python-е.
http://mentalpandiculation.com/2011/01/word-wrap-kata-in-pyt...
Забавно, что тест, который не прошел Uncle Bob: wrap("wor d word", 5 этот код проходит. Не уж то тезис о том, что программисты на Python-е умнее программистов на Java подтверждается? Сравниваем коды. Оказывается в коде на Python опечатка в 8-ой строчке. С этой опечаткой код вообще не рабочий, вот для такого случая wrap("wor d word", 5) выдается полная хрень. Исправляем опечатку, но теперь не проходит тест wrap("wor d word", 5). Т.е. задача не решена!
Забавно после этого читать философствования автора:
Удивительно, как быстро собирается неправильный алгоритм, когда пишем правильный тест. Хотя что тут удивительного? Неправильный алгоритм я быстро напишу вообще без тестов.
Чем больше я вижу кода, написанного по методологии TDD/BDD, тем больше понимаю, что это Путь разработки херового софта.
http://mentalpandiculation.com/2011/01/word-wrap-kata-in-pyt...
Забавно, что тест, который не прошел Uncle Bob: wrap("wor d word", 5 этот код проходит. Не уж то тезис о том, что программисты на Python-е умнее программистов на Java подтверждается? Сравниваем коды. Оказывается в коде на Python опечатка в 8-ой строчке. С этой опечаткой код вообще не рабочий, вот для такого случая wrap("wor d word", 5) выдается полная хрень. Исправляем опечатку, но теперь не проходит тест wrap("wor d word", 5). Т.е. задача не решена!
Забавно после этого читать философствования автора:
It’s fascinating how quickly the algorithm starts to come together when you write the correct test.
Удивительно, как быстро собирается неправильный алгоритм, когда пишем правильный тест. Хотя что тут удивительного? Неправильный алгоритм я быстро напишу вообще без тестов.
The more I do TDD/BDD, the more I realize that it is *THE* way to develop software, especially if you’re working in a dynamic language.
Чем больше я вижу кода, написанного по методологии TDD/BDD, тем больше понимаю, что это Путь разработки херового софта.
что указывать в качестве expected значения?
[TestMethod]
[ExpectedException(typeof(ArgumentException]
public void ColumnSizeIsZero
{
Wrap(" ", 0).ToArray;
}
[ExpectedException(typeof(ArgumentException]если ты уже знаешь что должен быть ArgumentException, то мои действия сокращаются буквально до:
Меняю код на if (columnSize < 0) throw new ArgumentOutOfRangeException("columnSize");. Вопрос решен.Код throw находим через команду Function Exits в ReSharper-е.
Возни с тестом уже больше. Более того, тест остается. Тем самым, в коде остается дублирование информации о том, какое поведение при columnSize==0.
Более того, тест остается. Тем самым, в коде остается дублирование информации о том, какое поведение при columnSize==0.Ровно как написано в википедии:
Tests become part of the maintenance overhead of a project.
http://en.wikipedia.org/wiki/Test-driven_development#Shortco...
Тем самым, в коде остается дублирование информации о том, какое поведение при columnSize==0.дублирование информации на критических местах - это хорошо. Это обеспечивает устойчивость при изменениях, некорректному изменению сложнее пройти.
ps
минус в твоем подходе в том, что код нельзя передать допиливать младшему научному программисту, который относится к коду не настолько аккуратно, как ты.
дублирование информации на критических местах - это хорошо. Это обеспечивает устойчивость при изменениях. некорректному изменению сложнее пройти.Однозначно говорить хорошо/плохо тут нельзя. В реальных проектах обычно в таких ситуациях некоторое trade-off решение.
минус в твоем подходе в том, что код нельзя передать допиливать младшему научному программисту, который относится к коду не настолько аккуратно, как ты.
Как раз наоборот, главная мотивация у младшего научного программиста это его профессиональный рост. Передаешь ему код, он по нему учится, естественно, с возможностью обратной связи между вами (в пределах разумного, конечно). Ревью проводишь. Он доволен тем, что его главная мотивация удовлетворяется, и действует в интересах проекта (в частности, старается, чтобы код был правильным).
Ревью проводишь.свой-то код читать лень, а уж чужой

вот такая конструкция Enumerable.Repeat(x, 1) действительно лучше, чем new[]{x} ?
public static IEnumerable<TResult> Repeat<TResult>(TResult element, int count)
{
if (count < 0)
throw Error.ArgumentOutOfRange("count");
else
return Enumerable.RepeatIterator<TResult>(element, count);
}
private static IEnumerable<TResult> RepeatIterator<TResult>(TResult element, int count)
{
for (int i = 0; i < count; ++i)
yield return element;
}
код я и так знаю.
Вопрос был: действительно ли он лучше?
Вопрос был: действительно ли он лучше?
а зачем создавать массив?
а зачем создавать массив?создание массива vs создание объекта (yield создает объект)
да, наверное существенной разницы нет
Но чем лучше рекурсия?Оказывается с помощью можно оставить с виду рекурсивную запись, однако в рантайме она будет не рекурсивная.
Вот код с минимальными изменениями переписывается в не рекурсивный вид:
public static void Main2
{
Console.WriteLine(string.Join(Environment.NewLine, Wrap("wor d word ", 5).ToEnumerable.Select(_ => _.Item1;
}
static Chain<Tuple<string, string>> Wrap(string s, int columnSize)
{
if (columnSize <= 0) throw new ArgumentOutOfRangeException("columnSize");
if (columnSize >= s.Length) return Tuple.Create(s, string.Empty).EndChain;
var line = s.Substring(0, columnSize);
if (s[columnSize] == ' ')
{
var rightSymbols = s.Substring(columnSize);
var trimedRightSymbols = rightSymbols.TrimStart(' ');
return trimedRightSymbols == string.Empty
? Tuple.Create(line, rightSymbols).EndChain
: Tuple.Create(line, rightSymbols.Substring(0, rightSymbols.Length - trimedRightSymbols.Length
.Concat => Wrap(trimedRightSymbols, columnSize;
}
else
{
var lastSpacePosition = line.LastIndexOf(' ');
return lastSpacePosition >= 0
? Tuple.Create(s.Substring(0, lastSpacePosition + 1 string.Empty)
.Concat => Wrap(s.Substring(lastSpacePosition + 1 columnSize
: Tuple.Create(line, string.Empty)
.Concat => Wrap(s.Substring(columnSize columnSize;
}
}
где
delegate Tuple<T, Option<Chain<T>>> Chain<T>
public static Chain<T> EndChain<T>(this T arg)
{
return => Tuple.Create(arg, new Option<Chain<T>>
}
public static Chain<T> Concat<T>(this T arg, Func<Chain<T>> func)
{
return => Tuple.Create(arg, func.AsOption;
}
public static IEnumerable<T> ToEnumerable<T>(this Chain<T> it)
{
while (true)
{
var tuple = it;
yield return tuple.Item1;
if (!tuple.Item2.HasValue) yield break;
it = tuple.Item2.Value;
}
}
Вот такая "магия" ленивости.
Оказывается с помощью Chain можно оставить с виду рекурсивную запись, однако в рантайме она будет не рекурсивная.имхо, рекурентность хуже именно с точки зрения записи, а не только с точки зрения выполнения.
Для рекурентной записи
сложнее вычисляется инвариант итерации,
сложнее доказывается, что алгоритм завершается,
сложнее отлаживаться,
сложнее передавать параметры,
сложнее делать неоднородные итерации
и т.д.
имхо, рекурентность хуже именно с точки зрения записи, а не только с точки зрения выполнения.
Для Wrap эта запись естественна при .
сложнее доказывается, что алгоритм завершается,ээ? рекрсия и индукция побратимы. Как раз для рекурсии удобно доказывать подобное, а для циклов - преобразованием к рекурсии.
ээ? рекрсия и индукция побратимы.да, побратимы. но требуется разное кол-во вычислительных ресурсов, чтобы доказать конечность.
например, для следующего цикла конечность доказывается через анализ одной строчки кода
for (var i = 0; i < 10; ++i)
{
..
}
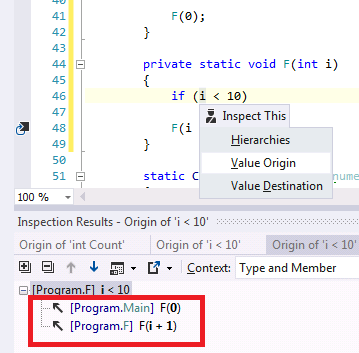
а следующий код требует полного анализа с построением графа вызовов:
F(0);
void F(int i)
{
if (i < 10)
return;
..
F(i + 1);
}
for (var i = 0; i < 10; ++i) { .. }видишь ли, проблема итеративного стиля в его мутабельности
for (var i = 0; i < 10; ++i) {
if (s % i-=2)
break;
}
И вот уже анализировать стало веселее
И вот уже анализировать стало веселеетак получается, что циклы делятся на те, которые анализировать легко, и которые тяжело, а рекурсию любую тяжело анализировать.
При этом в коде с хорошим стилем, циклы бывают только первого рода, которые анализируются легко.
> проблема итеративного стиля в его мутабельности
если ты думаешь, что if (s % i-=2) проще анализировать в рекурсивном коде, то ты ошибаешься.
например, для следующего цикла конечность доказывается через анализ одной строчки кодаанализ одной строчки, говоришь, ну ну
for (var i = 0; i < 10; ++i)
{
--i;
}
а рекурсию любую тяжело анализировать.а ты попробуй писать рекурсию не на си, а скажем на хаскеле
а следующий код требует полного анализа с построением графа вызовов:То есть нажать одну кнопку?
а ты попробуй писать рекурсию не на си, а скажем на хаскелебудет всё также тяжело анализировать.
Следующий код вполне иммутабелен, и с точностью до синтаксиса 1 в 1 переписывается на хаскеле, при этом проанализировать его на конечность всё также почти невозможно.
F(0, 11);
R F(int i, int s)
{
if (i < 10)
return R(0);
var i1 = i - 2;
if s % i1) == 0)
return R(1);
..
return F(i1 + 1);
}
То есть нажать одну кнопку?проблема не в получении графа, а в выделении инварианта из графа
так получается, что циклы делятся на те, которые анализировать легко, и которые тяжело, а рекурсию любую тяжело анализировать.Для рекурсивного кода тоже есть хороший стиль, который легко анализировать. Называется структурная рекурсия. Я писал на двух языках, где компилятор делает проверку завершимости, - ATS и Idris, там сделали просто: либо делаешь рекурсию структурной, либо явно указываешь натуральный параметр, который с каждым рекурсивным вызовом уменьшается. На практике такого подхода вполне хватает, чтобы писать тотальные программы, при этом проверка на завершимость элементарна.
При этом в коде с хорошим стилем, циклы бывают только первого рода, которые анализируются легко.
проблема не в получении графа, а в выделении инварианта из графачего?
проблема не в получении графа, а в выделении инварианта из графана картинке явно видно, что в функцию входим только либо с 0, либо с i+1, и i ни где не мутирует, этого не достаточно для доказательства?
Называется структурная рекурсия.afaik, она все равно требует для анализа больше ресурсов, чем цикл.
afaik, она все равно требует для анализа больше ресурсов, чем цикл.Да нет, цикл требует куда больше. Просто ты используешь цикл for как частный ограниченный случай функции высшего порядка. Для функции foreach (или list comprehension как аналог) тоже очевидно и просто доказываются условия выхода. Если же ты будешь рассматривать фор во всей полноте, не упрощённо, то даже с пустым телом цикла, ты можешь составить такую конструкцию, о работе которой нужно будет немало подумать
Следующий код вполне иммутабелен, и с точностью до синтаксиса 1 в 1 переписывается на хаскеле, при этом проанализировать его на конечность всё также почти невозможно.Два раза нажать кнопку, и дальше последовательность простых шагов, и всё доказывается.
на картинке явно видно, что в функцию входим только либо с 0, либо с i+1, и i ни где не мутирует, этого не достаточно для доказательства?т.е. в итоге, для доказательства конечности рекурсия сводится к циклическому графу.
Так может все-таки логичнее сразу в коде записывать, что выполнение циклическое.
т.е. в итоге, для доказательства конечности рекурсия сводится к циклическому графу.Естественно, да, если ровно твой случай. Но поинт был в том, что разница мала — всего лишь нажатие одной кнопки.
Так может все-таки логичнее сразу в коде записывать, что выполнение циклическое.
А вот если вернуться к :
while (true)
{
string newS;
newS = ..... длинное бла-бла-бла....
s = newS;
}
Тут уже нет встроенной в язык краткой записи. Более того, получаем mutable состояние, которое, как известно, плохо сказывается на последующих code transformation-ах.
Причем код через Chain хорошо поддается декомпозиции, например, можно выделить в отдельный метод вот такой кусок кода:
Попробуй тоже самое сделать в коде с циклом. Не получится.
static Chain<Tuple<string, string>> Wrap(string s, int columnSize)
{
if (columnSize <= 0) throw new ArgumentOutOfRangeException("columnSize");
if (columnSize >= s.Length) return Tuple.Create(s, string.Empty).EndChain;
var line = s.Substring(0, columnSize);
if (s[columnSize] == ' ')
{
return SpaceCase(s, columnSize, line);
}
else
{
var lastSpacePosition = line.LastIndexOf(' ');
return lastSpacePosition >= 0
? Tuple.Create(s.Substring(0, lastSpacePosition + 1 string.Empty)
.Concat => Wrap(s.Substring(lastSpacePosition + 1 columnSize
: Tuple.Create(line, string.Empty)
.Concat => Wrap(s.Substring(columnSize columnSize;
}
}
static Chain<Tuple<string, string>> SpaceCase(string s, int columnSize, string line)
{
var rightSymbols = s.Substring(columnSize);
var trimedRightSymbols = rightSymbols.TrimStart(' ');
return trimedRightSymbols == string.Empty
? Tuple.Create(line, rightSymbols).EndChain
: Tuple.Create(line, rightSymbols.Substring(0, rightSymbols.Length - trimedRightSymbols.Length
.Concat => Wrap(trimedRightSymbols, columnSize;
}
Попробуй тоже самое сделать в коде с циклом. Не получится.
Еще можно привести пример того, как Chain хорошо сочетается (в отличии от циклов) с другими функциональными фишками. Например, Option/Choice переменная внутри цикла.
например, для следующего цикла конечность доказывается через анализ одной строчки кода
for (var i = 0; i < 10; ++i)
{
i = 0;
}
имхо, рекурентность хуже именно с точки зрения записи, а не только с точки зрения выполнения.Кто тебе дал такую рекурсию? Выбрось ее немедленно. Никогда больше не бери в руки рекурсию, для которой все так сложно.
Для рекурентной записи
сложнее вычисляется инвариант итерации,
сложнее доказывается, что алгоритм завершается,
сложнее отлаживаться,
сложнее передавать параметры,
сложнее делать неоднородные итерации
и т.д.
так получается, что рекурсия делится на ту, которую анализировать легко, и которую тяжело, а цикл любой тяжело анализировать.fixed
а простой автомат, проверяющий есть ли другие изменения переменой циклы - говорит имеем ли мы дело с хорошими циклами - анализ, которых делается элементарно, или с плохими - анализ, которых аналогичен анализу рекурсии
Ты уже подписался на анализ по одной строчке, не отлынивай!
ты сейчас ерничаешь, вместо того, чтобы задать себе простой рациональный вопрос: "откуда я знаю, что я знаю, что рекурсия проще, чем цикл?"
а простой автомат, проверяющий есть ли другие изменения переменой циклы - говорит имеем ли мы дело с хорошими циклами - анализ, которых делается элементарно, или с плохими - анализ, которых аналогичен анализу рекурсии
for(int i = 0; i < 10; i = f(i;
Анализируй!
Ты уже подписался на анализ по одной строчке, не отлынивай!тогда уж сразу бы давал код с синтаксическими ошибками в других строках - что мелочиться-то..
Ну да, я редко задаю себе вопросы, ответы на которые мне известны. 
Давай сузим предмет разговора анализом корректного кода. Выбор строчки за тобой. 
Ну да, я редко задаю себе вопросы, ответы на которые мне известны.чем это отличается от позиции adm-а или другого упоротого фанатика? Им тоже все ответы заранее известны
Ты прав, несомненно! 
имхо, рекурентность хуже именно с точки зрения записи, а не только с точки зрения выполнения.запись через цикл или через procedure call mechanism это лишь вопрос наличия синтаксического сахара:
Для рекурентной записи
сложнее вычисляется инвариант итерации,
сложнее доказывается, что алгоритм завершается,
сложнее отлаживаться,
сложнее передавать параметры,
сложнее делать неоднородные итерации
и т.д.
One reason that the distinction between process and procedure may be confusing is that most implementations of common languages (including Ada, Pascal, and C) are designed in such a way that the interpretation of any recursive procedure consumes an amount of memory that grows with the number of procedure calls, even when the process described is, in principle, iterative. As a consequence, these languages can describe iterative processes only by resorting to special-purpose ``looping constructs'' such as do, repeat, until, for, and while. The implementation of Scheme we shall consider in chapter 5 does not share this defect. It will execute an iterative process in constant space, even if the iterative process is described by a recursive procedure. An implementation with this property is called tail-recursive. With a tail-recursive implementation, iteration can be expressed using the ordinary procedure call mechanism, so that special iteration constructs are useful only as syntactic sugar.
http://mitpress.mit.edu/sicp/full-text/book/book-Z-H-11.html...
The implementation of Scheme we shall consider in chapter 5 does not share this defect. It will execute an iterative process in constant space, even if the iterative process is described by a recursive procedure. An implementation with this property is called tail-recursive. With a tail-recursive implementation, iteration can be expressed using the ordinary procedure call mechanism, so that special iteration constructs are useful only as syntactic sugar.А Chain показала, что этот defect можно обойти и без реализации tail-recursive.
тесты не нужны. Я понял, так бы сразу и сказал.Оказывается Кнут уже сформулировал ответ за меня
:As to your real question, the idea of immediate compilation and "unit tests" appeals to me only rarely, when I’m feeling my way in a totally unknown environment and need feedback about what works and what doesn’t. Otherwise, lots of time is wasted on activities that I simply never need to perform or even think about. Nothing needs to be "mocked up."
http://www.informit.com/articles/article.aspx?p=1193856
С этим куском фразы я соглашусь и даже поставлю плюсик.
Моя проблема в том, что я постоянно работаю в таком энвайронменте. Лезу в незнакомый код. Вкручиваю новую либу. Дописываю кучу кода. Рефакторю что-то с неявными контрактами.
Очевидно, что если есть нечто, что может тебе практически немедленно сказать, работает твоя система или нет - это огромное подспорье и ускоряет тестирование в разы.
Заодно, как я пытался показать примером выше, помогает с разработкой логики(я отнюдь не утверждаю, что полностью заменяет вам ваш мозг) и рефайнит паблик интерфейс.
Конечно, если оказывается, что написание тестов занимает у вас кучу времени, а на тестирование\дебаггинг вы время вообще не тратите, то вам вообще какие-либо автоматические тесты ни к чему.
Поэтому я охотно верю, что когда Кнут пишет алгоритм сортировки в его любимом ММИКсе, то юнит тестирование ему только мешает. Ему просто нечего юниттестировать, так как все компоненты окружения досконально известны.
Моя проблема в том, что я постоянно работаю в таком энвайронменте. Лезу в незнакомый код. Вкручиваю новую либу. Дописываю кучу кода. Рефакторю что-то с неявными контрактами.
Очевидно, что если есть нечто, что может тебе практически немедленно сказать, работает твоя система или нет - это огромное подспорье и ускоряет тестирование в разы.
Заодно, как я пытался показать примером выше, помогает с разработкой логики(я отнюдь не утверждаю, что полностью заменяет вам ваш мозг) и рефайнит паблик интерфейс.
Конечно, если оказывается, что написание тестов занимает у вас кучу времени, а на тестирование\дебаггинг вы время вообще не тратите, то вам вообще какие-либо автоматические тесты ни к чему.
Поэтому я охотно верю, что когда Кнут пишет алгоритм сортировки в его любимом ММИКсе, то юнит тестирование ему только мешает. Ему просто нечего юниттестировать, так как все компоненты окружения досконально известны.
нечто, что может тебе практически немедленно сказать, работает твоя система или неттесты (сами по себе без ) могут сказать, что система не работает. Но тесты совершенно не адыкватны, чтобы сказать, что система работает. Зеленая полоска (если ее отождествлять с утверждением, что система работает) — это просто самообман. А вот граф зависимостей в исходном коде (построенный на основе статической типизации) является полным (если не использовался рефлекшен и т.п.). На основе этой полноты можно строго доказывать, что изменения не приносят новых ошибок. Подавляющее число реально требуемых изменений представимы в виде последовательности маленьких формальных преобразований кода. Эффект от каждого такого шага полностью предсказуем, и умещается в ограниченном мозгу человека.
Написал длинный-длинный пост, перечитал, и понял, что по сути я пишу все то же самое, что и раньше.
Поэтому все удалил, и постараюсь сказать что-нибудь новое.
Сначала маленькая ремарка - ты как-то все время радостно так исходишь из предположения, что человек может делать что-то безошибочно. В реальности же даже полностью алгоритмизуемые действия типа элементарных рефакторингов могут исполняться человеком с ошибками.
Твой безтестовый подход, на мой взгляд, не является каким-то ноу-хау. Это то, как все всегда писали код. Да, при достаточном вложении усилий, можно осознать полностью кусок чего-то, аккуратно сделать минимальное изменение, и двинуться дальше. Но он так же подвержен проблеме упущенных ошибок, как и неполное покрытие кода тестами.
Фишка в том, что в масштабе большой команды твой способ означает, что много людей по многу раз будут тратить свое время на одно и то же - вдумчивое вникание в один и тот же код. Просто с целью выяснить все фичи, чтобы сохранить их.
Очевидно, что такое redundancy хотелось бы хоть немного уменьшить.
Сначала люди придумали писать комментарии, чтобы пояснять, зачем написан тот или иной кусок кода. Я не про комментарии вида "а это цикл по всем кроликам", а про комментарии с неочевидными вещами вида "а если убрать это, то сломается там-то".
Потом придумали фиксировать какие-то контракты в виде тестов. Это своего вида трейдофф. Между временем, тратящимся на вдумчивое вникание в код, и временем, тратящимся на написание тестов.
Можно потерять на избыточном покрытии тестами - известная проблема, много где описанная.
Можно упускать на недостаточном покрытии тестами - еще более известная проблема, классический пример, как системы становятся legacy вплоть до поинта, когда становится проще переписать с нуля, нежели чем полностью вникать во все при каждом изменении.
Чтобы не попасть в какую-то из вышеописанных крайностей, лично для себя я считаю, что наиболее разумно иметь примерно следующий набор:
1. Пачка системных тестов, взятых из основных use-case'ов. Т.н. sanity check.
2. Пачка интеграционных тестов - проверяем, что внешняя система работает так, как нам надо. В идеале, появляется при прикручивании этой системы к проекту в процессе разбирательства с api этой системы.
3. Пачка unit тестов. В идеале растет из tdd. Проверяются не какие-то элементарные вещи, а хай-левел вещи на уровне класса. Кажется, я уже писал выше, тогда повторюсь. В идеале мы формируем некий набор утверждений про выбранный класс. Все утверждения в сумме полностью описывают поведение класса. Каждое утверждение фиксируем в виде теста. Например, для класса Cache можно написать тесты вида
i) сэнити чек - можно достать только что закешированное значение
ii) кэш корректно эвиктит, не превышая лимита памяти
iii) на некой эталонной нагрузке кэш обеспечивает приемлемый hit-and-miss
Как ты видишь, это довольно сильно отличается от "стандартного" TDD, в котором, наверное, надо было бы писать что-то вроде:
i) сэнити чек - можно достать только что закешированное значение
ii) при обновлении значения, в кеше видим обновленное значение, а не старое
iii) при вставке второго значения в кеш, оба значения все еще доступны
iv) пока вставляем в кеш не превышая лимита памяти, все значения сохраняются в кеше
... итд ...
Причина, почему я так не делаю? Аргументация будет твоя - я вполне ощущаю себя в силах пойти и написать кэш с какой-нибудь незамутной стратегией. И сильно концентрировать свое внимание на этом аспекте мне нет нужды.
А вот то, как корректно моя реализация будет пеформить на реальных данных - уже более тяжелый вопрос, и вот тут-то мне и хотелось бы сконцентрироваться.
Поэтому все удалил, и постараюсь сказать что-нибудь новое.
Сначала маленькая ремарка - ты как-то все время радостно так исходишь из предположения, что человек может делать что-то безошибочно. В реальности же даже полностью алгоритмизуемые действия типа элементарных рефакторингов могут исполняться человеком с ошибками.
Твой безтестовый подход, на мой взгляд, не является каким-то ноу-хау. Это то, как все всегда писали код. Да, при достаточном вложении усилий, можно осознать полностью кусок чего-то, аккуратно сделать минимальное изменение, и двинуться дальше. Но он так же подвержен проблеме упущенных ошибок, как и неполное покрытие кода тестами.
Фишка в том, что в масштабе большой команды твой способ означает, что много людей по многу раз будут тратить свое время на одно и то же - вдумчивое вникание в один и тот же код. Просто с целью выяснить все фичи, чтобы сохранить их.
Очевидно, что такое redundancy хотелось бы хоть немного уменьшить.
Сначала люди придумали писать комментарии, чтобы пояснять, зачем написан тот или иной кусок кода. Я не про комментарии вида "а это цикл по всем кроликам", а про комментарии с неочевидными вещами вида "а если убрать это, то сломается там-то".
Потом придумали фиксировать какие-то контракты в виде тестов. Это своего вида трейдофф. Между временем, тратящимся на вдумчивое вникание в код, и временем, тратящимся на написание тестов.
Можно потерять на избыточном покрытии тестами - известная проблема, много где описанная.
Можно упускать на недостаточном покрытии тестами - еще более известная проблема, классический пример, как системы становятся legacy вплоть до поинта, когда становится проще переписать с нуля, нежели чем полностью вникать во все при каждом изменении.
Чтобы не попасть в какую-то из вышеописанных крайностей, лично для себя я считаю, что наиболее разумно иметь примерно следующий набор:
1. Пачка системных тестов, взятых из основных use-case'ов. Т.н. sanity check.
2. Пачка интеграционных тестов - проверяем, что внешняя система работает так, как нам надо. В идеале, появляется при прикручивании этой системы к проекту в процессе разбирательства с api этой системы.
3. Пачка unit тестов. В идеале растет из tdd. Проверяются не какие-то элементарные вещи, а хай-левел вещи на уровне класса. Кажется, я уже писал выше, тогда повторюсь. В идеале мы формируем некий набор утверждений про выбранный класс. Все утверждения в сумме полностью описывают поведение класса. Каждое утверждение фиксируем в виде теста. Например, для класса Cache можно написать тесты вида
i) сэнити чек - можно достать только что закешированное значение
ii) кэш корректно эвиктит, не превышая лимита памяти
iii) на некой эталонной нагрузке кэш обеспечивает приемлемый hit-and-miss
Как ты видишь, это довольно сильно отличается от "стандартного" TDD, в котором, наверное, надо было бы писать что-то вроде:
i) сэнити чек - можно достать только что закешированное значение
ii) при обновлении значения, в кеше видим обновленное значение, а не старое
iii) при вставке второго значения в кеш, оба значения все еще доступны
iv) пока вставляем в кеш не превышая лимита памяти, все значения сохраняются в кеше
... итд ...
Причина, почему я так не делаю? Аргументация будет твоя - я вполне ощущаю себя в силах пойти и написать кэш с какой-нибудь незамутной стратегией. И сильно концентрировать свое внимание на этом аспекте мне нет нужды.
А вот то, как корректно моя реализация будет пеформить на реальных данных - уже более тяжелый вопрос, и вот тут-то мне и хотелось бы сконцентрироваться.
Лучше потратить усилия программиста на внимательное написание кода, чем на написание тестов. Можно и то и другое, но это бюджет увеличивает. Причем прирост надежности от внимательности будет выше, чем от написания тестов.И этот человек пишет о внимательном написании кода, который будет работать без юнит тестов!111
Орфография и переносы строк сохранены.
public static void CheckQueries<T>(string connectionString, QueryResultPropertyTypeChecker queryResultPropertyTypeChecker, params Func<QueryContext, IQuery<T>>[] queryFuncs)
{
foreach (var queryFunc in queryFuncs)
{
var dataInfoPropertyInfos = typeof(T).GetProperties;
var dataInfoPropertyInfoDictionary = dataInfoPropertyInfos.ToDictionary(
propertyInfo => propertyInfo.Name);
var executeResult = ExecuteQuery(
connectionString, queryFunc,
(sqlDataReader, query) => new {schemaTable = sqlDataReader.GetSchemaTable query});
executeResult.schemaTable.Rows.Cast<DataRow>.ForEach(
dataRow => dataInfoPropertyInfoDictionary.GetOptionalValue(dataRow.GetColumnName.Process(
propertyInfo => queryResultPropertyTypeChecker(
propertyInfo, dataRow, => GetQueryType(executeResult.query
=>
{
throw new QueryCheckException(
string.Format(
@"The query result type does not contain a definition for property '{0}'.
QueryType = '{1}'",
dataRow.GetColumnName
GetQueryType(executeResult.query;
}
;
var schemaTableDictionary = executeResult.schemaTable.Rows.Cast<DataRow>.ToDictionary(_ => _.GetColumnName;
foreach (var propertyInfo in dataInfoPropertyInfos)
{
if (!schemaTableDictionary.GetOptionalValue(propertyInfo.Name).HasValue
{
throw new QueryCheckException(
string.Format(
@"The query result does not contain a column '{0}'.
QueryType = '{1}'",
propertyInfo.Name,
GetQueryType(executeResult.query;
}
}
}
}
Так внимателен, что даже не смог заметить вещи, которые можно вынести за цикл.
А ведь совсем недавно этот кодер писал про производительность.
Далее мы все читали про какие-то автоматические рефакторинги в ReSharper.
Обратим внимание на следующую функцию, автор которой явно не знает как сделать Extract Method:
public static void CheckAllQueries(
string connectionString,
QueryResultPropertyTypeChecker queryResultPropertyTypeChecker,
ParamCreator paramCreator,
Func<Type, bool> queryTypePredicate,
Func<MethodInfo, bool> methodInfoPredicate,
ChoiceInvocationGetter choiceInvocationGetter,
IEnumerable<Type> types)
{
foreach (var type in types)
{
if (!QueryExtensions.QueryImplementationType.Equals(type)
&& !QueryExtensions.NonQueryImplementationType.Equals(type
{
foreach (var @interface in type.GetInterfaces
{
if (@interface.IsGenericTypeAndEquals(typeof(IQuery<>
{
if (queryTypePredicate(type
{
Console.WriteLine(type);
foreach (var queryCreator in new ChoiceInvocationContext(choiceInvocationGetter).GetConstructorInvocations(type
{
InvokeCheckQuery(connectionString, queryResultPropertyTypeChecker, paramCreator, queryCreator, @interface.GetGenericArguments;
}
}
}
if (typeof(INonQuery).Equals(@interface
{
if (queryTypePredicate(type
{
Console.WriteLine(type);
foreach (var queryCreator in new ChoiceInvocationContext(choiceInvocationGetter).GetConstructorInvocations(type
{
InvokeCheckNonQuery(connectionString, paramCreator, queryCreator);
}
}
}
}
}
type.GetMethods(AllBindingFlags).ForEach(
methodInfo =>
{
if (methodInfoPredicate(methodInfo
{
FindMethod(
methodInfo,
methodInfo.GetGenericArguments,
resolveMethodInfo => CheckMethod(
methodInfo, choiceInvocationGetter,
queryCreator => InvokeCheckQuery(
connectionString, queryResultPropertyTypeChecker, paramCreator,
queryCreator,
resolveMethodInfo.GetGenericArguments
resolveMethodInfo => CheckMethod(
methodInfo, choiceInvocationGetter,
queryCreator =>
InvokeCheckNonQuery(connectionString, paramCreator, queryCreator;
}
});
type.GetConstructors(AllBindingFlags).ForEach(
methodInfo => FindMethod(
methodInfo,
=> new Type[] {},
resolveMethodInfo => ThrowQueryCheckException(toQueryMethodInfo, methodInfo
resolveMethodInfo => ThrowQueryCheckException(toNonQueryMethodInfo, methodInfo;
}
}
Здесь разговор не должен идти о каких-то высоких материях, тут сначала нужно учиться обычному структурному программированию и соблюдению хоть чего-то, похожего на единый стиль.
Можно сразу обратить внимание на адскую смесь foreach и .ForEach и, например, на рандомно расставленные переносы строк при вызове одинаковых функций.
адскую смесь foreach и .ForEachу метода ForEach есть комментарий, там написано, что ForEach нужен для замыкания переменной цикла. Это было актуально до C# 5.0, сейчас поведение компилятора поменяли, теперь везде можно писать foreach. Известная проблема, если ты не в курсе.
Так внимателен, что даже не смог заметить вещи, которые можно вынести за цикл.Да, это не имеет практического влияния на пефоманс. Такие замечания ревиьера говорят ли о лишь о самом ревьюере.
А ведь совсем недавно этот кодер писал про производительность.
Обратим внимание на следующую функцию, автор которой явно не знает как сделать Extract Method:Это на любителя. У Extract Method есть как плюсы так и минусы, в данном случае нет явных аргументов в пользу того или другого варианта.
у метода ForEach есть комментарий, там написано, что ForEach нужен для замыкания переменной цикла. Это было актуально до C# 5.0, сейчас поведение компилятора поменяли, теперь везде можно писать foreach. Известная проблема, если ты не в курсе.Ты не понял моего замечания.
Да, это не имеет практического влияния на пефоманс. Такие замечания ревиьера говорят ли о лишь о самом ревьюере.Ты опять ничего не понял. А судя по орфографии, во время написания поста у тебя тряслись ручонки.
Это на любителя. У Extract Method есть как плюсы так и минусы, в данном случае нет явных аргументов в пользу того или другого варианта.Только хотел написать, что ты не понял моего комментария. Но, прочитав твой пост второй раз, решил, что ты его не просто не понял, ты его абсолютно не понял.
В целом - жалкие оправдания в трёх разных постах. Понимаю, столько ты наплодил от волнения. Код гуано, в этом убедятся все, кто ещё поглядывает эту ветку в поисках попкорна.
Ты не понял моего замечания.ах, ты бедненький наш, я тебя ни как не могу понять, а ты мне всё пишешь и пишешь
ах, ты бедненький наш, я тебя ни как не могу понять, а ты мне всё пишешь и пишешьНе путай желаемое и действительное: я не бедненький и пишу не тебе.
ты не понимаешь мой код, я не понимаю твои посты, может не стоит дальше плодить непонимание в этом мире? Давай просто не пересекаться? Ты не комментируешь мои посты, а я не комментирую твои.
пишу не тебе.а кому?
ты не понимаешь мой код, я не понимаю твои посты, может не стоит дальше плодить непонимание в этом мире? Давай просто не пересекаться? Ты не комментируешь мои посты, а я не комментирую твои.Я твой код прекрасно понимаю, основную его характеристику я описал очень точно: "жидкое пахучее гуано, присыпанное извращённой формой функци-анальщины".
Твои посты - это моё развлечение, я же написал, что не каждому дано быть таким отменным клоуном. Так что я буду их коментировать, а ты можешь пойти поплакать.
ты можешь пойти поплакать.тогда я буду сдерживаться от ответов на твои комментарии, например, как на твой код со switch-ами, я не ответил, поскольку знал, что ничего полезного и нового я не увижу
например, как на твой код со switch-ами, я не ответил, поскольку знал, что ничего полезного и нового я не увижуНазывай вещи своими именами: на этом коде ты банально слился, потому что всё время в этой ветке порол чушь и кидал понты.
и кто из нас путает желаемое и действительное?
(I)
и кто из нас путает желаемое и действительное?Да, кто же?
Я так подумал, пока есть наглядный пример, стоит написать пост о вреде слишком длинных имен переменных. Этом треду он на пользу вряд ли пойдет, зато потом можно будет ссылаться.
Проблема произрастает из крайне разумного правила, что переменным нужно давать осмысленные имена. К сожалению некоторые программисты неверно считаю, что чем длиннее имя, тем оно более осмысленно. Это приводит к ситуации, когда за деревьями не видно леса, и основной смысл переменной в ее названии растворяется в незначительных свойствах, перечисленных там же.
Более того, слишком длинные имена ухудшают читаемость программы, за ради которой мы их и давали переменным. Все форматирование программы направлено на то, чтобы при беглом просмотре глаз легко выделял структуру программы, находил законченные конструкции и разбивал их на составные части. Для этого делаются отступы (структура программы) и пробелы в выражениях (разделение выражения на составные части). Длинные же имена переменных наоборот ухудшают это разбиение выражения на составные части. Длинные названия сливаются, одного пробела для них становится уже не достаточно.
Но это еще не все. С увеличением длины названий переменных удлиняются строки и их приходится разбивать. Тут дело не только в размере монитора или принятом стиле кодирования. Просто человек так устроен, что ему тяжело читать текст из слишком длинных строк. В типографском деле это давно известно и когда нужно разместить текст мелким шрифтом на большой странице это делают в несколько колонок (например в газетах, многих словарях и энйциклопедиях).
Выражение, которое развалилось на несколько строк воспринимать сложнее, но даже на этом дело не заканчивается. Поскольку в середине названия перенос строки не поставишь, длинные имена уменьшают количество вариантов, как разбить выражение на строки, и в результате программисту порой приходится отказываться от разбиения "по смыслу" и довольствоваться разбиением "как получилось".
Понятное дело, другая крайность, когда все переменные названы одной-двумя буквами тоже имеет очень серьезные проблемы: понять что означает переменная по ее названию становится невозможно. В конечном итоге задача стоит в том, чтобы дать переменным и функциям имена так, чтобы они достаточно отражали суть но не были слишком длинными. Хотя критерий и является субъективным, из него есть одно объективное следствие: нужно избегать добавления в названия переменных кусков, которые не сообщают читателю полезной информации.
Собственно пример, за ради которого все и затевалось:
В этом примере проблемы есть в названии почти всех переменных. Пойдем по порядку.
Параметр connectionString. Суффикст -String избыточен. Описанная функция с этим параметром никак не работает, она его просто передает дальше. Что он представляет из себя внтури ей совершенно не важно. Для нее важно, что это описание соединения с базой данных (или чем там еще). Вызывающий же видит сигнатуру и понимает, что нужно передать именно в формате строки из типа переменной.
Аналогичная история с параметром queryFuncs.
queryResultPropertyTypeChecker - вы это серьезно? 30-буквенное название для переменной, которая является локальной в функции длиной менее 40 строк? Эта штука проверяет результат на соотвествие типов. Нормальным названием было бы resultTypeChecker. Как оказалось куски query и Property вообще не несли никакой смысловой нагрузки. То, что она проверяет результат на соответствие типов из контекста тоже восстанавливается. Так что быть может ее стоило назвать resultChecker или даже просто checker, но это уже субъективно - достаточно ли легко оно восстанавливается или нет.
dataInfoPropertyInfos - вообще прекрасно. Какую информацию несут куски data, Info и еще раз Info совершенно не понятно. Зато из кода понятно, что это список пропертей, чего вполне достаточно для понимания того, что происходит в функции. Так зачем там еще 3 куска названия? Хотя с Info понятно - это что-то типа аналога слова "бля" из лексикона гопников. Такой паразит, которого после каждого слова добавляют. "dataБляPropertyБля" "dataБляPropertyБляDictionaryБля" (последнее "бля" в оригинальном тексте куда-то потерялось).
executeResult. Видимо предполагалось название executionResult, ну да это не важно, поскольку часть про execution очевидна и вписывать ее в название никакого смысла нет. Ну а результат чего еще может быть, если мы говорим про запросы?
Проблема произрастает из крайне разумного правила, что переменным нужно давать осмысленные имена. К сожалению некоторые программисты неверно считаю, что чем длиннее имя, тем оно более осмысленно. Это приводит к ситуации, когда за деревьями не видно леса, и основной смысл переменной в ее названии растворяется в незначительных свойствах, перечисленных там же.
Более того, слишком длинные имена ухудшают читаемость программы, за ради которой мы их и давали переменным. Все форматирование программы направлено на то, чтобы при беглом просмотре глаз легко выделял структуру программы, находил законченные конструкции и разбивал их на составные части. Для этого делаются отступы (структура программы) и пробелы в выражениях (разделение выражения на составные части). Длинные же имена переменных наоборот ухудшают это разбиение выражения на составные части. Длинные названия сливаются, одного пробела для них становится уже не достаточно.
Но это еще не все. С увеличением длины названий переменных удлиняются строки и их приходится разбивать. Тут дело не только в размере монитора или принятом стиле кодирования. Просто человек так устроен, что ему тяжело читать текст из слишком длинных строк. В типографском деле это давно известно и когда нужно разместить текст мелким шрифтом на большой странице это делают в несколько колонок (например в газетах, многих словарях и энйциклопедиях).
Выражение, которое развалилось на несколько строк воспринимать сложнее, но даже на этом дело не заканчивается. Поскольку в середине названия перенос строки не поставишь, длинные имена уменьшают количество вариантов, как разбить выражение на строки, и в результате программисту порой приходится отказываться от разбиения "по смыслу" и довольствоваться разбиением "как получилось".
Понятное дело, другая крайность, когда все переменные названы одной-двумя буквами тоже имеет очень серьезные проблемы: понять что означает переменная по ее названию становится невозможно. В конечном итоге задача стоит в том, чтобы дать переменным и функциям имена так, чтобы они достаточно отражали суть но не были слишком длинными. Хотя критерий и является субъективным, из него есть одно объективное следствие: нужно избегать добавления в названия переменных кусков, которые не сообщают читателю полезной информации.
Собственно пример, за ради которого все и затевалось:
public static void CheckQueries<T>(string connectionString, QueryResultPropertyTypeChecker queryResultPropertyTypeChecker, params Func<QueryContext, IQuery<T>>[] queryFuncs)
{
foreach (var queryFunc in queryFuncs)
{
var dataInfoPropertyInfos = typeof(T).GetProperties;
var dataInfoPropertyInfoDictionary = dataInfoPropertyInfos.ToDictionary(
propertyInfo => propertyInfo.Name);
var executeResult = ExecuteQuery(
connectionString, queryFunc,
(sqlDataReader, query) => new {schemaTable = sqlDataReader.GetSchemaTable query});
executeResult.schemaTable.Rows.Cast<DataRow>.ForEach(
dataRow => dataInfoPropertyInfoDictionary.GetOptionalValue(dataRow.GetColumnName.Process(
propertyInfo => queryResultPropertyTypeChecker(
propertyInfo, dataRow, => GetQueryType(executeResult.query
=>
{
throw new QueryCheckException(
string.Format(
@"The query result type does not contain a definition for property '{0}'.
QueryType = '{1}'",
dataRow.GetColumnName
GetQueryType(executeResult.query;
}
;
var schemaTableDictionary = executeResult.schemaTable.Rows.Cast<DataRow>.ToDictionary(_ => _.GetColumnName;
foreach (var propertyInfo in dataInfoPropertyInfos)
{
if (!schemaTableDictionary.GetOptionalValue(propertyInfo.Name).HasValue
{
throw new QueryCheckException(
string.Format(
@"The query result does not contain a column '{0}'.
QueryType = '{1}'",
propertyInfo.Name,
GetQueryType(executeResult.query;
}
}
}
}
В этом примере проблемы есть в названии почти всех переменных. Пойдем по порядку.
Параметр connectionString. Суффикст -String избыточен. Описанная функция с этим параметром никак не работает, она его просто передает дальше. Что он представляет из себя внтури ей совершенно не важно. Для нее важно, что это описание соединения с базой данных (или чем там еще). Вызывающий же видит сигнатуру и понимает, что нужно передать именно в формате строки из типа переменной.
Аналогичная история с параметром queryFuncs.
queryResultPropertyTypeChecker - вы это серьезно? 30-буквенное название для переменной, которая является локальной в функции длиной менее 40 строк? Эта штука проверяет результат на соотвествие типов. Нормальным названием было бы resultTypeChecker. Как оказалось куски query и Property вообще не несли никакой смысловой нагрузки. То, что она проверяет результат на соответствие типов из контекста тоже восстанавливается. Так что быть может ее стоило назвать resultChecker или даже просто checker, но это уже субъективно - достаточно ли легко оно восстанавливается или нет.
dataInfoPropertyInfos - вообще прекрасно. Какую информацию несут куски data, Info и еще раз Info совершенно не понятно. Зато из кода понятно, что это список пропертей, чего вполне достаточно для понимания того, что происходит в функции. Так зачем там еще 3 куска названия? Хотя с Info понятно - это что-то типа аналога слова "бля" из лексикона гопников. Такой паразит, которого после каждого слова добавляют. "dataБляPropertyБля" "dataБляPropertyБляDictionaryБля" (последнее "бля" в оригинальном тексте куда-то потерялось).
executeResult. Видимо предполагалось название executionResult, ну да это не важно, поскольку часть про execution очевидна и вписывать ее в название никакого смысла нет. Ну а результат чего еще может быть, если мы говорим про запросы?
Параметр connectionString. Суффикст -String избыточенне согласен. connectionString устоявшееся название, и лучше когда во всех функциях connectionString называется connectionString-ом, чем когда каждая функция называет его как-то по своему ради краткости.
> Какую информацию несут куски data, Info и еще раз Info совершенно не понятно
суффикс Info в такого рода коде также имеет устоявшееся значение: Info означает, что это не сами данные, а метаинформация о данных.
Соответственно, его выкидывание ухудшает беглое чтение, потому что сходу тогда не понятно - идет обработка метаданных или самих данных.
Оставить комментарий
stm6692945
Часто замечал за собой пагубную привычкуВот есть у тя задания и ты его решаешь примерно следующим образом:
Не пишешь большими кучками, а ебашишь по 2-3 строчки, запускаешь прогу, смотришь чо получось.
А сколько примерно вы пишете до проверки.
Просто постоянно гложит мысль, что оптимальнее сразу сделать большую простыня, а после править ее в дебаги, чем фигачить по 2-3 строчки