Почему в мире свободного ПО нет альтернативы Java/C#?
А в мире несвободного ПО есть альтернативы Java/C# ?
Go, Dговна то много понаделано, это понятно
говна то много понаделано, это понятноА говоришь нет альтернативы

Vala же.
А говоришь нет альтернативыконечно нет, не один современный язык с нормальной навигацией по коду не доведен до уровня, когда его можно использовать
язык с нормальной навигацией по кодуэто свойство языка?
это свойство языка?язык делает это либо возможным, либо нет. Сравни редакторы для Java/C#/TypeScript с редакторами для JS/PHP/Python/Ruby.
успокойся, для явы тоже нет навигации по коду. Потому как рефлексия.
Потому как рефлексия.почти всегда можно написать с сохранением навигации
Go, Dне тянут на аналоги.
vala еще может быть.
не тянут на аналоги.ну да, vala лучше подходит. в тех двух не хватает того самого аромата говна.
vala еще может быть.
Так это, жава-макаки же говорят, что жава свободная, разве нет? Спеки открытые, openjdk, всё такое.
Так это, жава-макаки же говорят, что жава свободная, разве нет? Спеки открытые, openjdk, всё такое.развитие тормозит Oracle
почти всегда можно написать с сохранением навигациина питоне тоже можно писать с сохранением навигации. А можно кодогенерировать. Так что получается, что навигация - это не вопрос языка, а вопрос стиля.
конечно нет, не один современный язык с нормальной навигацией по коду не доведен до уровня, когда его можно использоватьВ Лиспе очень удобная навигация

на питоне тоже можно писать с сохранением навигации. А можно кодогенерировать. Так что получается, что навигация - это не вопрос языка, а вопрос стиля.Если всё называть guid-ами или пусть редактор требует явного проставления связей, тогда навигация будет на любом языке. Но это не удобно для человека. К тому, что ты написал это тоже относится. Поэтому на сегодняшний день ничего лучшего не придумали, чем использовать свойства языка в качестве навигации.
В Лиспе очень удобная навигацияНапиши на любимом диалекте лиспа следующее. Есть две абстракции A1 и A2. У каждой абстракции определена своя операция с именем Op. Затем пишется некоторая функция MyF с аргументом. У аргумента вызывается метод Op. Функция MyF имеет смысл только для абстракции типа A1. Распиши реализацию алгоритма навигации, которая работает следующим образом. Когда ищем вызов Op для абстракции A1, то функция MyF попадает в результат поиска. Когда ищем вызов Op для абстракции A2, то функция MyF не попадает в результат поиска.
У тебя мозг деформирован С# и т.п. Суть Лиспа как раз в том, что в нем во главу угла ставятся не А1 и А2, а функции, иными словами не данные, а их преобразования. Поэтому твой вопрос бессмысленнен. myF обрабатывает все, что имеет Op.
У тебя мозг деформирован С# и т.п. Суть Лиспа как раз в том, что в нем во главу угла ставятся не А1 и А2, а функции, иными словами не данные, а их преобразования. Поэтому твой вопрос бессмысленнен. myF обрабатывает все, что имеет Op.Это у тебя деформирован мозг тем, что все вокруг дураки с деформированным мозгом под какую-то идеологию.
Покажи почему мой вопрос бессмысленен? Какое именно предложение бессмысленно в идеологии Лиспа? В лиспе нельзя группировать операции по абстракциям?
не А1 и А2, а функцив моем тексте у А1 и А2 кроме одной функции Op ничего нет. Ты сам понял что написал?
Так ты укажи конкретно, что ты имеешь в виду под своими А1 и А2, op и myf и какую задачу пытаешься решить. А так ты изначально поставил вопрос в формулировке не соответствующей идеологии лиспа.
Так ты укажи конкретно, что ты имеешь в виду под своими А1 и А2, op и myf и какую задачу пытаешься решить. А так ты изначально поставил вопрос в формулировке не соответствующей идеологии лиспа.Ты упоротый
Ты упоротыйты на вопрос не ответил
не соответствующей идеологии лиспа.еще раз, что не соответствует идеологии Лиспа?
ты на вопрос не ответилА чего тебе непонятно? Программа на Лиспе это дерево, по дереву можно искать. Запросы можно писать на Лиспе же, можно такой запрос запомнить если он часто нужен и записать в функцию.
В Емаксе например.
Или тебе на все случаи жизни кнопочки нужны?
Программа на Лиспе это дерево, по дереву можно искать. Запросы можно писать на Лиспе же, можно такой запрос запомнить если он часто нужен и записать в функцию.Вот это я и прошу сделать. Пока ты этого не сделал.
Или тебе на все случаи жизни кнопочки нужны?
Мне нужны небольшой набор функций, который покрывает большой набор случаев из жизни.
еще раз, что не соответствует идеологии Лиспа?Еще раз повторяю, какую реальную задачу ты пытаешься решить с помощью A1, A2, op и myF
Еще раз повторяю, какую реальную задачу ты пытаешься решить с помощью A1, A2, op и myFВот перепиши операции над рациональными числами так, что операции назывались не print-rat, add-rat, sub-rat, mul-rat, div-rat, equal-rat, а по человечески print, add, sub, mul, div, equal. Диалект Лиспа можешь сменить.
естественно, я не хочу (когда я рядом положу реализацию комплексных чисел) чтобы в результат навигации попадала смесь от рациональных и комплексных чисел. Если я не определил именно общие интерфейсы. Иначе невинное вынесение фрагмента кода в функцию, будет замусориваться результат поиска.
Первоначально print и т.п. пишется через if. Далее, набор if-ов оптимизируется - создается таблица соответствий тип vs тип и все функции единообразно редиректятся в нужную функцию в зависимости от аргументов (т.е. кроме самих функций-операций, есть еще функции создания таблицы и диспетчер). Вроде это дальше в сикп и делается.
Могут сразу заявить, что типа в жавах это делает сам компилятор. Но лисп зато в отличие от жавы не скован рамками языка. Создание диспетчера - плевое дело, зато с ним потом можно делать что угодно - модифицировать на лету, сохранять в файл и т.п.
Могут сразу заявить, что типа в жавах это делает сам компилятор. Но лисп зато в отличие от жавы не скован рамками языка. Создание диспетчера - плевое дело, зато с ним потом можно делать что угодно - модифицировать на лету, сохранять в файл и т.п.
Первоначально print и т.п. пишется через if. Далее, набор if-ов оптимизируется - создается таблица соответствий тип vs тип и все функции единообразно редиректятся в нужную функцию в зависимости от аргументов (т.е. кроме самих функций-операций, есть еще функции создания таблицы и диспетчер). Вроде это дальше в сикп и делается.Не пройдет вот этот тест: "Когда ищем вызов Op для абстракции A2, то функция MyF не попадает в результат поиска."
A1 — рациональные числа,
A2 — комплексные числа,
MyF — какая-то сугубо частная функция, работающая только с рациональными числами.
Могут сразу заявить, что типа в жавах это делает сам компилятор. Но лисп зато в отличие от жавы не скован рамками языка. Создание диспетчера - плевое дело, зато с ним потом можно делать что угодно - модифицировать на лету, сохранять в файл и т.п.В том то и фишка, что алгоритмы компилятора и алгоритмы навигации часто идут парой. Я о том и толкую, что если у вас в дизайн языка вошло нечто, из которого можно вывести алгоритм навигации, то вы получите навигацию, если язык вам дал полную свободу, то и нормальной навигации вы не получите.
пишется через ifif-ы работают в рантайме, а навигацию надо делать как статический анализ кода. Рантаймовые вещи плохо поддаются статическому анализу.
т.е. о навигации нужно думать при дизайне языка.
А не при разработке текстового редактора
А не при разработке текстового редактора
это свойство языка?это свойство текстового редактора?
чье это свойство?
A1 — рациональные числа,Все в порядке. Для такой функции в таблице будет пропуск для рац. чисел.
A2 — комплексные числа,
MyF — какая-то сугубо частная функция, работающая только с рациональными числами.
Все в порядке. Для такой функции в таблице будет пропуск для рац. чисел.Т.е. у каждого метода будет своя табличка. (Не забываем, что аргументом у метода может быть несколько.) Инструмент навигации должен по методу достать соответствующую табличку ... Короче, это напоминает явный велосипедизм... Давай уже код на Лиспе, а то так можно долго. Найти вызовы метода, крайне простая задача. И всё должно быть давно реализовано. Ссылки на реализацию (и даже туториалы) в студию. Иначе слив засчитан.
Могут сразу заявить, что типа в жавах это делает сам компилятор.Java не только заполняет такую таблицу, но и предлагает простую стандартизованную метафору по заданию такой таблицы.
Какая метафора будет использоваться в предложенном тобой варианте?
Мне нужны небольшой набор функций, который покрывает большой набор случаев из жизни.http://www.lispworks.com/documentation/lw50/EDUG-W/html/edus...
4.3.2 Definition searching
Definition searching involves taking a name for a function (or a macro, variable, editor command,.and so on and finding the actual definition of that function. This is particularly useful in large systems, where code may exist in a large number of source files.
Function definitions are found by using information provided either by LispWorks source recording or by a Tags file. If source records or Tags information have not been made available to LispWorks, then the following commands do not work. To make the information available to LispWorks, set the variable dspec:*active-finders* appropriately. See the LispWorks Reference Manual for details.
Source records are created if the variable *record-source-files* is true when definitions are compiled, evaluated or loaded. See the LispWorks Reference Manual for details.
Tag information is set up by the editor itself, and can be saved to a file for future use. For each file in a defined system, the tag file contains a relevant file name entry, followed by names and positions of each defining form in that file. Before tag searching can take place, there must exist a buffer containing the required tag information. You can specify a previously saved tag file as the current tag buffer, or you can create a new one using Create Tags Buffer. GNU Emacs tag files are fully compatible with LispWorks editor tag files.
4.3.4 Function callers and callees
The commands described in this section, require that LispWorks is producing cross-referencing information. This information is produced by turning source debugging on while compiling and loading the relevant definitions
Т.е. Definition searching работает аля текстовый поиск, а callers ищутся через дебаг. И ты это хочешь противопоставить поиску в Java/C#, где известен 100% алгоритм чисто по сорцам без дебага?
и это в продукте стоимостью в $4,500 per user. Если за такие бабки не сделали, то о чем разговор...
и это в продукте стоимостью в $4,500 per user. Если за такие бабки не сделали, то о чем разговор...Прозрачно намекаю что разговор о том что ты упоролся насчет навигации по коду, а кроме тебя это никому не интересно.
Прозрачно намекаю что разговор о том что ты упоролся насчет навигации по коду, а кроме тебя это никому не интересно.Навигация это просто хороший индикатор. Если навигация есть, то, скорее всего, язык является хорошим средством для декомпозиции задач. Иначе всё делается в уме. Небольшие задачки решаются в уме, для больших задач человечество придумало делать выкладки на бумаге. Так и тут, скриптовые языки это просто средство записи решения в уме. Другие языки напротив предоставляют абстрактные средства декомпозиции.
.... никому не интересно.Ну да, когда-то вполне неплохо жили вот такие люди: И без алгебры решить можно ... Вот-с... по-нашему, по-неученому
скриптовые языки это просто средство записи решения в уме.
для больших задач человечество придумало делать выкладки на бумаге.
В моем случае человечество еще и доску придумало. В виду образного мышления я не только на ней композицию могу писать, но еще и человечков всяких рисовать.
Поэтому сейчас поем и пойду дальше писать на скриптовом языке. На том, благодаря которому в процессе проектирования ни я, ни заказчик не зависим ни от операционной системы, ни от типа БД.

Вот перепиши операции над рациональными числами так, что операции назывались не print-rat, add-rat, sub-rat, mul-rat, div-rat, equal-rat, а по человечески print, add, sub, mul, div, equal. Диалект Лиспа можешь сменить.Не поздно еще?
$ lein repl
nREPL server started on port 63990
REPL-y 0.2.0
Clojure 1.5.1
user=> (defmulti prn (fn [x & more] (class x
WARNING: prn already refers to: #'clojure.core/prn in namespace: user, being replaced by: #'user/prn
#'user/prn
user=> (defmethod prn :default [x & more] (clojure.core/prn x) (when more (apply prn more
#<MultiFn clojure.lang.6f045aa2>
user=> (defrecord MyRational [a b])
user.MyRational
user=> (def t (MyRational. 1 2
#'user/t
user=> (prn t)
#user.MyRational{:a 1, :b 2}
nil
user=> (defmethod prn MyRational [x & more] (apply clojure.core/prn (str "rational " (:a x) "/" (:b x more
#<MultiFn clojure.lang.6f045aa2>
user=> (prn t)
"rational 1/2"
nil
Не поздно еще?
Самый раз.
Теперь представим, что пишем какой-нибудь длинный алгоритм, работающий с рациональными числами, и потребовалось выделить кусочек кода в отдельную функцию MyF:
(defun MyF (x)
(prn (mul x x
Теперь в инструменте навигации говорим, покажи все вызовы вот этого метода:
(defmethod prn MyRational [x & more] (apply clojure.core/prn (str "rational " (:a x) "/" (:b x more
и тот же поиск запускаем для метода
(defmethod prn MyComplex ...
В результат первого поиска строка 2 функции MyF должна присутствовать, в результате второго должна отсутствовать.
Такие тулзы для поиска есть?
В определении MyF нет MyRational, поэтому тулза должна просмотреть все вызовы, в местах вызовов определить типы аргументов и т.д. На сегодняшний день не известно алгоритма, который делает это за не экспоненциальное время.
Теперь представим, что пишем какой-нибудь длинный алгоритм, работающий с рациональными числами, и потребовалось выделить кусочек кода в отдельную функцию MyF:Ну, начнем с того, что ТАК на ФЯ вообще и лиспе в частности не пишут. "Длинные алгоритмы" - это удел Java/C++/C#. Тут обычно сразу нарезают на много коротких, понятных и документированных функций.
Теперь в инструменте навигации говорим, покажи все вызовы вот этого метода:Зачем это нужно? Т.е. мне никогда подобные мысли в голову не приходили, хоть на лиспе, хоть (каюсь, грешен) на яве. Вообще, говорят, что есть http://cursiveclojure.com/
В результат первого поиска строка 2 функции MyF должна присутствовать, в результате второго должна отсутствовать.Короче, по сути твои претензии, как я понимаю, слились в динамическую типизацию. Ок, если говорить о лиспах, то есть clojure/core.typed для тех, кому ну очень надо, действительно, чтобы такое было "сразу".
Такие тулзы для поиска есть?
В определении MyF нет MyRational, поэтому тулза должна просмотреть все вызовы, в местах вызовов определить типы аргументов и т.д. На сегодняшний день не известно алгоритма, который делает это за не экспоненциальное время.
clojure/core.typedо, так это настолько свежее, что на первой странице в новостях на infoq.com
Oct 07, 2013 Core.Typed Adds an Optional Type System
Имхо, это всё не серьезно. Сначала взяли чужую виртуальную машину JavaVM,
Ты по сути-то ответь, зачем тебе нужно это? Я к чему: придумывать юз-кейсы, которые сложно сделать инструменто X, но легко инструментом Y - это одно, а реально необходимые юз-кейсы из этой серии - это другое. Я ж тоже могу написать (defmulti prn (fn [x & more] [(class x) (> (str x) 42)] а потом со слюнями отстаивать что "на яве ты такого не сделаешь", но зачем?
P.S. Картинка в помощь:

P.S. Картинка в помощь:
никому не интересноАвтор clojure/core.typed пишет обратное, что программисты горячо ждут такую систему типов:
I've been very pleased by the response. I think it shows that Clojure programmers have been eagerly wait for a powerful, completely optional type system at their disposal when building Clojure programs.
http://www.infoq.com/news/2013/10/core-typed
Видимо, ждут пока кто-нибудь спонсирует нормальную реализацию ....
Честно говоря, это всё в не очень выгодном свете выставляет большинство посетителей данного раздела, что печально.

Если навигация есть, то, скорее всего, язык является хорошим средством для декомпозиции задач.Наоборот, если навигация по коду нужна значит язык плохой для декомпозиции задач.
А у тебя жаба головного мозга

Наоборот, если навигация по коду нужна значит язык плохой для декомпозиции задач.если нет навигации по коду, то нет и автоматизированных преобразований кода - а это здорово снижает скорость рефакторинга больших массивов кода.
если нет навигации по коду, то нет и автоматизированных преобразований кода - а это здорово снижает скорость рефакторинга больших массивов кода.Зачем нужен автоматизированный рефакторинг кода?
А у тебя C# головного мозга
Зачем нужен автоматизированный рефакторинг кода?потому что не автоматизированный - сильно трудозатратнее (а значит конкуренты будет делать быстрее и дешевле).
потому что не автоматизированный - сильно трудозатратнее (а значит конкуренты будет делать быстрее и дешевле).Ок, зачем нужен автоматизированный рефакторинг кода, если ты не индус?
Ок, зачем нужен автоматизированный рефакторинг кода, если ты не индус?я правильно понял твою позицию, что ты считаешь себя не индусом, потому что код никогда не рефакторишь?
если же всё-таки рефакторишь, то какие ты при этом делаешь элементарные действия (например, переименование функций/переменных, перенос функционала из одного объекта/функции в другой и т.д.) ?
Ок, зачем нужен автоматизированный рефакторинг кода, если ты не индус?Покажи мне случайных файлов на тысячу строк своего кода, и я найду 5 мест, требующих рефакторинга.
Покажи мне случайных файлов на тысячу строк своего кода, и я найду 5 мест, требующих рефакторинга.не пишет код, он просто троллит. Конечно, рефакторинг нужен даже в Python/etc., но там другие методы для его выполнения, отличные от того, к чему привыкли пользователи Java/C#.
Я ж тоже могу написать (defmulti prn (fn [x & more] [(class x) (> (str x) 42)] а потом со слюнями отстаивать что "на яве ты такого не сделаешь"Оно же в байткод Я-машины компилится.

"Длинные алгоритмы" - это удНа Лиспе не пишут длинные алгоритмы?
Думаю, что это не так, и ты просто некорректно выразился, тогда прошу выражать свои мысли более ясно.
Тут обычно сразу нарезают на много коротких, понятных и документированных функций.
Нарезка это мыслительные операции. Эти мыслительные операции можно заменить механическими преобразованиями. И освободить человеческую голову для более сложных и интересных вещей. Приведу аналогию с задачей из рассказа Чехова. Можно произвести мыслительные операции в уме и сразу выписать вот такое решение: "138 арш. черного сукна стоят 138*3 = 414 руб. Разница 540 – 414 = 126 руб. получается за счет синего, каждый метр которого на 2 руб. дороже. Следовательно, синего сукна было 126:2 = 63 арш., а черного было 138 – 63 = 75 арш." [ref1]. А можно переписать условие задачи в виде уравнений:
138 = x + y
540 = 3*x + 5*y
И затем выполнить механические преобразования для нахождения неизвестных переменных x и y.
Могу продемонстрировать, как это работает, на примере задачи из учебника MIT.
Оно же в байткод Я-машины компилится.Ну да, Any sufficiently complicated C or Fortran program contains an ad hoc, informally-specified, bug-rid, slow implementation of half of Common Lisp.

Если навигация есть, то, скорее всего, язык является хорошим средством для декомпозиции задач.Ты не внимательно читаешь, ты упустил главное слово "средство".
Наоборот, если навигация по коду нужна значит язык плохой для декомпозиции задач.
не пишет код, он просто троллитЭто конечно правда,
Конечно, рефакторинг нужен даже в Python/etc., но там другие методы для его выполнения, отличные от того, к чему привыкли пользователи Java/C#.
но ты сказал то же что и я.
Конечно, рефакторинг нужен даже в Python/etc., но там другие методы для его выполнения, отличные от того, к чему привыкли пользователи Java/C#.Раз рефакторинг нужен, возникает естественное желание сравнить трудозатраты на рефакторинг в твоем языке и в Java/C#.
но ты сказал то же что и я.
На Лиспе не пишут длинные алгоритмы?Ok, иначе скажу: лисп и другие ФЯ прививает модель разработки, которая, как правило, не приводит к появлению в коде больших функций, требующих злостного автоматизированного рефакторинга.
Думаю, что это не так, и ты просто некорректно выразился, тогда прошу выражать свои мысли более ясно.
Ты обещал по сути ответить на вопрос "зачем". Ответ-то будет?
лисп и другие ФЯ прививает модель разработки, которая, как правило, не приводит к появлению в коде больших функций, требующих злостного автоматизированного рефакторинга.но при этом методы рефакторинга все те же самые (с поправкой на функциональность)
Curry Method (split a parameter list, and the arg lists of all callers).http://www.sauria.com/blog/2009/02/20/refactoring-in-the-fun...
Uncurry Method (merge split parameter list, including merging the arg lists of callers. If method is called with partial args, either complain or automatically create a helper method which represents the partial application, and replace partial calls with it.)
Extract Trait (including searching for other classes which can have the same trait extracted. Tricky with super calls, but not impossible)
Split Trait (splits trait into two traits (putting in self-types if needed change all extending classes to extend both traits)
Extract Extractor (select a pattern, automatically create an extractor)
Extract Closure (similar to extract method, but creating a function object)
Introduce by-name parameter
Extract type definition (obvious)
Merge nested for-comprehensions into single for-comprehension (and converse)
Split guard from for-comprehension into nested if (and converse)
Convert for-comprehension into map/filter/flatmap chain (and converse)
Wrap parameter as Option (converting null checks, etc.)
Convert instanceOf/asInstance pair to match
Replace case clause with if body to guarded case clause(s)
не приводит к появлению в коде больших функций, требующих злостного автоматизированного рефакторинга.Какая есть связь между автоматическим рефакторингом и большими функциями?
Ok, иначе скажу: лисп и другие ФЯ прививает модель разработки, которая, как правило, не приводит к появлению в коде больших функций, требующих злостного автоматизированного рефакторинга.Ответ: Для того, чтобы часть наших мыслительных операций заменить механическими преобразованиями.
Ты обещал по сути ответить на вопрос "зачем". Ответ-то будет?
Это я и описал в . Дополню его в контексте твоего поста. Просто поразительно насколько твои слова похожи на:
ДАВНЫМ ДАВНО, В ДОБРОЕ СТАРОЕ ВРЕМЯ, любили в школе текстовые арифметические задачи.Методам их решения, зачастую весьма изощрентным, учили долго и тщательно, и умения эти сохранялись навсю жизнь. При этом школа не только учила методам, но ивоспитывала вкус – арифметическое решение считалосьболее красивым, чем алгебраическое.
http://kvant.mccme.ru/pdf/2002/03/46.pdf
Есть две абстракции A1 и A2. У каждой абстракции определена своя операция с именем Op. Затем пишется некоторая функция MyF с аргументом. У аргумента вызывается метод Op. Функция MyF имеет смысл только для абстракции типа A1. Распиши реализацию алгоритма навигации, которая работает следующим образом. Когда ищем вызов Op для абстракции A1, то функция MyF попадает в результат поиска. Когда ищем вызов Op для абстракции A2, то функция MyF не попадает в результат поиска.Зачем такая навигация?
Ну вот будет у тебя (синтаксис не помню, пишу приблизительно)
interface I1 {
void DoSmth(void);
};
class B1 implements I1 {
private A1 a;
public void DoSmth(void) { a->Op; }
};
Навигация отлично покажет, что A1.Op вызывается из B1.DoSmth
И что?
Как нам узнать, кто вызывает B1.DoSmth, если это делается только через интерфейс I1, сответственно где-то стоит
I1 myI1;
...
myI1 = factory.getSomeObject(...);
...
myI1.doSmth;
в factory.getSomeObject какая-нибудь сложная логика, какую из реализаций I1 тебе дать, там у какого-нибудь сервера в облаке спросят что-то.
Насколько я понимаю, это типичная ситуация, именно так и надо писать, не?
в сложных (больших) задач - когда не получается достичь точного ответа довольствуются оценками сверху или снизу. Чем более точными будут такие оценки - тем лучше.
grep при поиске имени, например, дает сильно задранную оценку сверху вместо точного ответа.
В данном случае, получение ответа в виде "все куски кода, которые возможно вызывают a->Op" уже очень хорошо. Это многократно быстрее, чем тоже самое делать руками.
grep при поиске имени, например, дает сильно задранную оценку сверху вместо точного ответа.
В данном случае, получение ответа в виде "все куски кода, которые возможно вызывают a->Op" уже очень хорошо. Это многократно быстрее, чем тоже самое делать руками.
Как нам узнать, кто вызывает B1.DoSmthДавай разберемся в смысле твоих слов. Что у тебя означает слово "кто" ? Есть точки исходного кода, это тройки Ln, Col, FullFileName. Ответа на твой вопрос в терминах этих троек просто нельзя дать (вырожденные случаи не расстраиваем). Видимо, твоё слово "кто" означает нечто в рантайме.
Видимо, твоё слово "кто" означает нечто в рантайме.Кстати, в этом и есть претензия к тем языкам, они слишком много вопросов выводять в область рантайма, хотя часть вопросов можно решить на уровне троек Ln, Col, FullFileName.
Ответ: Для того, чтобы часть наших мыслительных операций заменить механическими преобразованиями.Вопрос был не в том, зачем нужен автоматический рефакторинг. Вопрос был в том, чтобы ты привел реальный пример а-ля твой MyF из жизни, со сложными интерфейсами и т.п., чтобы авторефакторинг из явы-цешарп его все еще проглотил и был молодцом, а руками там было бы сложно и долго, а на лиспе так и вообще тухло.
Пойми, я не против того, что рефакторинг нужен. Мое утверждение заключается в том, что при разумной организации кода, даже на той же яве, автоматизированный рефакторинг не имеет того бесконечного количества достоинств, которые ты ему приписываешь. Хотя бы потому, что даже на яве авторефакторинг не дает тебе никакой гарантии корректности преобразований, а следовательно голова по-прежнему нужна, будет участвовать в процессе, и не факт что будет менее нагружена.
Хотя бы потому, что даже на яве авторефакторинг не дает тебе никакой гарантии корректности преобразований, а следовательно голова по-прежнему нужна, будет участвовать в процессе, и не факт что будет менее нагружена.для этого есть автоматизированной (а не просто автоматический) рефакторинг, когда tool дает места на которые надо обратить внимание и предлагает способы исправления, а человек уже принимает решения как конкретно сделать исправление.
Мое утверждение заключается в том, что при разумной организации кода, даже на той же яве, автоматизированный рефакторинг не имеет того бесконечного количества достоинств, которые ты ему приписываешь.чтобы это утверждение было верным, то разумная организация кода должна давать уменьшение CLOS на порядки, она же обычно дает улучшения лишь на десятки процентов. А значит при внесении изменения лопатить придется ровно тот же объем кода, что и обычно.
для этого есть автоматизированной (а не просто автоматический) рефакторинг, когда tool дает места на которые надо обратить внимание и предлагает способы исправления, а человек уже принимает решения как конкретно сделать исправление.Для лиспа такой инструмент называется 'grep'.
чтобы это утверждение было верным, то разумная организация кода должна давать уменьшение CLOS на порядки, она же обычно дает улучшения лишь на десятки процентов. А значит при внесении изменения лопатить придется ровно тот же объем кода, что и обычно.Вопрос не в том, сколько лопатить, вопрос в том, насколько сложно найти места *где* лопатить. Разумная организация кода вопрос *где* решает очень эффективно, и необходимость в инструментах сложнее grep как правило отпадает.
Хотя бы потому, что даже на яве авторефакторинг не дает тебе никакой гарантии корректности преобразований, а следовательно голова по-прежнему нужна, будет участвовать в процессе, и не факт что будет менее нагружена.Подобная дискуссия . Тогда Шуреск утверждал, что с помощью автоматического рефакторинга можно сделать вообще всё, что угодно. Конечно, он сел в лужу, но так и не смог этого признать. С тех пор он раз в пол года толкает одно и то же под разными предлогами. Заголовки тем меняются так, чтобы привлечь новую аудиторию к высмеиванию собственной глупости. Конструктивный разговор здесь невозможен так же, как и раньше.
…including Common Lisp, ага.
Что у тебя означает слово "кто" ? Есть точки исходного кода, это тройки Ln, Col, FullFileName. Ответа на твой вопрос в терминах этих троек просто нельзя дать (вырожденные случаи не расстраиваем).ну да, нельзя
это алгоритмически неразрешимая задача
а что тогда делает твоя крутая навигация?
лисп и другие ФЯкстати
Ты что сказать-то этим хочешь?
Ты что сказать-то этим хочешь?Что навигация/автоматический рефакторинг не коррелируют с функциональностью.
И что? Ну, ты мысль закончи, или даже лучше всю мысль от начала до конца одним посмтом?
... прививает модель разработки ...У тебя красной нитью проходит термин "разумная организация кода". То есть усилия по организации кода ложатся полностью на плечи человеческого разума. Однако часть этих усилий можно заменить механическими преобразованиями. См. пример ниже.
Мое утверждение заключается в том, что при разумной организации кода ...
Условие задачи состоит из трех пунктов.
1. Алгоритм вычисления числа пи с помощью метода Монте-Карло [ref1]:
(define (estimate-pi trials)
(sqrt (/ 6 (random-gcd-test trials random-init
(define (random-gcd-test trials initial-x)
(define (iter trials-remaining trials-passed x)
(let x1 (rand-update x
(let x2 (rand-update x1
(cond = trials-remaining 0)
(/ trials-passed trials
= (gcd x1 x2) 1)
(iter (- trials-remaining 1)
(+ trials-passed 1)
x2
(else
(iter (- trials-remaining 1)
trials-passed
x2
(iter trials 0 initial-x
2. Соблюсти принцип модульности: выразить метод Монте-Карло в виде обобщенной процедуры (general monte-carlo procedure). Это понятие подробно расписано в абзаце, который идет сразу за кодом [ref1]:
While the program is still simple, it betrays some painful breaches of modularity. In our first version of the program, using rand, we can express the Monte Carlo method directly as a general monte-carlo procedure that takes as an argument an arbitrary experiment procedure. In our second version of the program, with no local state for the random-number generator, random-gcd-test must explicitly manipulate the random numbers x1 and x2 and recycle x2 through the iterative loop as the new input to rand-update. This explicit handling of the random numbers intertwines the structure of accumulating test results with the fact that our particular experiment uses two random numbers, whereas other Monte Carlo experiments might use one random number or three. Even the top-level procedure estimate-pi has to be concerned with supplying an initial random number. The fact that the random-number generator's insides are leaking out into other parts of the program makes it difficult for us to isolate the Monte Carlo idea so that it can be applied to other tasks. In the first version of the program, assignment encapsulates the state of the random-number generator within the rand procedure, so that the details of random-number generation remain indepent of the rest of the program.
3. Реализовать без состояния.
Решение в учебнике MIT на Lisp – они вводят понятие stream. Но как они догадались до такого понятия? Как опыт нахождения понятия stream распространить на другие задачи (где потребуются другие понятия)? Как придумывать такие полезные понятия как stream? Эти вопросы в книге не поднимаются. Оказывает, что понятие stream можно вывести, а не придумывать.
Могу продемонстрировать вывод понятия stream. Надо расписывать?
Могу продемонстрировать вывод понятия stream. Надо расписывать?Да, распиши, пожалуйста, как автоматический рефакторинг без использования мозга его выводит. Будет интересно.
Ты опять же про другое пишешь. Никто не спорит: да, нужен рефакторинг. Спорным является твое утверждение о безусловном перимуществе инструментов авторефакторинга над "grep+голова". Напомню, на всякий случай, с чего началось:
Распиши реализацию алгоритма навигации, которая работает следующим образом. Когда ищем вызов Op для абстракции A1, то функция MyF попадает в результат поиска. Когда ищем вызов Op для абстракции A2, то функция MyF не попадает в результат поиска.
В том то и фишка, что алгоритмы компилятора и алгоритмы навигации часто идут парой. Я о том и толкую, что если у вас в дизайн языка вошло нечто, из которого можно вывести алгоритм навигации, то вы получите навигацию, если язык вам дал полную свободу, то и нормальной навигации вы не получите.
Теперь в инструменте навигации говорим, покажи все вызовы вот этого метода:и так далее.
Мне действительно очень интересно было бы увидеть пример того, как автонавигация/авторефакторинг разгружают мозг и почти убивают серебром наповал всех, кто пишет не на яве/цешарпе. Про пользу рефакторинга не надо, спаибо, мы в курсе. Вопрос же не в этом был изначально.
Разумная организация кода вопрос *где* решает очень эффективно, и необходимость в инструментах сложнее grep как правило отпадает.т.е. общие либы (код используемый в нескольких проектах) никогда не рефакторятся?
т.е. общие либы (код используемый в нескольких проектах) никогда не рефакторятся?Давай так: абстрактные рассуждения нафиг, конкретные примеры в студию. Опиши реалистичную, а не притянутую за уши/фантастическую ситуацию, когда авторефакторинг/супернавигация в этом случае существенно помогает по сравнению с grep. См. также "гарантия корректности".
Выяснилось, что в библиотечной функции zzz содержится ошибка, исправление которой приведет к изменению семантики работы функции zzz.
в связи с этим:
1. функцию zzz переименовать в zzz_old с заменой во всех проектах, и объявить deprecated
2. исправленный вариант положить под именем zzz
3. за заданный срок все использования zzz_old заменить на zzz, и убрать zzz_old из библиотеки.
zzz является простым именем, вида open, read и т.д. (есть большое кол-во пересечений этого имени с именами функций из других библиотек)
в связи с этим:
1. функцию zzz переименовать в zzz_old с заменой во всех проектах, и объявить deprecated
2. исправленный вариант положить под именем zzz
3. за заданный срок все использования zzz_old заменить на zzz, и убрать zzz_old из библиотеки.
zzz является простым именем, вида open, read и т.д. (есть большое кол-во пересечений этого имени с именами функций из других библиотек)
Выяснилось, что в библиотечной функции zzz содержится ошибка, исправление которой приведет к изменению семантики работы функции zzz.Выяснилось, что в библиотечной функции zzz содержится ошибка, исправление которой приведет к изменению семантики работы функции zzz.
в связи с этим:
1. функцию zzz переименовать в zzz_old с заменой во всех проектах, и объявить deprecated
2. исправленный вариант положить под именем zzz
3. за заданный срок все использования zzz_old заменить на zzz, и убрать zzz_old из библиотеки.
zzz является простым именем, вида open, read и т.д. (есть большое кол-во пересечений этого имени с именами функций из других библиотек)
В связи с этим:
1. В функцию zzz воткнуть DeprecationWarning, вылезающий при компиляции.
2. Исправленный вариант положить под именем zzz_correct.
3. Никогда не доверять тому, что инструмент найдет all usages на самом деле, да еще и во всех проектах копании.
4. Предложившего рефакторинг, да еще и в "заданные сроки" - лишить премии и отправить доучиваться по специальности.
См. также "гарантия корректности".
2. Исправленный вариант положить под именем zzz_correct.в итоге, с таким подходом через пару лет с такой библиотекой работать становится не возможно из-за имен вида:
zzz_correct_2, xxx_new_4 и т.д.
в итоге, с таким подходом через пару лет с такой библиотекой работать становится не возможно из-за имен вида:Я не сомневаюсь, что с ненулевой вероятностью ломать то, что работало раньше, бесусловно правильнее.
zzz_correct_2, xxx_new_4 и т.д.
См. также CreateFile2, IClassFactory2 и так далее (точно помню, что там еще какие-то 3 где-то были, но под винду уже много лет ничего не писал, забылось).
См. также CreateFile2, IClassFactory2 и так далее (точно помню, что там еще какие-то 3 где-то были, но под винду уже много лет ничего не писал, забылось).я исхожу из того, что сейчас мы рассматриваем внутреннюю кухню. И это означает, что семантика какого-нибудь CreateFile на этапе альфа и бета может меняться чуть ли не каждый день, и так может быть раз 30 прежде чем устаканиться окончательный вариант.
При этом за всё это время активно пишутся примеры и готовые проги под имеющийся вариант либы.
См. также CreateFile2, IClassFactory2 и так далеетак приходится делать, если либа отдается на сторону, потому что сторонний код уже не отрефакторишь. Но на сторону версии отдаются много реже, чем внутренние изменения версий.
И даже при отдаче на сторону периодически релизятся версии не совместимые с предыдущими, ради того, чтобы новый код, использующий либы - был "красивым".
И это означает, что семантика какого-нибудь CreateFile на этапе альфа и бета может меняться чуть ли не каждый деньесли ты только вчера писал код, то ты и так помнишь, в каком месте там был вызов
я исхожу из того, что сейчас мы рассматриваем внутреннюю кухню. И это означает, что семантика какого-нибудь CreateFile на этапе альфа и бета может меняться чуть ли не каждый день, и так может быть раз 30 прежде чем устаканиться окончательный вариант.То ты про библиотеку, то вдруг оказывается, что это какая-то альфа-наработка. Ты уж определись: это библиотека, от которой много чего зависит (= много рефакторинга или что-то альфа-текучее, от которого мало чего зависит по определению (= мало рефакторинга, и плевать что git grep open).
При этом за всё это время активно пишутся примеры и готовые проги под имеющийся вариант либы.
В первом случае тебе действительно важна гарантия корректности, и ты вряд ли успокоишься сделав авторенейм => инструменты рефакторинга помогают, но не очень. Во втором случае руками много лопатить не предется => инструменты рефакторинга вообще не особо нужны.
Мне кажется, для решения этой проблемы давно уже принято использовать принцип создания API, отвязанное от внутренних функций. И горе тем программистам, которые вместо того, чтобы линковаться с API линкуются с внутренними функциями.
Выяснилось, что в библиотечной функции zzz содержится ошибка, исправление которой приведет к изменению семантики работы функции zzz.Я, кстати, не знаю, как там в додиезе и студии, но в жаве и idea, например, совершенно никаких гарантий, что ты найдёшь все случаи использования метода. Пишешь, например, RPC, который регистрирует методы аннотациями, а дёргает нужный метод по сигнатуре параметров — и, собственно, всё, беда.
То ты про библиотеку, то вдруг оказывается, что это какая-то альфа-наработка.и то, и другое. Кейс примерно следующий.
Через год намечена дата релиза, под это надо выпустить несколько десятков похожих модулей.
Модули большие и чтобы успеть их к сроку выпустить разработка раскидана по 3-10 людям. Каждый пишет свой набор модулей. Модули по критичности разные, а денег ограниченное кол-во, поэтому уровень разработчиков, делающих модули, различен, вплоть до стажеров.
Чтобы код не дублировался принято решение, что общий код для работы модулей выносится в либу, которые все используют.
Также есть общий инфраструктурный код, который или работает с модулями, или предлагает набор сервисов для модулей.
Для конкретности допустим надо зарелизить хитрый графический редактор, а каждый модуль - это или какой-то примитив, или эффект, или еще что-то подобное. (при этом считаем, что это хитрый редактор, поэтому каждый примитив действительно сложный и требует на кодирование пару человеко-месяцев)
Жизнь осложняется тем, что периодически:
1. тестер докладывает, что есть ошибка в zzz, а разработчик утверждает, что для исправления ошибки придется изменить семантику существующего кода в либе и/или инфраструктуре
2. performance tester докладывает, что текущий код не проходит по производительности на больших проектах, а разработчик заявляет, что это потребует изменение архитектуры либы и/или инфраструктуры
3. разработчик модуля докладывает, что пожелание Zzz не возможно сделать на существующей либе/инфраструктуре без добавления фичи Xxx в них, что требует изменение семантики работы существующей либы и/или инфраструктуры
4. сервис докладывает, что опытная альфа-версия не взлетела в окружении заказчика, потому что на этапе постановки задачи пропустили несколько нюансов, и часть из них по мнению разработчика опять же требует изменение семантики либы/инфраструктуры.
Это все хорошо, но какое отношение это имеет к инструментам автоматизированного рефакторинга? Мы же уже вроде договорились, что они лажают все равно, а значит либо grep с мозгами, либо MyFunction2, MyFunction3, ... или я что-то путаю?
Мы же уже вроде договорились, что они лажают все равно, а значит либо grep с мозгамиавтоматизированный рефакторинг с мозгами лажает сильно меньше, чем grep с мозгами.
автоматизированный рефакторинг с мозгами лажает сильно меньше, чем grep с мозгами.Необоснованно. Я могу с тем же успехом заявить, что автоматизированный рефакторинг с мозгами лажает сильно больше, чем grep с мозгами, ибо первый усыпляет бдительность.
Я могу с тем же успехом заявить, что автоматизированный рефакторинг с мозгами лажает сильно больше, чем grep с мозгами, ибо первый усыпляет бдительность.grep ровно также усыпляет бдительность, как и автоматизированный рефакторинг: что не найдет автоматизированный рефакторинг, то и не найдет grep.
grep ровно также усыпляет бдительность, как и автоматизированный рефакторинг.Итог дискуссии: "все фигня, жизнь дерьмо, инструменты не при чем". Так что ли?
если пытаться разобраться, что лучше: обезьяна с автоматизированным рефакторингом или умный человек с grep?, то, конечно, в итоге всё упрется в то, что всё тлен.
Если же вопрос стоит, что лучше (что производит больше кода с меньшими проблемами): умный человек с автоматизированным рефакторингом или умный человек с grep?, то ответ: первый вариант.
Если же вопрос стоит, что лучше (что производит больше кода с меньшими проблемами): умный человек с автоматизированным рефакторингом или умный человек с grep?, то ответ: первый вариант.
См. также CreateFile2, IClassFactory2 и так далее (точно помню, что там еще какие-то 3 где-то были, но под винду уже много лет ничего не писал, забылосьСтранно, что никто не заметил, что пример вообще не в тему.
Интерфейс функции CreateFile2 не соответствует интерфейсу CreateFile (т.к. это, вообще говоря, совершенно новый API). И этот костыль с нумерацией был сделан потому что в WinAPI не предусмотрена перегрузка функций по числу и типов параметров. Никакого отношения к тому, о чём говорит Шурик это не имеет.
Почему только скриптовые динамические языки?OCaml
Чтобы код не дублировался принято решение, что общий код для работы модулей выносится в либу, которые все используют.как ты себе это представляешь? каждый день митинг, где сравнивают код, написанный каждым, и общее выносят в либу?
Странно, что никто не заметил, что пример вообще не в тему.Это как раз пример того, о чем пишет: "...исправление которой приведет к изменению семантики работы функции zzz..."
Интерфейс функции CreateFile2 не соответствует интерфейсу CreateFile (т.к. это, вообще говоря, совершенно новый API). И этот костыль с нумерацией был сделан потому что в WinAPI не предусмотрена перегрузка функций по числу и типов параметров. Никакого отношения к тому, о чём говорит Шурик это не имеет.
Для лиспа такой инструмент называется 'grep'.вроде бы лучше не совсем обычный grep, а специальный, чтоб квотинг и ескейпинг понимал - это вроде как несколько строчек на том же лиспе
как ты себе это представляешь? каждый день митинг, где сравнивают код, написанный каждым, и общее выносят в либу?один из сильных разработчиков пускается заранее за 2-4 недели: закодить 2-3 модуля с задачей по-максимуму вынести общий код в либу
остальным ставиться задача кодить модули, используя наработки первого.
первому ставиться доп. задача периодически ревьювить код остальных, и править на основе этого либу, и выдавать рекомендации и тикеты по перекодированию остальных модулей.
один из сильных разработчиков пускается заранее за 2-4 недели: закодить 2-3 модуля с задачей по-максимуму вынести общий код в либустажёр не разберётся в этой либе до самого дедлайна
надо api обсуждать так, чтобы все поняли, почему и зачем оно такоеему не надо разбираться. ему надо делать также )
ps
конечно, желательно, чтобы рассказывалась метафора устройства модуля, и бегло описывались основные функции
ps
конечно, желательно, чтобы рассказывалась метафора устройства модуля, и бегло описывались основные функции
Для того, чтобы часть наших мыслительных операций заменить механическими преобразованиями.ага, а потом рождаются фреймворки, которые чтобы заменить в html bgcolor на 1-м шаблоне делают 1000 транзакций к базе.
понятно, что отследить эти 1000 транзакций нельзя. и потому надо обязательно родить поисковик по коду. который позволил бы более легче рефракторить код, необходимый для 1000 транзакций
отрефракторенный же код будет занимать уже не 1000 строк, а 1000000 строк, для которого нужно будет оптимизировать поисковый код, которй бы позволил еще более эффективно заменить в html bgcolor
вы когда кодите - вас и семеро не удержат
Да, распиши, пожалуйста, как автоматический рефакторинг без использования мозга его выводит. Будет интересно.И так, у нас есть . Код из пункта 1 удовлетворят условию 3. Задача сводится к тому, чтобы преобразовать код из пункта 1 так, чтобы получилась обобщенная (general) функция Монте-Карло. Перепишем код на C#. Теперь наша цель сделать из RandomGcdTestIter обобщенную функцию MonteCarloIter.
Мне действительно очень интересно было бы увидеть пример того, как автонавигация/авторефакторинг разгружают мозг и почти убивают серебром наповал всех, кто пишет не на яве/цешарпе. Про пользу рефакторинга не надо, спаибо, мы в курсе. Вопрос же не в этом был изначально.
Отметим красным фрагменты кода, которые относятся к частной задаче, а не к обобщенной функции Монте-Карло.

Нам надо, чтобы эти фрагменты кода ушли в параметр функции, тогда функция станет обобщенной.
Фрагмент F1 содержит детали частной реализации генератора случайных чисел. Другая реализация случайных чисел может использовать не один целочисленный параметр, а несколько. Для того, чтобы отделить эти детали от обобщенной функции, инкапсулируем параметр x в отдельный класс. Другими словами, сделаем обертку над x. Делаем это с помощью Extract Class from Parameters. См. код. Можно смотреть diff-ы. Для того, чтобы объединить частные фрагменты F2 и F3, сделаем Introduce Variable для "new RandomGcdTestIterParams(x2)".
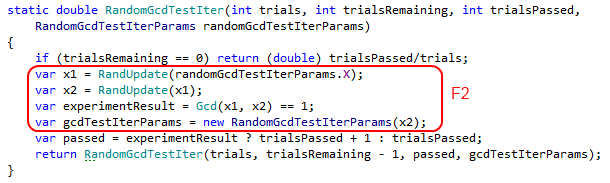
Выделим фрагмент F2 в отдельный метод Experiment. Используем Extract Method и Transform Out Parameters. См. код. С помощь Make Method Non-Static переносим метод Experiment в класс RandomGcdTestIterParams. См. код.
Мы достигли промежуточной цели: тело метода RandomGcdTestIter представляет собой обобщенный алгоритм Монте-Карло. Осталось сделать аргумент randomGcdTestIterParams полиморфным, чтобы была возможность передавать в метод другие реализации. Делаем Extract Interface и Use Base Type Where Possible. См. код.
Переименовываем IRandomGcdTestIterParams в IExperiment, RandomGcdTestIterParams в CesaroTest, RandomGcdTestIter в MonteCarloIter, RandomGcdTest в MonteCarlo. В методе MonteCarlo для выражения "new CesaroTest(initialX)" делаем Introduce Parameter. Для параметра initialX делаем Remove parameter. См. код.
Мы получили обобщенную функцию MonteCarlo. Все выполнены, задача решена. Перейдем ко второй задаче.
Задача 2. Сделать CesaroTest независимым от конкретной реализации генератора случайных чисел. Другими словами, вынести реализацию генератора случайных чисел за скобки.
Делаем Extract Class from Parameters для функции RandUpdate. См. код. Теперь нам нужно избавиться от вызовов конструктора RandUpdateParams внутри класса CesaroTest. Вызов в строчке "var x1 = RandUpdate(new RandUpdateParams(x;" легко убрать, сделав соответствующий параметр в конструкторе CesaroTest. Для этого делаем Introduce Field, в конструкторе CesaroTest Introduce Parameter и Remove parameter. См. код. Теперь избавимся от второго вызова конструктора. Выполняем следующие . Получаем метод X1. С двумя строчками ниже можно проделать тоже самое и увидеть, что X2 будет полностью совпадать с X1, а можно сразу увидеть, что эти две строчки можно заменить на вызов X1. С помощь Make Method Non-Static переносим метод X1 в класс RandUpdateParams. Переименовываем X1 в Next. См. код.
Аналогично задаче 1 выделяем из класса RandUpdateParams интерфейс. См. код.
Интерфейсы IExperiment и IRandom очень похожи. Их можно заменить на один интерфейс с generic параметром IStream<T>. См. код.
Таким образом, понятие stream просто выводится как двухступенчатое обобщение. Мы его не придумывали.
Прошу глубоко вникнуть в содержание этого поста, поскольку предыдущие и последующие обсуждения опираются и будут опираться на этот пост.
Отметим красным фрагменты кода, которые относятся к частной задаче, а не к обобщенной функции Монте-Карло.
Прежде чем выполнить полностью автоматический рефакторинг, не забудьте сделать скриншоты вашего кода и выделить нужные фрагменты красным.
Прошу глубоко вникнуть в содержание этого поста, поскольку предыдущие и последующие обсуждения опираются и будут опираться на этот пост.
С помощью автоматического рефакторинга преобразования были выполнены всего за 2 дня, 18 строк удалось заменить на 66, и никаких усилий по организации кода! Не то что на ваших Петонах.
Интерфейсы IExperiment и IRandom очень похожи. Их можно заменить на один интерфейс с generic параметром IStream<T>. См. код.Первое же нетривиальное преобразование выполнено с помощью grep.

Вот этот код меня особенно впечатлил:
"Ехал Tuple через Tuple,
видит Tuple в реке Tuple.
Сунул Tuple Tuple в Tuple
Tuple Tuple Tuple Tuple."
Еще расскажи, пожалуйста, почему так получилось, что исходная функция, которую ты авторефакторишь, у тебя рекурсивная? Вроде как C# императивный язык, и программисты на нем не гнушаются циклов?
Лучше начать с более жизненной реализации:
var tuple = random.Do;
var tuple1 = tuple.Item2.Do;
IExperiment item2 = new CesaroTest(tuple1.Item2);
return Tuple.Create(Gcd(tuple.Item1, tuple1.Item1) == 1, item2);
"Ехал Tuple через Tuple,
видит Tuple в реке Tuple.
Сунул Tuple Tuple в Tuple
Tuple Tuple Tuple Tuple."
Еще расскажи, пожалуйста, почему так получилось, что исходная функция, которую ты авторефакторишь, у тебя рекурсивная? Вроде как C# императивный язык, и программисты на нем не гнушаются циклов?
Лучше начать с более жизненной реализации:
int x1;
int trialsPassed = 0;
for ( int trials = 0; trials < totalTrials; trials++)
{
x = RandUpdate(x);
x1 = RandUpdate(x);
if (Gcd(x, x1) == 1)
{
trialsPassed++;
};
}
return trialsPasses * 1.0 / totalTrials;
Еще расскажи, пожалуйста, почему так получилось, что исходная функция, которую ты авторефакторишь, у тебя рекурсивная? Вроде как C# императивный язык, и программисты на нем не гнушаются циклов?ReSharper мне об этом сообщил в самом начале. См. зеленую черточку. ReSharper может сам сделать из рекурсии цикл:
Лучше начать с более жизненной реализации:
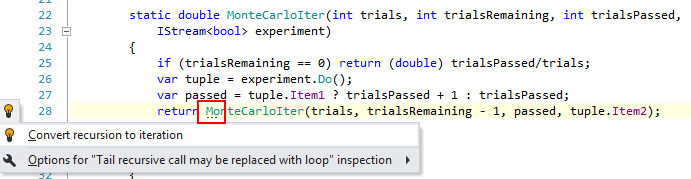
Я решил не конвертировать в цикл, поскольку задачка учебная.
Вот этот код меня особенно впечатлил:Чем именно он тебя впечатлил? В самой задаче две переменные x1 и x2, теперь tuple1, tuple2.
Или тебя смущают название свойств системного класса Item1 и Item2? Можно ввести специализированный класс со свойствами Value и Next. Но Item1 и Item2 в данном случае не путаются друг с другом, поэтому потребность в специализированном классе не большая.
Слона-то ты и не заметил. Все эти IExperiment, IRandom и иже с ними совершенно не нужны если ты можешь писать лямбды, замыкать, каррить и т.д., да еще и делать это лениво.
То есть:
Обрати внимание: у этого кода уровень абстракции существенно выше, и повторно использовать его проще. Например, чтобы заменить генератор случайных чисел, можно сделать что-то вроде:
Или там можно тест поменять как два пальца:
Конечно, голова для этого нужна. Инструменты тут не помогают...
То есть:
(defn gcd [a b] (if (zero? b) a (recur b (mod a b
(defn rand [x]
(let [a 27 b 26 m 127
r (mod (+ (* a x) b) m)]
(lazy-seq (cons r (rand r
(defn unused [s] (if (realized? s) (recur (rest s s
(defn cesaro-test [random-seq]
(let [[a b] (take 2 random-seq)]
(= (gcd a b) 1
(defn monte-carlo [test random-seq]
(let [result (test random-seq)
next-random (unused random-seq)]
(lazy-seq (cons result (monte-carlo test next-random
(defn summarize-results [results]
(reduce (fn [[passed failed] test]
(if test [(inc passed) failed]
[passed (inc failed)] [0 0] results
(defn estimate-pi
[ntrials random-seq]
(let [results (take ntrials (monte-carlo cesaro-test random-seq
[passed failed] (summarize-results results)]
(Math/sqrt (/ 6 (/ passed (+ passed failed
(println (estimate-pi 10000 (rand 0
Обрати внимание: у этого кода уровень абстракции существенно выше, и повторно использовать его проще. Например, чтобы заменить генератор случайных чисел, можно сделать что-то вроде:
(defn better-rand []
(lazy-seq (cons (rand-int Integer/MAX_VALUE) (better-rand
(println (estimate-pi 100000 (better-rand
Или там можно тест поменять как два пальца:
(defn square-test
[max-value random-seq]
(let [[x y] (take 2 random-seq)]
(<= (+ (* x x) (* y y (* max-value max-value
(defn estimate-pi-squares
[ntrials random-seq max-value]
(let [results (take ntrials (monte-carlo #(square-test max-value %) random-seq
[passed failed] (summarize-results results)]
(float (/ (* 4 passed) (+ passed failed
(println (estimate-pi-squares 1000 (rand 0) 126
(println (estimate-pi-squares 1000 (better-rand) Integer/MAX_VALUE
Конечно, голова для этого нужна. Инструменты тут не помогают...
public interface IStream<T>
{
Tuple<T, IStream<T>> Do;
}
Почему интерфейс, а не делегат?
Все эти IExperiment, IRandom и иже с ними совершенно не нужны если ты можешь писать лямбды, замыкать, каррить и т.д., да еще и делать это лениво.Интерфейс с одним методом заменяется на делегат. С этим примером я игрался в марте и об этом. Там как раз вместо интерфейсов был делегат. Т.е. лямбды и замыкания были. Да, карринга и ленивости в C# нет.
Слона не видишь как раз ты. За фичами языка ты не видишь главной фичи, которая дает выводить нужный уровень абстракции по требованию. Не всегда же программы нужно писать на возможно более глубоком уровне абстракции:
As programmers, we should be alert to opportunities to itify the underlying abstractions in our programs and to build upon them and generalize them to create more powerful abstractions. This is not to say that one should always write programs in the most abstract way possible; expert programmers know how to choose the level of abstraction appropriate to their task. But it is important to be able to think in terms of these abstractions, so that we can be ready to apply them in new contexts. The significance of higher-order procedures is that they enable us to represent these abstractions explicitly as elements in our programming language, so that they can be handled just like other computational elements.
http://mitpress.mit.edu/sicp/full-text/book/book-Z-H-12.html...
Так вот. Замечательным свойством языка является, то что он позволяет выводить новые уровни абстракции и перемещаться по шкале абстракций (и вверх и вниз) с помощью механических преобразований.
Почему интерфейс, а не делегат?В марте делегат.
Я изначально выводил это всё, начиная с класса. Можно ли произвести вывод с делегатом, я пока не думал об этом. Прямого преобразования интерфейса в делегат в ReSharper-е пока нет.
Так вот. Замечательным свойством языка является, то что он позволяет выводить новые уровни абстракции и перемещаться по шкале абстракций (и вверх и вниз) с помощью механических преобразований.... Увеличивая каждым преобразованием объем кода в 2-3 раза, и усложняя работу без инструментов на порядки. Твой point понятен.
Но мы отвлеклись, и весь этот твой пример, на самом деле, был совсем не о том, о чем был спор. Еще раз, напомню. Твоя главная претензия, как следует из того, что ты писал раньше, в том, что для всяких там лиспов и т.п. нету инструментов навигации/трансформации, которые бы справлялись с примерами типа:
Напиши на любимом диалекте лиспа следующее. Есть две абстракции A1 и A2. У каждой абстракции определена своя операция с именем Op. Затем пишется некоторая функция MyF с аргументом. У аргумента вызывается метод Op. Функция MyF имеет смысл только для абстракции типа A1. Распиши реализацию алгоритма навигации, которая работает следующим образом. Когда ищем вызов Op для абстракции A1, то функция MyF попадает в результат поиска. Когда ищем вызов Op для абстракции A2, то функция MyF не попадает в результат поиска.Ты привел пример на порядки проще, с рефакторингом которого, если уж на то пошло, элементарно справится любая среда разработки на лиспе. Приведи сложный пример, а? Ну и тоже, чтобы там рефакторинг глубокомысленные выводы сделал.
Да, карринга и ленивости в C# нет.не правда
http://ru.wikipedia.org/wiki/%D0%9A%D0%B0%D1%80%D1%80%D0%B8%...
http://en.wikipedia.org/wiki/Lazy_evaluation#Implementation
Прямого преобразования интерфейса в делегат в ReSharper-е пока нет.Что, кстати, в таких случаях делают поклонники автоинструментов?
Ты привел пример на порядки проще, с рефакторингом которого, если уж на то пошло, элементарно справится любая среда разработки на лиспе.Как раз забыл тебя попросить. Я подробно расписал какие команды выполнял. Распиши теперь ты работу с grep-ом, какие регулярки писать будешь, какие команды выполнять.
Что, кстати, в таких случаях делают поклонники автоинструментов?Но навигация же есть, ее и используют.
Как правило, с помощью авторефакторинга можно привести код к такому, чтобы вероятность ошибки при дальнейших ручных правках свести к мнимому. Например, в случае замены интерфейса на делегат, можно обернуть вызовы конструкторов в статические методы, собрать их в одном месте, и потом вручную заменить классы на лямбды. Потом заинлайнить статические методы.
Я подробно расписал какие команды выполнял. Распиши теперь ты работу с grep-ом, какие регулярки писать будешь, какие команды выполнять.Ты будешь удивлен, но в данном случае достаточно метода простого взгляда.
В общем случае, git grep '(имя-функции ', или в чем вопрос? Или тебя удивляет, что cut-paste хорошо работает в данном случае как extract-что-угодно и transform-куда-угодно? Навигация по определениям, кстати, в emacs и всяких lispworks/allegro имеется, даже есть всякие clojure-jump-between-tests-and-code или там subclass/superclass graph и подобные.
Например, в случае замены интерфейса на делегат, можно обернуть вызовы конструкторов в статические методы, собрать их в одном месте, и потом вручную заменить классы на лямбды. Потом заинлайнить статические методы.Звучит очень сексуально!
Предлагаю тебе решить гораздо более сложную и интересную проблему: подсказывать как надо рефакторить код.
Щас набор твоих колдунств от использования умного грепа не сильно отличается, а будет просто волшебно: жмешь тычку "оптимизируй это" и все само рефакторится.
Щас набор твоих колдунств от использования умного грепа не сильно отличается, а будет просто волшебно: жмешь тычку "оптимизируй это" и все само рефакторится.
Увеличивая каждым преобразованием объем кода в 2-3 раза, и усложняя работу без инструментов на порядки. Твой point понятен.Ты про какой объем кода? Про промежуточные версии кода, возникающие во время преобразований? Так кого это волнует? Их видит только тот, кто производит рефакторинг. Они не попадают в общую ветку в source control.
А вот объем кода, который попадает в source control, определяется условиями задачи.
Ты про какой объем кода? Про промежуточные версии кода, возникающие во время преобразований? Так кого это волнует? Их видит только тот, кто производит рефакторинг. Они не попадают в общую ветку в source control.Я про всякие IExperiment и подобную ерунду - они ж по сути нужны только из-за убогости выразительных средств выбранного тобой языка...
А вот объем кода, который попадает в source control, определяется условиями задачи.
Я вот смотрю на этот твой код, считаем: всего 66 строк, из них чем-то полезным заняты только: 3, 14-17, 38-39, с некоторой натяжкой 54-55, и 62-66. То есть 14 строк кода, 10 строк пустых, и еще 42 - уговариваем компилятор сделать то, что нам нужно. 64%, многовато.
Edit: я ж прекрасно понимаю, что эти 64% за тебя пишет IDE, но это все равно мусор, через который нужно продираться, который нужно держать в голове при работе и т.п...
Я вот смотрю на этот твой код, считаем: всего 66 строк, из них чем-то полезным заняты только: 3, 14-17, 38-39, с некоторой натяжкой 54-55, и 62-66. То есть 14 строк кода, 10 строк пустых, и еще 42 - уговариваем компилятор сделать то, что нам нужно. 64%, многовато.Если заменить интерфейс на делегат, то меньше http://gist.github.com/Test20130521/42d423948b51ecb1c92b/2c...
Если заменить интерфейс на делегат,То как мы выяснили выше, делать это все равно руками, ага?
То как мы выяснили выше, делать это все равно руками, ага?С очень небольшими правками руками. Буквально, написать вызов одного метода внутри пустой лямбды. Когда вставляем вызов метода Chain, руками надо убрать вызов рекурсивной функции во втором аргументе tuple-а. И всё.
С очень небольшими правками руками. Буквально, написать вызов одного метода внутри пустой лямбды. Когда вставляем вызов метода Chain, руками надо убрать вызов рекурсивной функции во втором аргументе tuple-а. И всё.А что, ты правда думаешь, что рефакторить лисп руками сильно сложнее?
А что, ты правда думаешь, что рефакторить лисп руками сильно сложнее?Рефакторить что? Перейти от интерфейса к делегату, для Лиспа это бессмыслица.
Ты привел пример на порядки проще, с рефакторингом которого, если уж на то пошло, элементарно справится любая среда разработки на лиспе. Приведи сложный пример, а?Не, так не пойдет. Я специально отдельным постом сначала запостил условие задачи. Ты такой, да, давай, тебе будет интересно посмотреть на решение. Теперь оказывается задача простая. Меняешь правила игры, так нечестно.
Приведи сложный пример, а?Так пишется open source проект Controllable Query. Когда он начинался, была только идея, а теперь смотри какой красавиц с почти идеальным синтаксисом.
Про коммерческие проекты я могу тоже рассказать, но это будут только слова, проектов не видно же.
Так пишется open source проект Controllable Query. Когда он начинался, была только идея, а теперь смотри какой красавиц с почти идеальным синтаксисом.

Простите, не удержался.
(defn monte-carlo ....Смотрим на факты.
Факт 1. висело два дня. Ты не написал решение на Лиспе. Через два дня я вывешиваю решение на C#. Ты переписываешь код на языке C# в код на языке Лисп. Ты думаешь, ты решил задачу? Нет, конечно. Всё что ты сделал, это перевел
Факт 2. Книга, из которой я взял задачу, является классическим учебником по программирования передового вуза мира. Курс лекций, на основе которого написана книга, читается с 80-х годов по сегодняшний день. Книгу много где рекомендуют к прочтению всем программистам. И при этом никто, читая вот этот абзац (см. ниже не сказал: "Ребят, да, полная чушь в этом абзаце написана, вот как это легко делается.", и привел бы твой код.
Когда я читал этот абзац, мне просто резало глаза. Я подумал не может такого быть, чтобы нельзя было провести рефакторинг по обобщению функции monte-carlo. Сел и проделал привычные вещи.
While the program is still simple, it betrays some painful breaches of modularity. In our first version of the program, using rand, we can express the Monte Carlo method directly as a general monte-carlo procedure that takes as an argument an arbitrary experiment procedure. In our second version of the program, with no local state for the random-number generator, random-gcd-test must explicitly manipulate the random numbers x1 and x2 and recycle x2 through the iterative loop as the new input to rand-update. This explicit handling of the random numbers intertwines the structure of accumulating test results with the fact that our particular experiment uses two random numbers, whereas other Monte Carlo experiments might use one random number or three. Even the top-level procedure estimate-pi has to be concerned with supplying an initial random number. The fact that the random-number generator's insides are leaking out into other parts of the program makes it difficult for us to isolate the Monte Carlo idea so that it can be applied to other tasks. In the first version of the program, assignment encapsulates the state of the random-number generator within the rand procedure, so that the details of random-number generation remain indepent of the rest of the program.
http://mitpress.mit.edu/sicp/full-text/book/book-Z-H-20.html...
И это не какой-нибудь второстепенный абзац. Это основной пример, который в книге служит для оправдания концепции объектно-ориентированного программирования. А, как известно, около концепции ООП сломано немало копий, и при этом ни кому этот абзац не резал глаза? Ни у кого не возникло желание переписать функцию random-gcd-test?
http://ru.wikipedia.org/wiki/%D0%9A%D0%B0%D1%80%D1%80%D0%B8%...Я думал, что под карингом подразумевается автоматическая конвертация туда и обратно функции с несколькими аргументами и функции, которая возвращает функцию с меньшим числом аргументов. Типа такого:
Func<int, Func<int, int>> curry = (x => (y => x + y;
curry(45); // 9
Func<int, int, int> curry = x => y => x + y;
автоматическая конвертация туда и обратноэто уже сахар
Ты думаешь, ты решил задачу? Нет, конечно. Всё что ты сделал, это перевелТут опять полная аналогия с задачкой из рассказа Чехова. Некоторые учителя начальных классов делают так. Решают задачку с помощью уравнений и алгебры. Получают: x = (5*138 - 540)/(5 - 3). Потом придумывают словесное описание тому, что стоит в первых скобках и что во вторых. Учителя уже знакомы с алгеброй, а дети из начальных классов еще нет. Конечно, в качестве тренировки мозгов детям очень полезно порешать задачки, еще не зная алгебры. Но остальному человечеству алгебра уже известна, и на практике проще применять ее.решениеготовый ответ с одного языка на другой. Это как переписать ответ математической задачи в других обозначениях, например, записать не арабскими числами, а римскими. Решение задачи на Лиспе не было продемонстрировано. Времени для этого было предостаточно, целых два дня.
Предлагаю тебе решить гораздо более сложную и интересную проблему: подсказывать как надо рефакторить код.Я тут прикинул. В принципе то, что ты хочешь отнюдь не является более сложной задачей. Она решается дальнейшей шлифовкой уже имеющихся инструментов. Как найду время распишу подробнее.
Щас набор твоих колдунств от использования умного грепа не сильно отличается, а будет просто волшебно: жмешь тычку "оптимизируй это" и все само рефакторится.
Будет так. Размечаешь код, как показано красным на рисунке, и жмешь одну тычку. Для второй задачи точно также.

Ты произносишь "алгоритмически неразрешимая задача". На самом деле, еще нет никакой задачи, а ты уже о решении говоришь. В каком виде ты хочешь получить ответ? Твое "кто" это нечто из рантайма, а показать и увидеть нечто из рантайма нельзя, поскольку рантайм имеет протяженность во времени.Что у тебя означает слово "кто" ? Есть точки исходного кода, это тройки Ln, Col, FullFileName. Ответа на твой вопрос в терминах этих троек просто нельзя дать (вырожденные случаи не расстраиваем).ну да, нельзя
это алгоритмически неразрешимая задача
а что тогда делает твоя крутая навигация?
Как только ты сформулируешь свою хотелку в форме задачи, решение тут же вырисовывается. Например, задачу можно сформулировать так. Сделать programm slicing для точки интереса: вызов метода B1.DoSmth, т.е. вырезать ломтик из исходного кода, который соответствует вызову метода B1.DoSmth. Решение такое. Выполняем команду:
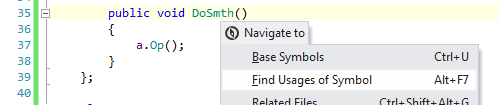
И нас перебрасывает на строчку 11

Это вызов интерфейса. Можно посмотреть, при каких условия в переменной myI1 будет объект типа B1.
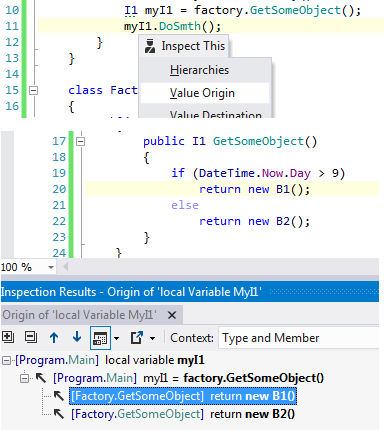
В IntelliJ IDEA еще удобнее сделано, есть кнопка Group by leaf value.
Пишешь, например, RPC, который регистрирует методы аннотациями, а дёргает нужный метод по сигнатуре параметров — и, собственно, всё, беда.
При нормальной реализации RPC делается интерфейс, который доступен и на клиенте и на сервере. Клиент использует интерфейс для вызова методов. На сервере реализация этого интерфейса. ReSharper прозрачно делает навигацию по такой конфигурации. Eclipce и IntelliJ IDEA тоже.
Я, кстати, не знаю, как там в додиезе и студии, но в жаве и idea, например, совершенно никаких гарантий, что ты найдёшь все случаи использования метода.
У тебя есть примеры, где авторефакторинг не сработал? Пример с RPC не подошел.
У тебя есть примеры, где авторефакторинг не сработал? Пример с RPC не подошел.Думаю, имеется ввиду прежде всего reflection и (вероятно, я с ним не работал) invoke dynamics.
Есть некие проблемы с видимостью членов иннеров, но это скорее багло в анализе от intellij.
Ну и плюс многие рефакторинги таки меняют исполнение (да, это противоречит определению, но таких действительно много). Хотя в таких случаях предупреждается, что изменение может повлечь подобные последствия, либо предлагается несколько вариантов поведения.
Ну и в любом случае, примеров такого поведения в статически типизированных языках таки существенно чемьше, чем, например, в утиных
При нормальной реализации RPC делается интерфейс, который доступен и на клиенте и на сервере. Клиент использует интерфейс для вызова методов. На сервере реализация этого интерфейса. ReSharper прозрачно делает навигацию по такой конфигурации. Eclipce и IntelliJ IDEA тоже.Речь идёт о случаях, когда на клиенте дёргается, например, http://server/api/MySuperMethod?... и эти api-методы экспортируются в spring при помощи аннотаций и специального контроллера, а адреса ещё и используются где-то в вёрстке. Клиента в такой ситуации нет. В тестах урлы на эти методы будут строками, и идея такие вещи при рефакторинге ловит исключительно по принципу "умный греп" и за ней надо активно следить, иначе может задеть ещё что-нибудь.
О, кстати, раз уж тут идёт такой лютый фап, у меня вопрос. В ocaml&eliom все внутренние ссылки сайта делают статически типизированными. Поменял адрес или параметры сервиса/метода, он поменялся везде, все ссылки остались валидными, не ломается ничего (ну или не компилируется, говоря, что тиграм недодают параметров). Почему в классных статически типизированных языках C# и яве так не делают? Почему нет статически типизированных шаблонов? Почему всё глючит и сраное говно?
В .NET всё типизировано.
Во-первых, есть http://t4mvc.codeplex.com/
Во-вторых, можно использовать Expression<TDelegate>. Что-то похожее на лисповый квотинг.
Во-первых, есть http://t4mvc.codeplex.com/
Во-вторых, можно использовать Expression<TDelegate>. Что-то похожее на лисповый квотинг.
В третьих, что мешает действовать аналогично через интерфейс+класс, и url-ы генерировать через рантаймовый прокси интерфейса.
t4mvc похоже хоть на что-то, хотя все твои сервисы, очевидно, должны быть слинкованы вместе. Нормальные фреймворки конечно же предоставляют возможность статически типизировать в одну строчку и внешние сервисы, не занимаясь написанием бесконечных прокси-объектов.
тогда в чем проблема?
Да, и рантайм прокси человек не пишет, он в рантайме генерируется.
Да, и рантайм прокси человек не пишет, он в рантайме генерируется.
ты вряд ли успокоишься сделав авторенейм => инструменты рефакторинга помогают, но не оченьПочему ты не успокоишься?
При компиляции в байт код в места вызова в явном виде проставляется id-шник функции. Есть системное API, которое выдает по id-шнику MethodInfo. Сейчас нет маленькой детали, по MethodInfo получить номер строки и столбца в исходном коде. Но это не принципиальная проблема, и в 2014 году ее не будет. Принципиальный алгоритмический вопрос в процессе компиляции решается — нахождение id-шника.
В 2014 году Roslyn будет официально основным компилятором C#. Roslyn позволяет по invocation expression перейти к месту определения того, что вызывается.
Поэтому напрасно твоё беспокойство о том, что можно найти все вызовы метода в компилируемом коде.
Остается некомпилируемый код: название метода фигурирует как строка (рефлекшен) и dynamic.
После появления в C# квотинга Expression<TDelegate>, писать стринги с названием метода нет необходимости (можно и по старому через кодогенерацию).
dynamic-и используются в специальных случаях, границы, которых известны, и известно, когда мы заходим в эти границы. Часто целые проекты реализуются без dynamic.
понятие stream можно вывести, а не придумывать.Вот чувак вещает о том же, что я тут пытался до вас донести:
http://www.infoq.com/presentations/data-types-issues
Рекомендую прослушать весь доклад, про tolling он тоже говорит.
Оставить комментарий
6yrop
Почему только скриптовые динамические языки?