SQL-зубрам
group by username, status
затем pivot
затем pivot
select
username,
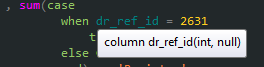
sum(case when status = свободна then 1 else 0 end) as cars_free,
sum(case when status = занято then 1 else 0 end) as cars_busy,
sum(case when status = недоступно then 1 else 0 end) as cars_na
from ololo
group by username
Примерно так
select
park.username,
sum(case when status=free then 1 else 0 end) as freecnt,
sum(case when status=busy then 1 else 0 end) as busycnt,
sum(case when status=wait then 1 else 0 end) as waitcnt,
from
park left join car on park.username = car.username
group by park.username
Отличие в том, что запрос выдаст и парки, в которых 0 машин (предполагается наличие таблицы park).
Наверное, это очень простая задача, но я SQL знаю почти никак, поэтому решил запостить.Так ты упарываешься по монге, потому что реляционки ни осилил?

По сабжу, реализация варианта робинзона на постгресе
select * from crosstab('select username, status, count(*) from taxi group by username, status order by username, status')
as ct(username text, free bigint, busy bigint, na bigint)Так ты упарываешься по монге, потому что реляционки ни осилил?Заметь, вышел два человека привели правильное решение (case и суммирование 0 и 1).
Ты же привел быдлокод, но зато типа подъебал?
Чем же, если не секрет, мое решение не правильное? Или "я не понял" = "быдлокод"? 
sum(case when status = свободна then 1 else 0 end)я люблю это писать как
sum(case status when свободна then 1 end)
лаконичнее, кроме того в постгресе чуть-чуть быстрее (настолько чуть-чуть, что никто не заметит, но всё же)
Примерно такЗабыл сказать спасибо!
Новое в SQL для меня открыли

для чего же group by с pivot?
[/list]
with ololo as (
select username = 'a', status = 'free'
union all select username = 'a', status = 'busy'
union all select username = 'a', status = 'na'
union all select username = 'b', status = 'free'
union all select username = 'b', status = 'na'
union all select username = 'c', status = 'busy'
union all select username = 'c', status = 'na'
)
select *
from
ololo
pivot (
count(status)
for status in (
free
, busy
, na
)
) p;
Хочется: сделать это одним запросом, т. е. получить ответ из 4 колонок, в первой username и 3 других — число машин в соотв. статусе.Выше всё правильно написали. Небольшой вопрос, зачем тебе разворачивать статусы каждый в отдельную колонку? Результат запроса скармливается PHP коду? Если, да, то разворачивать в столбцы особой необходимости нет, достаточно сделать "group by username, status", это проще.
Чтоб решить задачку по взрослому.
А так конечно при небольших масштабах хватит и суммирования через case на уровне select.
В целом этому проекту уже не хватает
- таблицы парков
- справочника статусов
- данных о периоде присвоения статуса
А так конечно при небольших масштабах хватит и суммирования через case на уровне select.
В целом этому проекту уже не хватает
- таблицы парков
- справочника статусов
- данных о периоде присвоения статуса
не, я про то, что с пивотом группировка не нужна - как бы сама по себе операция это подразумевает
Выше всё правильно написали. Небольшой вопрос, зачем тебе разворачивать статусы каждый в отдельную колонку?Да, всем спасибо! Все решения хорошие, помогли мне.
Зачем разворачиваю? Чтобы наглядно вывести, там таблиц много (джойнятся три таблицы я упрастил просто задачу и переформулировал.
Чтобы наглядно вывести,тк если выводом PHP занимает, то пусть он и разворачивает
Выводом занимается CTPP, зато в PHP максимально простой код:
Код на PHP занимает итого один экран, прост и понятен.
<?
...
$res = mysql_query($query) or die500(mysql_error;
...
while ($row = mysql_fetch_assoc($res
{
$_DATA['lines'][] = $row;
}
$T->emit_params($_DATA);
$T->output($template);
?>
Код на PHP занимает итого один экран, прост и понятен.
да можно и так, это не принципиально. Но просто, если поручить разворачивание столбцов коду на PHP, то не надо харткодить в SQL запросе три состояния, и запрос для СУБД будет полегче.
запрос для СУБД будет полегчеЧто значит полегче? Три прохода по таблице/индексу вместо одного - это полегче?
В терминах mvc ты занимаешься формированием представления в коде доступа к данным, это несколько порочная практика имо. Такие вещи надо в шаблонах делать.
И откуда три прохода?
Что значит полегче? Три прохода по таблице/индексу вместо одного - это полегче?Я думаю имелось в виду что он будет легче читаться
И откуда три прохода?Что значит полегче? Три прохода по таблице/индексу вместо одного - это полегче?я имел ввиду, что вот этот запрос
SELECT username, status, COUNT(*) AS count
FROM ololo
GROUP BY username, status
SELECT username FROM ololo
легче, чем вот этот
select
park.username,
sum(case when status=free then 1 else 0 end) as freecnt,
sum(case when status=busy then 1 else 0 end) as busycnt,
sum(case when status=wait then 1 else 0 end) as waitcnt,
from
park left join car on park.username = car.username
group by park.username
Кроме того, в реальности, скорее всего, будет пейдинг по username.
park.username = car.usernameкстати, это тоже странно, почему у парка нет Id-шника?
Вдогонку , если нужно будет на различных языках выдавать. У парка появятся русское и английское название.
Вдогонку , если нужно будет на различных языках выдавать. У парка появятся русское и английское название.блин, задача-то синтетическая, считай что два айдишника.
не придирайся, в реальности у меня совсем другие объекты, я просто переформулировал на что-то понятное. Можно было "студенты, группы, М/Ж/педики/трансы".
блин, задача-то синтетическая, считай что два айдишника.Если id-шники, то как реальный name достается? Есть варианты. Если просто в тот же select, то MySQL это проглотит, но это не хорошо, когда в select указываются колонки, которых нет в group by. Не все СУБД такое разрешают, поскольку возможны неопределенности. По-хорошему, сравнивать надо в реальной ситуации. Но я бы лишний раз подумал прежде, чем разворачивать столбцы SQL-ем, если это можно сделать на этапе вывода.
Если id-шники, то как реальный name достается?join-ом очевидно. Это не важно, на самом деле.
join-ом очевидно. Это не важно, на самом деле.Т.е. уже получается
SELECT parkid, status, COUNT(*) AS count
FROM ololo
GROUP BY parkid, status
SELECT parkid, username FROM ololo
против
select park.parkid,
username,
freecnt,
busycnt,
waitcnt
from
park join
(select
park.parkid,
sum(case when status=free then 1 else 0 end) as freecnt,
sum(case when status=busy then 1 else 0 end) as busycnt,
sum(case when status=wait then 1 else 0 end) as waitcnt,
from
park left join car on park.parkid = car.parkid
group by park.parkid) _
on park.parkid = _.parkid
Ты какую-то уже совсем ерунду придумал.
а ты про какой join? про другой я написал еще постом выше.
за такие запросы надо руки обрывать
поясни
Написано нечитаемо, ну это ладно, на вкус и цвет фломастеры разные. Но хотя бы алиасы надо использовать везде, а не только для разрешения конфликта имен. А так - джойн на park абсолютно не нужен, хватит того, что ты записал в подзапрос (username = min(username.
Еще - как я понял, ты схему тоже сам придумал, т.е. я не понимаю, почему username у тебя в ololo содержится во втором запросе "правильной" части (наверное, все-таки, там имеется в виду park, но кто тебя знает, таблицы то ты разные используешь - в одном месте park + car, в другом ololo)
Еще - как я понял, ты схему тоже сам придумал, т.е. я не понимаю, почему username у тебя в ololo содержится во втором запросе "правильной" части (наверное, все-таки, там имеется в виду park, но кто тебя знает, таблицы то ты разные используешь - в одном месте park + car, в другом ololo)
Написано нечитаемо, ну это ладно, на вкус и цвет фломастеры разные.
что нечитаемо? Форматирования я взял из постов выше, полностью переписывать лень было.
Но хотя бы алиасы надо использовать везде, а не только для разрешения конфликта имен.Почему?
А так - джойн на park абсолютно не нужен, хватит того, что ты записал в подзапрос (username = min(username.
Я этот запрос упоминал выше.
А если еще 5 полей из Park понадобиться везде min писать? Не для всех типов min разрешен, например, для GUID не разрешен.
Один join можно убрать
select park.parkid,
username,
ISNULL(freecnt, 0
ISNULL(busycnt, 0
ISNULL(waitcnt, 0)
from
park left join
(select
parkid,
sum(case when status=free then 1 else 0 end) as freecnt,
sum(case when status=busy then 1 else 0 end) as busycnt,
sum(case when status=wait then 1 else 0 end) as waitcnt,
from car
group by parkid) _
on park.parkid = _.parkid
Напиши свой вариант. Пианист вписал в условие id-шники.
Но этот вариант все равно проще:
SELECT parkid, status, COUNT(*) AS count
FROM car
GROUP BY parkid, status
SELECT parkid, username FROM park
ок, извини - насчет форматирования был неправ, хотя все равно считаю нечитаемым
Ты серьезно? Можешь подумать на досуге. Подсказки: рефакторинг и читабельность кода
Почему нет? В подавляющем большинстве случаев будет лучше лишнего джойна, хотя, конечно, данные должны быть в кэше, и лишнего не подтянет.
Не для всех, не спорю. Кстати, что за тип такой? И в какой СУБД? Но я так понимаю, ты в основном с MS SQL работаешь - там такого типа нет. Если имеется в виду uniqueidentifier, то тут ты, скажем так, совсем не прав. Более того, есть специальная функция, которая гарантирует, что новый идшник будет больше предыдущего
В рамках MSSQL и типов данных, где min брать нельзя или проблематично (image, varchar(max) и тд я бы написал через apply
Я не говорю про всякие сложные извращенные вещи - тут вполне штатная задача, и в СУБД решается абсолютно нормально.
Почему?
Ты серьезно? Можешь подумать на досуге. Подсказки: рефакторинг и читабельность кода
А если еще 5 полей из Park понадобиться везде min писать?
Почему нет? В подавляющем большинстве случаев будет лучше лишнего джойна, хотя, конечно, данные должны быть в кэше, и лишнего не подтянет.
Не для всех типов min разрешен, например, для GUID не разрешен.
Не для всех, не спорю. Кстати, что за тип такой? И в какой СУБД? Но я так понимаю, ты в основном с MS SQL работаешь - там такого типа нет. Если имеется в виду uniqueidentifier, то тут ты, скажем так, совсем не прав. Более того, есть специальная функция, которая гарантирует, что новый идшник будет больше предыдущего
Один join можно убратьТакой вариант уже лучше, хотя я бы написал с min(username)
В рамках MSSQL и типов данных, где min брать нельзя или проблематично (image, varchar(max) и тд я бы написал через apply
Но этот вариант все равно проще:Именно для этого и придумывают всякие штуки в СУБД, чтобы клиент доставал все данные по одной таблице и потом проводил все нужные операции у себя, ага
Я не говорю про всякие сложные извращенные вещи - тут вполне штатная задача, и в СУБД решается абсолютно нормально.Но я так понимаю, ты в основном с MS SQL работаешь - там такого типа нет. Если имеется в виду uniqueidentifier, то тут ты, скажем так, совсем не прав. Более того, есть специальная функция, которая гарантирует, что новый идшник будет больше предыдущегоВот только что попробовал "Operand data type uniqueidentifier is invalid for min operator." Сравнивать на больше, меньше можно, а min, max нельзя. http://stackoverflow.com/questions/6069368/aggregate-functio...
В рамках MSSQL и типов данных, где min брать нельзя или проблематично (image, varchar(max) и тд я бы написал через apply
Это как?
Именно для этого и придумывают всякие штуки в СУБД, чтобы клиент доставал все данные по одной таблице и потом проводил все нужные операции у себя, ага
Какие еще штуки кроме pivot, xml?
Вот возьмем те же Order и OrderItem. Надо вытаскивать Order-а с OrderItem-ми. И что нам для этого предлагают СУБД, ничего хорошего. Обычно обкладываются ORM-ом, который под капотом делает неуклюжий outer join и таки на клиенте делает преобразования в две связанные коллекции Order->OrderItem. А ты про какие-то удобные штуки в СУБД говоришь. Самая известная задачка решается на клиенте, при том через неуклюжий outer join.
Про развертывание столбцов. Вот недавно тут была аналогичная . Там также надо разворачивать столбцы. Только столбцов не фиксированное количество. Почему в задаче про такси мы хардкодим для каждого значения свой столбец, если более общее решение выглядит не хуже? (Здесь не нужно будет править запрос при добавлении нового статуса.)
На самом деле, на клиенте это всего лишь вызов одной функции ToDictionary.
хм, дома тоже пробовал на 2012 - отработало. На 2008р2 не работает, да
apply:
По поводу разного рода задач давай не будем: универсальных решений не бывает. Конкретно в этом случае, мне кажется, в бд удобнее.
apply:
select
park.*, cars.cnt
from
park
cross apply (
select cnt = count(*) from cars where cars.parkId = park.parkId
) cars
По поводу разного рода задач давай не будем: универсальных решений не бывает. Конкретно в этом случае, мне кажется, в бд удобнее.
Ты серьезно? Можешь подумать на досуге. Подсказки: рефакторинг и читабельность кодаВполне серьезно. Я за то, чтобы рефакторин производила IDE. А вот с читаемостью тут вообще не понятно, некоторые любят краткий синтаксис, и когда в языке надо повторять что-то, то смеются, читая это вслух. А тут как раз будут частые повторения названий таблиц. И опять-таки IDE показывает название таблицы при наведении курсора мыши.
Честно сказать, я сам всегда писал и пишу названия таблиц, и как раз сейчас стал об этом задумываться и обращать внимание на код в Интернете, встречаются разные варианты.
apply:это можно и так записать:
select
park.*,
(select count(*) from cars where cars.parkId = park.parkId) cnt
from
park
select
park.*,
(select count(*) from cars where cars.parkId = park.parkId and status = 1) cnt1,
(select count(*) from cars where cars.parkId = park.parkId and status = 2) cnt2,
(select count(*) from cars where cars.parkId = park.parkId and status = 3) cnt3
from
park
Для того, чтоб не писать каждый раз длинные названия таблиц, есть алиасы. Более того, если таблица в запросе участвует более одного раза, алиасы необходимы. Про рефакторинг: вот понадобилось тебе добавить поле с таким же именем, и код автоматом стал нерабочий. А ты можешь про это и не знать вообще, т.к это может быть вообще не твое приложение.
IDE показывает таблицу? ну-ну. Пришлось даже в легаси код залезть, чтоб найти пример
Это SQL Server Management Studio 2012
IDE показывает таблицу? ну-ну. Пришлось даже в легаси код залезть, чтоб найти пример
Это SQL Server Management Studio 2012
Можно, конечно, но через апплай лучше
Представь, что у тебя подзапрос для поля более сложный, и тебе надо много полей таких. А если один подзапрос должен возвращать несколько полей? Например, минимум, максимум и среднее - три раза будешь писать?
Кстати по поводу оформления - рекомендую попробовать писать алиасы колонок alias = value. Я раньше тоже писал value [as] alias, но потом понял, что так менее удобно + меньше шансов на ошибку. Подробнее тут http://sqlblog.com/blogs/aaron_bertrand/archive/2012/01/23/b...
Представь, что у тебя подзапрос для поля более сложный, и тебе надо много полей таких. А если один подзапрос должен возвращать несколько полей? Например, минимум, максимум и среднее - три раза будешь писать?
Кстати по поводу оформления - рекомендую попробовать писать алиасы колонок alias = value. Я раньше тоже писал value [as] alias, но потом понял, что так менее удобно + меньше шансов на ошибку. Подробнее тут http://sqlblog.com/blogs/aaron_bertrand/archive/2012/01/23/b...
А если один подзапрос должен возвращать несколько полей? Например, минимум, максимум и среднее - три раза будешь писать?угу, спасибо, это ценно
не писать каждый раз длинные названия таблиц, есть алиасы.Так мы же не про "писать", а про "читать". А чтобы прочитать алиас нужно найти его определение и держать в голове, упс ячейка памяти в голове израсходовалась.
Более того, если таблица в запросе участвует более одного раза, алиасы необходимы.
Тогда просто код не будет работать. Мы же обсуждаем только читаемость, т.е. варианты рабочего кода.
Про рефакторинг: вот понадобилось тебе добавить поле с таким же именем, и код автоматом стал нерабочий.
Что конкретно произойдет? СУБД будет выдавать сообщение о неоднозначности столбца? В этом случае Controllable Query покажет ошибку. Проводить рефакторинг без чего-то схожего с QC не стоит, и соглашениями по именованию тут не обойдешься.
Более сложной ситуации, когда запрос остается валидным, а столбец стал браться новый, я не могу себе пока представить. Замечу лишь, что аналогичная ситуация бывает в C# коде, если используются using для пространства имен, и в один прекрасный момент ты делаешь свой класс с таким же именем, то, да, у тебя компилируется, но может перестать работать, но это же не повод не использовать using и писать всегда наймспейсы.
Это SQL Server Management Studio 2012
SQL Promt показывает
А чтобы прочитать алиас нужно найти его определение и держать в голове, упс ячейка памяти в голове израсходовалась.
угу, а помнить, в какой таблице какая колонка требует две ячейки памяти на каждую колонку. Особенно круто, когда разбираешься в незнакомой базе
Что конкретно произойдет? СУБД будет выдавать сообщение о неоднозначности столбца? В этом случае Controllable Query покажет ошибку.Угу, надо заставить всех поставщиков баз перейти на CQ. Бывают внешние системы, с которыми ты интегрируешься, и их патч может тебе все поломать. Но нет, у тебя же лишняя ячейка памяти израсходуется. Пример с C# не в тему абсолютно
SQL Prompt - это хорошо, но он стоит денег. Я стараюсь не привыкать к платным инструментам, потому что при смене работы отсутствие привычных инструментов может плохо сказаться на производительности. Конечно, если ты работаешь в IT-компании, объяснить необходимость использовать инструмент не составит труда, и тебе его купят, но не в IT это бывает довольно сложно. Ну и не настолько Prompt хорош, честно говоря. Помню, был купленный, но я им пользоваться не смог. Причин не назову, очень давно было
Выводом занимается CTPP, зато в PHP максимально простой код:Возьмите себе простое правило: на странице, где ожидается хоть какая-то нагрузка, пользовательский запрос не должен приводить к запросу в базу с group by.
Иначе при набигании - ляжете и устанете расхлёбывать.
Либо храните эти числа в отдельных полях и изменяйте при изменении статусов (если изменяющих запросов терпимо либо изменяйте офлайновым скриптом иногда, либо просто кэш генерите в офлайне.
В этом случае хоть всю базу пачками перебирайте. Это нормальное решение, сгруппировать в процессе может получиться значительно быстрее, чем в базе.
угу, а помнить, в какой таблице какая колонка требует две ячейки памяти на каждую колонку. Особенно круто, когда разбираешься в незнакомой базеSQL Promt показывает. Стоит он $195, можно и самому купить. Он далеко не идеален, но, к сожалению, для .NET ничего лучше я не видел. Для Java/Python/PHP продукты Jentrains поддерживают SQL. Короче так, без алиасов плохо, с алиасами лучше, но еще лучше с ide, но без алиасов.
о нет, у тебя же лишняя ячейка памяти израсходуется.
Зря ты иронизируешь, их всего 7 ± 2 http://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D0%B3%D0%B8%D1%87%...
Как у муравьев.

а ты в курсе, что нельзя на работе использовать купленные лично продукты в большинстве случаев? А про алиасы я тебе написал.
Открой для себя SSDT, очень хороший продукт от МС. SQL Prompt не нужен. Кстати, PromPt, а не Promt.
Upd. SQL Promt, JenTrains. Не, ты какими-то альтернативными продуктами пользуешься
Upd. SQL Promt, JenTrains. Не, ты какими-то альтернативными продуктами пользуешься
Угу, надо заставить всех поставщиков баз перейти на CQ.ну почему есть другие решения
кто-то в ручную пишет unit-тесты для всех запросов.
кто-то LINQ использует
кто-то типизированные запросы на Scala делает.
А без этого рефакорить базу можно попытаться, но на свою удачу тогда.
Что делать в случае интеграции с внешними системами и патчами от них?
патчами от них?патчи тебя патчат или внешнюю систему?
я тебе вообще уже описал ситуацию до этого, но повторю - внешнюю
всё также как с обычными unit-тестами. Патчите систему, прогоняйте unit-тесты.
не, я понимаю, что тесты нужны и тд. Только вот у меня ничего не сломается от того, что во внешней системе появилась колонка с таким же именем, а у тебя сломается на юниттесте. Для меня выбор очевиден, но ты можешь дальше настаивать, что использование алиасов хуже, чем клевая иде со встроенным CQ
Ты не знаешь хорошие гайды по форматированию SQL-я? Ты какими пользуешься? Я пробовал несколько, но так и не определился, хорошего не нашел.
Открой для себя SSDT, очень хороший продукт от МС. SQL Prompt не нужен. Кстати, PromPt, а не Promt.Я пользуюсь вот этим http://www.red-gate.com/products/sql-development/sql-prompt/
Первое на что я смотрю при выборе тулзы для SQL, подсказывает ли она JOIN ON по форен кею
:
Выше писал про подсказки над полями, выглядит это так:

я много разных видел, разумеется, но 100% совпадающего с моим стилем нет (имею в виду то, как мне больше всего нравится). И потом, если в компании принят какой-то стиль, навязывать свой не стоит, кроме, разумеется, исправления вредных привычек. Потом можно попытаться формализовать, скажем, мой стиль, но выяснится, что в некоторых случаях будет нечитаемо. Пример - названия столбцов. Я пишу каждый столбец в новой строке. Но на широких таблицах это растягивается на несколько экранов, и я сам отхожу от этого правила. В общем, если при взгляде на запрос в незнакомой базе все понятно, то написано хорошо, даже если не нравится стиль У меня где-то была дока, где попытался формализовать свой стиль, но не нашел сходу: старую вики грохнули, может вообще пропала. Посмотри настройки всяких форматтеров, подбери что тебе подходит. Скажем, Poor Man's T-SQL Formatter (я им пользуюсь для чтения легаси)
У меня где-то была дока, где попытался формализовать свой стиль, но не нашел сходу: старую вики грохнули, может вообще пропала. Посмотри настройки всяких форматтеров, подбери что тебе подходит. Скажем, Poor Man's T-SQL Formatter (я им пользуюсь для чтения легаси)вот для этого и нужны алиасы, чтобы не читать такие длинные строки. А ссдт посмотри, вроде умеет. Сам не пользуюсь, но боюсь, объяснять причины слишком долго будет. Для stand-alone проекта - очень круто, особенно, если не базданщик
ага, я про него же, только ты читать не умеешь, видимо
только ты читать не умеешь, видимода понял я свою опечатку
что за форум, обязательно подъебать надо
один раз опечатка, когда постоянно пишешь так - система. Jentrains - тоже опечатка, или нет?)
Jentrains - тоже опечатка, или нетда, вот в скольких местах я писал правильно
возьми с полки пирожок
а ты в курсе, что нельзя на работе использовать купленные лично продукты в большинстве случаев?ты про какое большинство случаев? Например, продукты JetBrains можно покупать самостоятельно:
Кратко: чтобы легально использовать IDE в коммерческом продукте нужно либо, чтобы у компании была коммерческая лицензия, которую она выдаст своему разработчику, либо чтобы у разработчика откуда-то появилась персональная лицензия (купленная, выигранная/ подаренная или полученная за бытие MVP).
http://www.rsdn.ru/forum/jetbrains/5273786.1
Я, честно говоря, не силен в юридических делах. Хотел купить одну тулзню себе, чтобы использовать на работе (ну и при смене работы с собой забрать) - юристы запретили. Сказали, что могут купить (баксов 100 стоило, что-то но купить должна именно компания. В конечном итоге я нашел бесплатный аналог и забил. Может, конечно, юристы не правы были, но у меня им, почему-то, в этом вопросе больше доверия, чем тебе.
А ссылку ты привел вообще непонятно на что, при чем тут интеллисенс?
А ссылку ты привел вообще непонятно на что, при чем тут интеллисенс?
А ссылку ты привел вообще непонятно на что, при чем тут интеллисенс?не тот url был (кривой rsdn сейчас поправил
ну ок, может jetbrains разрешают, может и юристы ошиблись
юристы скорее всего перестраховываются, тем более если это российские. В России компании трахают за каждую запятую, а в данном случае не совсем понятно как это оформлять (и нужно ли это оформлять).
так-то если лицензия куплена для коммерческого использования, то права для использования вполне есть.
так-то если лицензия куплена для коммерческого использования, то права для использования вполне есть.
ну ок, может jetbrains разрешают, может и юристы ошиблисьУ SQL Prompt вообще нет разделения на корпоративную и персональную лицензию. Компании Red Gate пофиг кто будет оплачивать. Единственно, работодатель может не разрешать ставить софт на рабочую машину. Ну а это уже вопрос об адекватности работодателя.
мне на самом деле тоже так кажется
Оставить комментарий
Werdna
Наверное, это очень простая задача, но я SQL знаю почти никак, поэтому решил запостить. Как минимум это будет хорошее упражнение, а кому-то — хорошая задачка для проведения собеседований.Я формулирую максимально просто, "такси в городе". Есть id машины, есть username автопарка, есть status enum (свободна, на выезде, недоступна).
Можно делать такие запросы:
Каждый такой запрос выдает число занятых (на выезде, недоступных) машин соотв. автопарка.
Хочется: сделать это одним запросом, т. е. получить ответ из 4 колонок, в первой username и 3 других — число машин в соотв. статусе.