Критика ООП подхода
Опытный программист на фортране может писать на фортране на любом языке. Нет, серьёзно, имхо для абсолютно любой парадигмы можно придумать замечательный пример, показывающий, насколько она ужасна.
То, что с помощью ООП можно выстрелить себе в ногу сотней способов говорит о том (но и только о том что с помощью ООП можно выстрелить себе в ногу сотней способов. Качество кода всегда определяется скиллом программиста.
То, что с помощью ООП можно выстрелить себе в ногу сотней способов говорит о том (но и только о том что с помощью ООП можно выстрелить себе в ногу сотней способов. Качество кода всегда определяется скиллом программиста.
В твоем сообщении можно ООП заменить на NN, и вставить его в любую дискуссию о любом NN, поэтому в нем содержится примерно 0 бит информации
> Опытный программист на фортране может писать на фортране на любом языке.
Тебе пишут о том, что язык может способствовать написанию плохого кода
и не способствовать написанию хорошего. Это же применимо и к семействам
языков, если разница между ними заключается, по большей части, в
поверхностном синтаксисе.
---
"Кто не слеп, тот видит!.."
Тебе пишут о том, что язык может способствовать написанию плохого кода
и не способствовать написанию хорошего. Это же применимо и к семействам
языков, если разница между ними заключается, по большей части, в
поверхностном синтаксисе.
---
"Кто не слеп, тот видит!.."
В твоем сообщении можно ООП заменить на NN, и вставить его в любую дискуссию о любом NN, поэтому в нем содержится примерно 0 бит информацииИменно это я и хотел сказать о твоём посте
Зачастую, если посмотреть на объявления структур данных, то алгоритмы становятся очевидными и тривиальными. Например, часто enterprise приложение состоит из сотен пакетов с тысячами классов, в которых разобраться очень сложно. Но если посмотреть на структуру таблиц в базе данных и на внешние ключи, то все становится понятно.Не совсем точно выражена суть. Всё становится понятным, когда разберешься с mutable состоянием. База данных это частный случай mutable состояния.
ООП подход, как он повсеместно используется, вынуждает создать огромный файл с классом, в котором реализованы все методы, как-то связанные с этим классом.Открой visitor. Или вообще multi-dispatch. Посмотри на CLOS, там все методы объявляются отдельно от структур. И вообще это проблема не синтаксиса, а организации. Ты всегда можешь сделать финт и вспомнить, что всё является объектом, в том числе функции и реализовывать их отдельными объектами. Главная фишка - понять, за какую вершину подвесить условное дерево и с какой стороны разворачивать иерархии. И соответственно не перепутать, когда стоит функции делать отдельными объектами, а когда - нет.
ООП эта функция становится методом классаа в некоторых ООП вообще нет функций - методов. Там объекты только сообщениями обмениваются. И мне кажется должно быть очевидно какие именно предметные области удобно моделировать таким образом.
Obviously it is inefficient to check each Hand for the 2 of clubs. So I add a field, hand, to each Card that is set when the card enters or leaves a player’s Hand.Вообще в ООП есть полно коллекций, которые умеют в прямой и обратный индекс. И лёгкость использования (в отличие от процедурного программирования) позволяет переложить указанную индексацию на готовые коллекции.
> Открой visitor. Или вообще multi-dispatch.
А потом открой презентацию Норвига и узнай, что "визитор" --- не нужен.
> Посмотри на CLOS, там все методы объявляются отдельно от структур.
Это пример работает, вообще-то, против ООП, так как там методом
называется специализированная (в отличие от обобщённой, "generic")
функция.
> И вообще это проблема не синтаксиса, а организации.
"Функциональный" и "объектноориентированный" --- это вопросы
организации, а не синтаксиса.
> Ты всегда можешь сделать финт и вспомнить, что всё является объектом,
> в том числе функции и реализовывать их отдельными объектами.
> Главная фишка - понять, за какую вершину подвесить условное дерево
> и с какой стороны разворачивать иерархии. И соответственно
> не перепутать, когда стоит функции делать отдельными объектами,
> а когда - нет.
Дело в том, что при таком подходе у тебя получается так, что
после реализации функций через объекты ты не можешь сказать точно,
не заглядывая в код, реализует ли твоя "функция" функцию
или является замыканием с изменяющемся внутренним состоянием.
---
"Первое дело разума --- отличать истинное от ложного."
А потом открой презентацию Норвига и узнай, что "визитор" --- не нужен.
> Посмотри на CLOS, там все методы объявляются отдельно от структур.
Это пример работает, вообще-то, против ООП, так как там методом
называется специализированная (в отличие от обобщённой, "generic")
функция.
> И вообще это проблема не синтаксиса, а организации.
"Функциональный" и "объектноориентированный" --- это вопросы
организации, а не синтаксиса.
> Ты всегда можешь сделать финт и вспомнить, что всё является объектом,
> в том числе функции и реализовывать их отдельными объектами.
> Главная фишка - понять, за какую вершину подвесить условное дерево
> и с какой стороны разворачивать иерархии. И соответственно
> не перепутать, когда стоит функции делать отдельными объектами,
> а когда - нет.
Дело в том, что при таком подходе у тебя получается так, что
после реализации функций через объекты ты не можешь сказать точно,
не заглядывая в код, реализует ли твоя "функция" функцию
или является замыканием с изменяющемся внутренним состоянием.
---
"Первое дело разума --- отличать истинное от ложного."
а в некоторых ООП вообще нет функций - методов. Там объекты только сообщениями обмениваются.Строго говоря, большинство современных ООП как раз и работают по принципу передачи сообщений, только неявно.
Сравни:
object.method(args)
send(object, (method, args
Первая запись просто лаконичнее, но они эквивалентны, т.к. метод принадлежит только одному классу.
ООП не дает собрать объявления всех структур данных в одном файле.Щито?
Например, часто enterprise приложение состоит из сотен пакетов с тысячами классов, в которых разобраться очень сложно.Ты хочешь сказать, что переписав все эти файлы на языке без использования ООП, сможешь добиться повышения читаемости?
ООП подход, как он повсеместно используется, вынуждает создать огромный файл с классом, в котором реализованы все методы, как-то связанные с этим классом.
Выше ты пожаловался на то, что "ООП не дает собрать объявления всех структур данных в одном файле", а теперь хочешь, чтобы методы, связанные с работой одного и того же функционала находились в разных папках!, файлах и разных "единицах линковки".
In Hearts, the person with the 2 of clubs leads first, so I might want to determine in whose hand that card is. Ooh! A “clever” optimization draws near! Obviously it is inefficient to check each Hand for the 2 of clubs. So I add a field, hand, to each Card that is set when the card enters or leaves a player’s Hand.Если вникнуть хотя бы в этот абзац, то станет ясно, что ты наткнулся на весьма глупый пост с критикой ООП подхода. Правда, если прочитать статью, то окажется, что автор вполне адекватный. Проблема в том, что ты вырвал большой кусок из контекста, без которого полностью дескредитируешь автора статьи.
Абсолютно все web и enterprise приложения, в разработке которых я участвовал, страдали от проблем, перечисленных в статье.Если бы победила другая концепция, то ты бы сейчас критиковал и её. Поверь, тормоза, которые ты регулярно приписываешь Java - ничто по сравнению с тормозами неправильно написанного кода на ФЯ. Среднестатистические разработчики сыпали бы O(N^2) как из рога изобилия. Правда LINQ в .NET почти сравняло счёт.

> Среднестатистические разработчики сыпали бы O(N^2) как из рога изобилия.
А сейчас они этого не делают, что ли?
---
"Первое дело разума --- отличать истинное от ложного."
А сейчас они этого не делают, что ли?
---
"Первое дело разума --- отличать истинное от ложного."
Ты хочешь сказать, что переписав все эти файлы на языке без использования ООП, сможешь добиться повышения читаемости?Я хотел сказать, что прочитав только объявления структур данных (а именно скриптов создания таблиц компактно собранных в одном месте, можно понять, что примерно программа делает. Когда объявления структур данных размазаны по тысячам файлов, то непонятно с чего начинать знакомство с программой. Я абсолютно уверен, что в энтерпрайзе эти классы никто не читает без необходимости, все сразу смотрят структуру таблиц.
Открой для себя доксиген и прочие генераторы документов. Они тебе замечательно нарисуют схему ООП программы.
Поверь, тормоза, которые ты регулярно приписываешь Java - ничто по сравнению с тормозами неправильно написанного кода на ФЯ.Про джаву, тормоза и ФЯ я ничего не говорил. Моя точка зрения заключается в том, что классы, замыкания и разные виды полиморфизма избыточны в 99% случаев, когда их применяют в массовом программировании. В тех случаях, когда этого достаточно, должны применяться тупые процедуры. К сожалению (я сам не избежал этой ошибки объекты считаются чем-то хорошим сами по себе - типа если мы насоздаем объектов, то у нас будет ООП-архитектура. Разработка приложения выглядит именно так, как описано в процитированном мной фрагменте - создают классы, начинают лепить методы, результат выходит не очень.
> Открой для себя доксиген и прочие генераторы документов.
> Они тебе замечательно нарисуют схему ООП программы.
Они нарисуют мне то, как изменяется состояние объекта?
Как в нарисованном будет отражено то, что перед операцией А
надо выполнить операцию Б, а не то словишь исключение?
---
"Люди недалёкие обычно осуждают всё, что выходит за пределы их понимания."
> Они тебе замечательно нарисуют схему ООП программы.
Они нарисуют мне то, как изменяется состояние объекта?
Как в нарисованном будет отражено то, что перед операцией А
надо выполнить операцию Б, а не то словишь исключение?
---
"Люди недалёкие обычно осуждают всё, что выходит за пределы их понимания."
А как сможешь вычислить изменения состояния объектов по схеме БД? Я ведь отвечал не тебе, а тому, кто хотел окинуть взглядом структуру приложения, не разбираясь в хитросплетениях кода, реализующего её.
Надо быть совсем упоротым, чтобы хреначить классы и полиморфизм от нечего делать. Если ты делаешь некий интерфейс с полиморфными методами, значит ты знаешь, что будет минимум две реализации, присутствующие одновременно, с которыми нужно будет работать единообразным методом.
Хотя если начать мерить продуктивность программиста по количеству написанных классов в день, то презабавнейшие химеры начнут появляться.
Хотя если начать мерить продуктивность программиста по количеству написанных классов в день, то презабавнейшие химеры начнут появляться.
> А как сможешь вычислить изменения состояния объектов по схеме БД?
По схеме базы данных не могу, а вот по сигнатурам функций это возможно
намного чаще, чем по сигнатурам процедур в рамках ООП.
---
"Narrowness of experience leads to narrowness of imagination."
По схеме базы данных не могу, а вот по сигнатурам функций это возможно
намного чаще, чем по сигнатурам процедур в рамках ООП.
---
"Narrowness of experience leads to narrowness of imagination."
Не берусь говорить за остальных, но могу выложить свои впечатления от чистой функциональщины. Программирование на хаскеле - очень приятное академическое упражнение. Но как только дело касается по-настоящему сложной и запутанной программы, писать на нём становится мучением. Я пробовал пару раз и бросил. И мне кажется что, сигнатуры функций в ФП кажутся более выразительными, чем сигнатуры методов в ООП, что на ФП обычно пишут более простые и очевидные приложения.
Я ни вижу никакого прироста информативности у объявления функции в хаскеле по сравнению с объявлением метода в интерфейсе какой-нибудь скалы. Единственное что приходит в голову - явное указание на монаду состояния в хаскеле, но для скалы уже есть давно плагин, которые позволяет помечать методы класса, меняющие состояния.
И вообще, понять как работает программа в деталях, не прочитав всего кода можно лишь относительно и с некоторой вероятностью успеха. И успех понимания зависит не от ООП или ФП, а от стиля программирования и степени знакомства читателя с ним.
Я ни вижу никакого прироста информативности у объявления функции в хаскеле по сравнению с объявлением метода в интерфейсе какой-нибудь скалы. Единственное что приходит в голову - явное указание на монаду состояния в хаскеле, но для скалы уже есть давно плагин, которые позволяет помечать методы класса, меняющие состояния.
И вообще, понять как работает программа в деталях, не прочитав всего кода можно лишь относительно и с некоторой вероятностью успеха. И успех понимания зависит не от ООП или ФП, а от стиля программирования и степени знакомства читателя с ним.
Надо быть совсем упоротым, чтобы хреначить классы и полиморфизм от нечего делать.На яве, например, нельзя написать ни строчки, не создав класс.
Хотя, конечно, проблема не специфическая для явы. Рассмотрим, например, питоновский веб-фреймворк:
class Config(dict):
"""Works exactly like a dict but provides ways to fill it from files
or special dictionaries.
Зачем надо было делать какой-то класс, если достаточно было просто процедур, которые считывали бы данные из файла и возвращали простой dict? Более того, там есть класс ConfigAttribute, который, по-видимому, является просто оберткой над строкой - ключом в конфиге, но как это работает, уже невозможно понять без знания питона.
На яве, например, нельзя написать ни строчки, не создав класс.Это вопрос boilerplate. Смотри на скалу как вариант явы на стероидах. В яве класс со статикой используется вместо модуля в процедурных языках программирования. И импорт умеет импортировать в текущую область видимости статические методы из класса. Так что считай, что чуток бойлерплейта - прописать вместо просто "import" "import static", зато соблюдается концепция "всё есть класс", а использование не отличается от процедурной версии. Разумеется, ты не обязан ограничивать себя статикой и процедурным стилем. Если ты видешь, что задача лучше моделируется через ООП - используй его, ява для этого и создана.
Зачем надо было делать какой-то класс, если достаточно было просто процедур, которые считывали бы данные из файла и возвращали простой dict?Это DSL, реализованный встроенными в питон средствами. сlass там нужен не для реализации, она могла бы быть любой, а для того, чтобы использовать парсер питона для обеспечения псевдонатурального синтаксиса.
Object-oriented programming’s second failing is that it encourages spaghetti code.В принципе, после этого можно было дальше не читать.
Сам пример, на самом деле, вполне валиден и хорошо иллюстрирует происходящее, но надо понимать, что это все аргументация типа "оёёёй, острым ножом ведь можно порезаться, так что давайте выдадим всем палочки с затупленным расширением на концах, и будем кушать ими".
Плюс, pure functional на один шаг дальше отходит от хардваря, что не всегда есть хорошо.
Ну и вообще, в мире идет свободная конкуренция языков, если так можно выразиться. Если появится язык, который будет позволять дешевле создавать софт, то индустрия постепенно перейдет на него естественным путем. Учитывая, что функциональная парадигма существует очень давно, а перехода так тольком и не состоялось, стоит как минимум заподозрить, что что-то тут не так, и подумать, что же это такое.
Это вопрос boilerplate.Это вопрос того, что язык навязывает идиотский способ писать программы.
Это DSL, реализованный встроенными в питон средствами. сlass там нужен не для реализации, она могла бы быть любой, а для того, чтобы использовать парсер питона для обеспечения псевдонатурального синтаксиса.Теперь объясни, зачем нужно это творчество? Мне, например, очевидно, что если для считывания хэшмэпа из файла программисты создают какой-то DSL с псевдонатуральным синтаксисом, то при решении какой-то более сложной проблемы их код будет вообще неумопостигаем.
Так что считай, что чуток бойлерплейта - прописать вместо просто "import" "import static", зато соблюдается концепция "всё есть класс", а использование не отличается от процедурной версии.На практике я не смогу так писать. Мне другие программисты скажут, что я пишу не по ООП, а они по ООП, поэтому их код лучше. Должно быть общепринятым мнение, что простые программы должны быть простыми и написаны минимальными средствами. Вместо этого, например, питонисты (см пример выше) для решения простейших задач пишут необъяснимый код, и потом, наверное, даже гордятся - вот какие мы крутые, применили сразу все возможности питона которые знали!
Мне, например, очевидно, что если для считывания хэшмэпа из файла программисты создают какой-то DSL с псевдонатуральным синтаксисом, то при решении какой-то более сложной проблемы их код будет вообще неумопостигаем.Недо-DSL всегда появляется, когда хочется использовать высокоуровневый полиморфизм. В данном случае, хотелось, чтобы обращение к дереву настроек было таким же, как к дереву обычных данных.
Без полиморфизма едва ли можно обойтись, потому что это единственный способ уменьшить сложность кода.
На практике я не смогу так писать. Мне другие программисты скажут, что я пишу не по ООП, а они по ООП, поэтому их код лучше. Должно быть общепринятым мнение, что простые программы должны быть простыми и написаны минимальными средствами. Вместо этого, например, питонисты (см пример выше) для решения простейших задач пишут необъяснимый код, и потом, наверное, даже гордятся - вот какие мы крутые, применили сразу все возможности питона которые знали!В питоне делай скидку на его интерактивность. Когда работаешь в питоновской консоли, чтобы не повторять много однообразных действий и не плодить кучу глобальных переменных, проще запихнуть все в один объект. В таком виде это мало чем отличается от использования структур, зато сильно облегчает жизнь при интерактивной оладке.
Имхо, спор процедуры vs ООП - на самом деле не о процедурах и объектах, а о другом.
Вообще дискуссия идет о том:
имеет или не имеет право на жизнь подход, когда часть кода используется без досконального понимания как он устроен?
Я делаю такой вывод на основе следующих аргументов обеих сторон.
Процедурщики обычно аппелируют к тому, что ООП код плохой, потому что он имеет множество способов по сокрытию внутренностей своей работы.
ООП-шники обычно аппелирует ровно к обратному, что ООП - хорошая парадигма, потому что имеет множество способов по сокрытию внутренностей своей работы.
Далее процедурщики аппелируют к тому, что все эти способности по сокрытию используются во зло, а ООП-шники аппелируют к тому, что при правильном подходе - сокрытие есть благо.
К первому подходу (любой код перед использованием должен быть досконально изучен) тяготеют те, кто решает задачу на небольшом наборе функциональности выжать максимум эффективности из имеющихся ресурсов. Ко второму подходу (большую часть используемого кода можно не изучать) тяготеют те, кому требуются обеспечить большой набор функциональности без особой оглядки на эффективность.
Имхо, обычно в работе требуются оба подхода, но т.к. правило 20/80 всегда с нами, то 80% кода пишется без особого разбирательства как устроен другой код. Поэтому сокрытие деталей реализации есть благо. Необходимость же в 20% случаев в этих деталях разобраться, или их поменять - должна решаться при помощи инструментов, которые позволяют эти детали реализации вытащить и представить в наглядном виде для визуализации и изменения.
ps
Кто еще что думает? Есть ли согласие, что суть в выделенном тезисе? Есть еще тезисы, которые раскрывают суть конфликта (может быть с другой стороны)?
Вообще дискуссия идет о том:
имеет или не имеет право на жизнь подход, когда часть кода используется без досконального понимания как он устроен?
Я делаю такой вывод на основе следующих аргументов обеих сторон.
Процедурщики обычно аппелируют к тому, что ООП код плохой, потому что он имеет множество способов по сокрытию внутренностей своей работы.
ООП-шники обычно аппелирует ровно к обратному, что ООП - хорошая парадигма, потому что имеет множество способов по сокрытию внутренностей своей работы.
Далее процедурщики аппелируют к тому, что все эти способности по сокрытию используются во зло, а ООП-шники аппелируют к тому, что при правильном подходе - сокрытие есть благо.
К первому подходу (любой код перед использованием должен быть досконально изучен) тяготеют те, кто решает задачу на небольшом наборе функциональности выжать максимум эффективности из имеющихся ресурсов. Ко второму подходу (большую часть используемого кода можно не изучать) тяготеют те, кому требуются обеспечить большой набор функциональности без особой оглядки на эффективность.
Имхо, обычно в работе требуются оба подхода, но т.к. правило 20/80 всегда с нами, то 80% кода пишется без особого разбирательства как устроен другой код. Поэтому сокрытие деталей реализации есть благо. Необходимость же в 20% случаев в этих деталях разобраться, или их поменять - должна решаться при помощи инструментов, которые позволяют эти детали реализации вытащить и представить в наглядном виде для визуализации и изменения.
ps
Кто еще что думает? Есть ли согласие, что суть в выделенном тезисе? Есть еще тезисы, которые раскрывают суть конфликта (может быть с другой стороны)?
psТретий вариант - не вижу вообще большой разницы между тем и тем. В половине случаев использование ООП сводится к написанию
Кто еще что думает? Есть ли согласие, что суть в выделенном тезисе? Есть еще тезисы, которые раскрывают суть конфликта (может быть с другой стороны)?
object.action(arg1, arg2)
для объекта object
вместо
action(object, arg1, arg2)
для структуры object

А сейчас они этого не делают, что ли?Решения за O(N^2) делают, но до рога изобилия всё равно далеко.
От деталей не скрыться не за какими благами, и в реальности это близко к 100%.
Я хотел сказать, что прочитав только объявления структур данных (а именно скриптов создания таблиц компактно собранных в одном месте, можно понять, что примерно программа делает.Щито?
Когда объявления структур данных размазаны по тысячам файлов, то непонятно с чего начинать знакомство с программой.Если они будут собраны в одном файле на несколько миллионов строк, то станет понятно? Хотя да, начинать знакомство надо будет с этого файла.
Я абсолютно уверен, что в энтерпрайзе эти классы никто не читает без необходимости, все сразу смотрят структуру таблиц.Enterprise - это гигантский сегмент разработки программного обеспечения, туда в том числе входят программы, которые не работают с БД. Судя по истории твоего недовольства, ты работал только в так называемых интеграторах - страшном сне любого нормального разработчика.
Правда LINQ в .NET почти сравняло счёт.до сих пор не используешь linq?
Имхо, обычно в работе требуются оба подхода, но т.к. правило 20/80 всегда с нами, то 80% кода пишется без особого разбирательства как устроен другой код. Поэтому сокрытие деталей реализации есть благо. Необходимость же в 20% случаев в этих деталях разобраться, или их поменять - должна решаться при помощи инструментов, которые позволяют эти детали реализации вытащить и представить в наглядном виде для визуализации и изменения.Странное или-или. ООП обеспечивает как сокрытие ненужных деталей, так и минимализацию изменений за счет полиморфизма и проч. Плюс хорошо моделирует предметную область, из-за чего собственно и был придуман.
Плюс хорошо моделирует предметную область, из-за чего собственно и был придуман.Какую область тебе удалось хорошо смоделировать?
Какую область тебе удалось хорошо смоделировать?Хочешь страшный секрет? Любую из тех, что мне встречались.
Хочешь страшный секрет? Любую из тех, что мне встречались.Тогда для тебя не составит труда назвать три из них.
Тогда для тебя не составит труда назвать три из них.e-commerce, интернет-банк, реклама, CRM, онлайн РПГ... хватит?
Процедурщики обычно аппелируют к тому, что ООП код плохой, потому что он имеет множество способов по сокрытию внутренностей своей работы.Не похоже, чтобы процитированный кусок имел отношение к сокрытию, да и к ООП. Если его прочитать, то можно заметить, что автор описывает неправильные структуры данных: создаёт кольцевую ссылку между классами Card и Hand; неправильно использует наследование, где классы Hand и Table только ради кольцевой ссылки наследуют класс Location; неправильно называет классы. Единственное, что относится к ООП - это смешивание разных ответственностей в одном классе, когда автор объединяет отрисовку изображения и игровую логику в классе Card.
Фактически, все эти проблемы можно устроить себе и в процедурном подходе.
интернет-банктам же самая классическая реляционка подходит для базы. Ты поверх реляционной базы еще ООП моделирование навернул? Зачем?
Ты поверх реляционной базы еще ООП моделирование навернул? Зачем?Эээ... чтобы описывать поведение?
Третий вариант - не вижу вообще большой разницы между тем и тем. В половине случаев использование ООП сводится к написаниювопрос полиморфизма действительно не отличается. Потому что полиморфизм и система типов не является исключительной особенностью ООП. Их можно сделать и без него. А вот что самое важное в ООП - это инкапсуляция.
Во-первых, она позволяет хранить данные и алгоритмы близко друг от друга. И когда ты меняешь формат данных, тебе легко найти все алгоритмы, которые надо в связи с этим скорректировать. Во-вторых, ООП позволяет отделить публичные методы от приватных. Всё опасное, что может порушить структуру данных, ты огораживаешь значком private и можешь быть спокоен, что до него пользователь не доберётся.
Возможность сокрытия реализации - это однозначное благо. Поскольку это возможность, а не обязанность. И она очень пригождается, когда разработку ведут не связанные между собой команды. Например разработчики фреймворка и разработчики конкретного пользовательского приложения.
тебе легко найти все алгоритмы, которые надо в связи с этим скорректироватьа find usages и refactoring не подходят?
Эээ... чтобы описывать поведение?можешь привести пример?
можешь привести пример?Ты издеваешься что-ли? Вот пример:
игрок.отдохнуть(int минуты);
игрок.нанестиУдар(Игрок противник);
мы про интернет банкинг. Приведи пример, показывающий как тебе помогло ООП моделирование.
Например, я не вижу там места для применения ООП моделирования. Я вижу, что надо писать просто веб приложение.
Начнем с того, какие понятия из предметной области ты использовал при ООП моделировании? Затем будет второй вопрос, где они живут в серверном коде или в клиентском js-коде?
Например, я не вижу там места для применения ООП моделирования. Я вижу, что надо писать просто веб приложение.
Начнем с того, какие понятия из предметной области ты использовал при ООП моделировании? Затем будет второй вопрос, где они живут в серверном коде или в клиентском js-коде?
Например, я не вижу там места для применения ООП моделирования. Я вижу, что надо писать просто веб приложение.Да, это "просто веб-приложение" - там есть объекты Клиент, Счет, Карта и т.п. Практически каждое понятие предметной области имеет свой класс. Это что, бином Ньютона или какая-то новость для тебя?
Конкретно в интернет-банке есть также объекты Форма, Кнопка, Виджет и прочее.
> Решения за O(N^2) делают, но до рога изобилия всё равно далеко.
Правда, что ли?
Расскажи, как у тебя получается так, что при ФП получаются
полиномиальные алгоритмы, а при ООП с такими же циклами --- нет.
---
"Математик может говорить, что ему хочется,
но физик должен, хотя бы в какой-то мере, быть в здравом рассудке."
Правда, что ли?
Расскажи, как у тебя получается так, что при ФП получаются
полиномиальные алгоритмы, а при ООП с такими же циклами --- нет.
---
"Математик может говорить, что ему хочется,
но физик должен, хотя бы в какой-то мере, быть в здравом рассудке."
Правда, что ли?Правда.
Расскажи, как у тебя получается так, что при ФП получаютсяПросто посмотри на весьма популярную реализацию "quick sort" в ФЯ.
полиномиальные алгоритмы, а при ООП с такими же циклами --- нет.
> Просто посмотри на весьма популярную реализацию "quick sort" в ФЯ.
Если поверх массивов, то делают такую же "быструю," если поверх
списков или хотят стабильную сортировку, делают слиянием.
Где там полиномиальная асимптотика-то?
---
"Математик может говорить, что ему хочется,
но физик должен, хотя бы в какой-то мере, быть в здравом рассудке."
Если поверх массивов, то делают такую же "быструю," если поверх
списков или хотят стабильную сортировку, делают слиянием.
Где там полиномиальная асимптотика-то?
---
"Математик может говорить, что ему хочется,
но физик должен, хотя бы в какой-то мере, быть в здравом рассудке."
Давно уже спрашиваю у апологетов ФП и никак не получаю ответа. Как за O(n) построить суффиксное дерево?
Если поверх массивов, то делают такую же "быструю," если поверхТы просто не понял смысла моего поста, когда возбудился на критику ФЯ, кстати, вполне заслуженную. Попробуй перечитать, о чём и как я говорил.
списков или хотят стабильную сортировку, делают слиянием.
> Ты просто не понял смысла моего поста, когда возбудился
> на критику ФЯ, кстати, вполне заслуженную. Попробуй перечитать,
> о чём и как я говорил.
Ты написал о том, будто на ФЯП можно написать неправильный код,
дающий полиномиальные алгоритмы. Причём ты сформулировал это так,
будто на яве это будет эффективнее при тех же вложениях.
Ещё раз повторю вопрос: что тебе даёт основания так считать,
если JCF, как пример подхода ООП, реализует точно такие же
алгоритмы, если не хуже?
И да, на практике, оопэшники сыпят O(n^2) не реже, чем функциональщики.
Последние, как правило, лучше понимают, что линейные списки ---
это на время прототипа.
---
"Люди недалёкие обычно осуждают всё, что выходит за пределы их понимания."
> на критику ФЯ, кстати, вполне заслуженную. Попробуй перечитать,
> о чём и как я говорил.
Ты написал о том, будто на ФЯП можно написать неправильный код,
дающий полиномиальные алгоритмы. Причём ты сформулировал это так,
будто на яве это будет эффективнее при тех же вложениях.
Ещё раз повторю вопрос: что тебе даёт основания так считать,
если JCF, как пример подхода ООП, реализует точно такие же
алгоритмы, если не хуже?
И да, на практике, оопэшники сыпят O(n^2) не реже, чем функциональщики.
Последние, как правило, лучше понимают, что линейные списки ---
это на время прототипа.
---
"Люди недалёкие обычно осуждают всё, что выходит за пределы их понимания."
Да, это "просто веб-приложение" - там есть объекты Клиент, Счет, Карта и т.п. Практически каждое понятие предметной области имеет свой класс. Это что, бином Ньютона или какая-то новость для тебя?Там был второй вопрос. Ответь, пожалуйста.
Конкретно в интернет-банке есть также объекты Форма, Кнопка, Виджет и прочее.
Ты написал о том, будто на ФЯП можно написать неправильный код,Я написал, что если бы у ФЯ был шанс набрать в свою аудиторию среднестатистических разработчиков, то сейчас вместо проблем ООП были бы проблемы с алгоритмической сложностью (и со сложностью по памяти). Про Java я вообще не говорил, как про сравнение, просто автор темы часто её ругает.
дающий полиномиальные алгоритмы. Причём ты сформулировал это так,
будто на яве это будет эффективнее при тех же вложениях.
И да, на практике, оопэшники сыпят O(n^2) не реже, чем функциональщики.На практике это, конечно же, не так. Я считаю, что хуже всего с алгоритмической сложностью у тех, кто тянет функциональщину в императивный язык. Но если вести речь только про ФЯ, то достаточно внимательно посмотреть на попсовый пример реализации "quick sort". Ты же понимаешь, про какой пример я говорю?
Там был второй вопрос. Ответь, пожалуйста.А тебе что, не очевиден ответ? Давай уже, выкладывай очередной бред, который ты придумал.
А тебе что, не очевиден ответ?Нет. Потому что в зависимости от степени ООП-шности есть очень разные извращения. Кто-то даже js генерирует по доменной модели.
Давай уже, выкладывай очередной бред, который ты придумал.
В этом плане у меня новостей нет. Лучше ты скажи, нововведения в Java8 это не "тянет функциональщину в императивный язык"?
В этом плане у меня новостей нет.То есть ты допрашиваешь Serg просто так?
То есть ты допрашиваешь Serg просто так?Сейчас приходится разгребать и рефакторить очередной ООП дизайн, после рефакторинга уходит большая часть кода. Вот хочу понять, как у людей голова работает, что они производят такую кучу гговнокода.
P.S. Я не то чтобы сильно рассчитываю на результат, но так почему бы и не потрепаться в форуме.
> На практике это, конечно же, не так.
У нас, очевидно, очень разная практика.
> Я считаю, что хуже всего с алгоритмической сложностью у тех,
> кто тянет функциональщину в императивный язык.
Комбинаторы парсеров с мемоизацией, которые притянули из ФП в ИП
и сейчас очень часто используют вместо традиционных генераторов,
прекрасно режут экспоненциальное время до полиномиального.
Это навскидку из того, что у нас используется похожего.
> Но если вести речь только про ФЯ, то достаточно внимательно
> посмотреть на попсовый пример реализации "quick sort".
> Ты же понимаешь, про какой пример я говорю?
Вообще без понятия. Всё, что я видел, это обычный "quick sort,"
полностью копирующий традиционный, то есть такой же в среднем
и такой же квадратичный в худжем, либо это сортировка слиянием,
так как она и проще, и стабильнее (в обоих смыслах).
---
"Кто не слеп, тот видит!.."
У нас, очевидно, очень разная практика.
> Я считаю, что хуже всего с алгоритмической сложностью у тех,
> кто тянет функциональщину в императивный язык.
Комбинаторы парсеров с мемоизацией, которые притянули из ФП в ИП
и сейчас очень часто используют вместо традиционных генераторов,
прекрасно режут экспоненциальное время до полиномиального.
Это навскидку из того, что у нас используется похожего.
> Но если вести речь только про ФЯ, то достаточно внимательно
> посмотреть на попсовый пример реализации "quick sort".
> Ты же понимаешь, про какой пример я говорю?
Вообще без понятия. Всё, что я видел, это обычный "quick sort,"
полностью копирующий традиционный, то есть такой же в среднем
и такой же квадратичный в худжем, либо это сортировка слиянием,
так как она и проще, и стабильнее (в обоих смыслах).
---
"Кто не слеп, тот видит!.."
Сейчас приходится разгребать и рефакторить очередной ООП дизайн, после рефакторинга уходит большая часть кода. Вот хочу понять, как у людей голова работает, что они производят такую кучу гговнокода.Очень просто - они не понимают, зачем нужно моделирование перед тем, как писать код. Кстати, твой код на форуме тоже когда-то сокращали в 2-3 раза, а если учитывать boilerplate, то в 5-6.
Вообще без понятия.Поэтому и не смог понять смысла моего поста.
Всё, что я видел, это обычный "quick sort,"Традиционный - in place, его скопировать в ФЯ - задача не простая.
полностью копирующий традиционный, то есть такой же в среднем
и такой же квадратичный в худжем
Я написал, что если бы у ФЯ был шанс набрать в свою аудиторию среднестатистических разработчиков, то сейчас вместо проблем ООП были бы проблемы с алгоритмической сложностьюя бы порекомендовал вам (спорящим) сначала утвердить терминологию, ибо наверняка, у каждого в голове свое понимание что такое ФЯ
например, это делается здесь: http://rsdn.ru/forum/decl/5683623.flat
когда вы найдете здесь общий знаменатель, то уже беседа будет более продуктивной
касательно O(N^2) для сортировки: имхо это следствие иммутабельности. как оно коррелирует с ФЯ - это уже вопрос терминологии.
ленивость, чистота и иммутабельность - некоторые аспекты программирования, которые в разной степени насаждаются в разных языках программирования и требуют выворачивания мышления для решения задач, имеют свои плюсы и минусы, в общем, их надо правильно готовить.
>> Вообще без понятия.
> Поэтому и не смог понять смысла моего поста.
Да, я не могу понять ту часть, где ты говоришь о каком-то
выдуманном тобой мирке. Ладно бы ещё про какие-нибудь алгоритмы,
требующие эфемерных структур данных говорил, но ты откуда-то
вытянул хоарову сортировку как пример кода функциональщиков.
Вот это --- мистика загадочных тайн, так как функциональшики её
не любят, а потому, как правило, и не используют.
---
Q5: а нафига A4?
A5: чтоб сосать.
> Поэтому и не смог понять смысла моего поста.
Да, я не могу понять ту часть, где ты говоришь о каком-то
выдуманном тобой мирке. Ладно бы ещё про какие-нибудь алгоритмы,
требующие эфемерных структур данных говорил, но ты откуда-то
вытянул хоарову сортировку как пример кода функциональщиков.
Вот это --- мистика загадочных тайн, так как функциональшики её
не любят, а потому, как правило, и не используют.
---
Q5: а нафига A4?
A5: чтоб сосать.
я бы порекомендовал вам (спорящим) сначала утвердить терминологию, ибо наверняка, у каждого в голове свое понимание что такое ФЯКстати, это излюбленный стиль некоторых писателей в Development - до бесконечности вводить определения, пока смысл темы окончательно не скроется под слоем каши.
> скопировать в ФЯ - задача не простая.
Там есть общий подход, так что "скопировать" можно запросто.
Другой вопрос --- зачем?
---
Q5: а нафига A4?
A5: чтоб сосать.
Там есть общий подход, так что "скопировать" можно запросто.
Другой вопрос --- зачем?
---
Q5: а нафига A4?
A5: чтоб сосать.
Да, я не могу понять ту часть, где ты говоришь о каком-то выдуманном тобой мирке.Я говорю о весьма популярной вещи, которую многие использовали и используют для пропаганды ФЯ. А вот ты как раз живёшь в выдуманном мирке, где плюсы ФЯ даются бесплатно, а начинающих и среднестатистических разработчиков просто не существует.
>> Да, я не могу понять ту часть, где ты говоришь о каком-то
> выдуманном тобой мирке.
> Я говорю о весьма популярной вещи, которую многие использовали
> и используют для пропаганды ФЯ.
Ну так приведи уже её!
> А вот ты как раз живёшь в выдуманном мирке, где плюсы ФЯ
> даются бесплатно, а начинающих и среднестатистических
> разработчиков просто не существует.
В моём мирке хоарову сортировку, которую чаще всего называют
"quicksort," пишут руками только в учебных курсах по алгоритмам
и структурам данных, ориентированных на императивные языки,
то есть её пишут простые и приплюснутые насильники.
Функциональщики же пишут сортировку слиянием, так как быстрее,
стабильнее и проще.
---
Q38: а по каким, собственно, правилам, тут ведутся дискуссии?
формальной логикой ведь и не пахнет...
> выдуманном тобой мирке.
> Я говорю о весьма популярной вещи, которую многие использовали
> и используют для пропаганды ФЯ.
Ну так приведи уже её!
> А вот ты как раз живёшь в выдуманном мирке, где плюсы ФЯ
> даются бесплатно, а начинающих и среднестатистических
> разработчиков просто не существует.
В моём мирке хоарову сортировку, которую чаще всего называют
"quicksort," пишут руками только в учебных курсах по алгоритмам
и структурам данных, ориентированных на императивные языки,
то есть её пишут простые и приплюснутые насильники.
Функциональщики же пишут сортировку слиянием, так как быстрее,
стабильнее и проще.
---
Q38: а по каким, собственно, правилам, тут ведутся дискуссии?
формальной логикой ведь и не пахнет...
От деталей не скрыться не за какими благами, и в реальности это близко к 100%.Ты уже читал исходники windows-а? Или хотя бы .net-а? Может смотрел исходники ms sql?
ps
Вон у челов, которые организовывали .net-конференцию после java-конференции, вообще, сложилось впечатление, что .net-чики - "ленивые скотины", и не хера не знают и не особо хотят знать внутреннее устройство .net-фреймворка (в отличии от java-истов). Выводы из этого можно делать разные, но как факт - забавно.
Это показалось странным, и поэтому мы позвали Стаса Сидристого aka sidristij из Luxoft рассказать какие-то куски о рантайме. Судя по отзывам, получилось довольно хардкорно. В отзывах очень чётко прослеживается два тренда: «доклад скучноват, лучше бы блогпост» и «интересно, но не применимо на практике». Иными словами, закрытость CLR приводит к тому, что народ в дотнет-мире не очень привык лезть в дебри, а больше ориентирован на практические вещи. Это было первое важное наблюдение.http://habrahabr.ru/company/codefreeze/blog/241690/
Наши джавовские приколы с мясом, расчленёнкой и внутренностями C2-компилятора, которые на ура заходят на наших хардкорных Java-конференциях, тут не прокатили. Нужно ли двигаться в этом направлении, и объяснять дотнет-народу, как важно знать внутренности? Или забить и концентрироваться на тулинге? Вопрос открытый.
не вижу вообще большой разницы между тем и тем. В половине случаев использование ООП сводится к написаниючто происходит в другой половине? )
что происходит в другой половине? )Вероятно, объектность используется к месту по назначению
Ты уже читал исходники windows-а?на нее Майкрософт вроде подзабивает уже
Или хотя бы .net-а?
Да, естественно, у меня по умолчанию go to definition ReSharper показывает декомпилированную сборку.
go to definition ReSharper показывает декомпилированную сборку.это скорее стандартные либы, а не сам .net-framework.
Очень просто - они не понимают, зачем нужно моделирование перед тем, как писать код.Ровно наоборот, они моделировали, когда надо было писать код.
это скорее стандартные либы, а не сам .net-framework.это часть .net framework
то есть её пишут простые и приплюснутые насильники.Вот именно, твой мирок настолько маленький, что становится идеальным. В нём нет начинающих и средних разработчиков. А насильники бродят вокруг, внутрь не заглядывают.
Ровно наоборот, они моделировали, когда надо было писать код.Ты ещё скажи, что они о чём-то думали, когда надо было писать код.
> Вот именно, твой мирок настолько маленький, что становится идеальным.
> В нём нет начинающих и средних разработчиков.
Расскажи ещё сказок.
> А насильники бродят вокруг, внутрь не заглядывают.
Ну да, ну да.
Так что там с примером чего-то, что все знают в нашем мире-то?
Он будет когда-нибудь, или это ты сам себе крестик нарисовал?
---
Q38: а по каким, собственно, правилам, тут ведутся дискуссии?
формальной логикой ведь и не пахнет...
> В нём нет начинающих и средних разработчиков.
Расскажи ещё сказок.
> А насильники бродят вокруг, внутрь не заглядывают.
Ну да, ну да.
Так что там с примером чего-то, что все знают в нашем мире-то?
Он будет когда-нибудь, или это ты сам себе крестик нарисовал?
---
Q38: а по каким, собственно, правилам, тут ведутся дискуссии?
формальной логикой ведь и не пахнет...
Ты издеваешься что-ли? Вот пример:А ты сам игры пишешь? Я читал, что сейчас в игровых движках используется не ООП, а Entity component system. Там нет объектов как раз, а есть просто данные и функции. Было бы круто если бы кто-то с опытом геймдева это прокомментировал.
игрок.отдохнуть(int минуты);
игрок.нанестиУдар(Игрок противник);
имеет или не имеет право на жизнь подход, когда часть кода используется без досконального понимания как он устроен?Я не согласен. Этот подход и так повсеместно используется без всякого ООП. Например, я могу не знать какая реализация функции sort используется в стандартной библиотеке моего языка.
...
Кто еще что думает? Есть ли согласие, что суть в выделенном тезисе?
Расскажи ещё сказок.Странно, что ты до сих пор не понимаешь, что среднестатистические разработчики будут больше лажать с алгоритмической сложностью на ФЯ. Учитывая, что ты уже много лет как фанат этого дела, мог бы и поумнеть.
Так что там с примером чего-то, что все знают в нашем мире-то?Я более чем уверен, что ты неоднократно видел эту реализацию "quick sort". И да, ты уже раз десять написал, что можно сделать правильно. Но увы, это вовсе не означает, что обычная масса разработчиков будет делать так, а не иначе.
> Этот подход и так повсеместно используется без всякого ООП.
тогда чем плох ООП, если не сокрытием?
если тем, что члены структуры и методы идут вперемешку, то используй ide или утилиты, которые тебе выведут только лишь члены всех структур одним сплошным plain-текстом.
тогда чем плох ООП, если не сокрытием?
если тем, что члены структуры и методы идут вперемешку, то используй ide или утилиты, которые тебе выведут только лишь члены всех структур одним сплошным plain-текстом.
при ФП получаютсяВ ФП основной способ обхода - рекурсия, в императивщине основной способ обхода - цикл.
полиномиальные алгоритмы, а при ООП с такими же циклами --- нет.
При рекурсии много проще налажать с эффективностью и намного труднее обсчитывается сложность кода.
тогда чем плох ООП?ООП на обобщенных функциях лишен этого недостатка. Насколько я понимаю, обобщенные функции можно кое-как использовать на яве, дотнете и cpp
если тем, что члены структуры и методы идут вперемешку
использование обобщенных методов проблему сводит к предыдущей. Тот код, который не получилось выразить через обобщенные методы в одном случае будет записан через рекурсию, а в другом случае - через цикл.
возможно, я потерял нить вашей дискуссии, но всё же. Что вы привязались к этой сложности? Вы хотите сказать, что если не ООП, то мы остаемся только с тем, что для среднестатистического программиста дает взрывной рост ошибок по сложности? Неверно же.
использование обобщенных методов проблему сводит к предыдущей. Тот код, который не получилось выразить через обобщенные методы в одном случае будет записан через рекурсию, а в другом случае - через цикл.Хмм, обобщенные функции - это другая модель ООП, где методы существуют сами по себе, а не привязаны к классам. Поэтому, во-первых, код существует независимо от объектов (смешивание кода со структурами данных - основное недовольство ТС во-вторых, методы могут выполняться не с одним объектом, к классу которого он привязан, а с любым количеством.
Классическая реализация - CLOS, но идею надергали уже много куда, но к сожалению в основном в кастрированном виде.
Что вы привязались к этой сложности? Вы хотите сказать, что если не ООП, то мы остаемся только с тем, что для среднестатистического программиста дает взрывной рост ошибок по сложности?Если не ООП, то происходит комбинаторный взрыв из-за отсутствия полиморфизма. Использование же полиморфизма, что в ФП, что на процедурах взрывает мозг сильнее, чем он же в ООП.
Если не ООП, то происходит комбинаторный взрыв из-за отсутствия полиморфизма. Использование же полиморфизма, что в ФП, что на процедурах взрывает мозг сильнее, чем он же в ООП.Кортеж функций это полиморфизм или нет?
Хмм, обобщенные функции - это другая модель ООП, где методы существуют сами по себе, а не привязаны к классам. Поэтому, во-первых, код существует независимо от объектов (смешивание кода со структурами данных - основное недовольство ТС во-вторых, методы могут выполняться не с одним объектом, к классу которого он привязан, а с любым количеством.это какие-то формальные придирки.
Даже если брать чистый ООП, то реализация обобщенной функции в виде метода ничему не мешает. т.к. разницы между map и my_cool_algorithm.map никакой нет. В ООП же нет никакой запрета на то, что метод должен обязательно применяется к this, а не к передаваемым параметрам.
Основная загвоздка-то в ленивости. Которая в иммутабельной ФП легко реализуется и не имеет побочных эффектов, а императивном ООП - ленивость за собой тащит кучу спецэффектов.
Если не ООП, то происходит комбинаторный взрыв из-за отсутствия полиморфизмаНе обязательно. Всегда можно грамотно раскидать код по разным модулям, сделать простенький DSL. Вариантом много, и ооп не панацея.
С другой стороны, когда погромист начинает написание кода с "создаем класс", это не предвещает хорошего кода.
Кортеж функций это полиморфизм или нет?в смысле аля паттерн-матчинг? или что?
Всегда можно грамотно раскидать код по разным модулям, сделать простенький DSL.Полиморфизм при этом использоваться будет или нет?
Если нет, то как это уменьшит сложность?
Если да, то как раскидывание по модулям и dsl поможет создать полиморфизм?
это какие-то формальные придирки.Это не формальные придирки, а принципиально иная модель ООП, более гибкая и сложная. В ней вместо передачи сообщения объектам есть хитрая процедура, называемая комбинацией методов, которая по принадлежности аргументов определенным классам подбирает наиболее специфичный метод.
Даже если брать чистый ООП, то реализация обобщенной функции в виде метода ничему не мешает. т.к. разницы между map и my_cool_algorithm.map никакой нет.
В ООП же нет никакой запрета на то, что метод должен обязательно применяется к this, а не к передаваемым параметрам.Конечно, но раз метод определен для одного класса объектов, значит он принадлежит этому классу, и только ему, даже если он выполняет умножение 2 * 2.
В системе модели обобщенных функций методы принадлежат этим самым обобщенным функциям, а не объектам, а сама обощенная функция - это по сути просто одно название группы методов, которые могут иметь разное количество аргументов и работать с разным количеством классов
Дай, пожалуйста, пример использования обобщенного метода, чтобы можно было перейти к конкретике.
Полиморфизм при этом использоваться будет или нет?Можно использовать, а можно и нет, зависит от конкретной подзадачи.
Если нет, то как это уменьшит сложность?
Если да, то как раскидывание по модулям и dsl поможет создать полиморфизм?если есть нормальный DSL, то уже никакой полиформизм не нужен, ибо осталось только воспользоавться созданными инструментами. Получится ли сделать этот DSL без полиморфизма - опять же зависит от ситуации
Дай, пожалуйста, пример использования обобщенного метода, чтобы можно было перейти к конкретике.На примере CLOS как первой реализации модели.
# инициализируем обообщенную функцию (не обязательно, для галочки т.к. не содержит никакого кода
(defgeneric mult (x y
# определяем метод, что будет делаться, если оба аргумента - числа
(defmethod mult x 'number) (y 'number
(+ x y
(defmethod mult x 'vector) (y 'number
(код умножения вектора на число
(defmethod mult x 'matrix) (y 'vector
(код умножения матрицы на вектор
(defmethod mult x 'number) (y 'matrix
(код умножения числа на матрицу
# и т.д., пока не кончатся интересующие нас варианты
Как видно, метод - это просто некая процедура, выполняемая при соответствии аргументов обобщенной функции конкретным типам или классам
number и vector - это штатные типы данных, а matrix - это пользовательский класс, который может быть определен где угодно в коде, а может не быть определен вовсе без всякого вреда для программы.
Например, один кодер сначала написал методы и определил классы, затем пришел другой кодер и, не глядя в старый код, написал новый метод, который работает с еще одним новым классом, который определит его коллега по его спеке.
То есть, новому кодеру надо всего лишь сделать еще один decflass и один defmethod, при этом старый код можно даже не смотреть, не то что править. И перегружать ничего не надо, т.к. старые классы и методы не затрагиваются.
Давай решение, которое показывает как dsl позволяет избежать комбинаторного взрыва на следующих примерах.
Есть коллекции, и есть две операции (упрощенно): добавить элемент и удалить элемент. Реализаций коллекций множество: списки, вектора, упорядоченные списки, словари, хэш-таблицы, так же множество нюансов этих реализаций (способ размещения в памяти, доступ локальный/удаленный и т.д.)
Как при использований множества этих коллекций не получить комбинаторного взрыва?
Во-первых, чтобы не приходилось изучать как называются операции add/remove для конкретной коллекции
Во-вторых, чтобы принятие решение о виде используемой коллекции было в одном месте, и остальной код от этого не требовалось бы переписывать.
В-третьих, добавление нового вида коллекции не меняет существующий код кроме строки где происходит выбор новой коллекции.
Есть ФС и есть две операции (упрощенно): получить детей и получить данные. Реализаций ФС куча: локальные фс, ftp, архивы, samba, dropbox, google drive, webdav, системы контроля версий и т.д.
Как для кода, который работает с файлами, не получить комбинаторного взрыва? (локальные задачи подобны тем же, что и у предыдущего примера)
Есть коллекции, и есть две операции (упрощенно): добавить элемент и удалить элемент. Реализаций коллекций множество: списки, вектора, упорядоченные списки, словари, хэш-таблицы, так же множество нюансов этих реализаций (способ размещения в памяти, доступ локальный/удаленный и т.д.)
Как при использований множества этих коллекций не получить комбинаторного взрыва?
Во-первых, чтобы не приходилось изучать как называются операции add/remove для конкретной коллекции
Во-вторых, чтобы принятие решение о виде используемой коллекции было в одном месте, и остальной код от этого не требовалось бы переписывать.
В-третьих, добавление нового вида коллекции не меняет существующий код кроме строки где происходит выбор новой коллекции.
Есть ФС и есть две операции (упрощенно): получить детей и получить данные. Реализаций ФС куча: локальные фс, ftp, архивы, samba, dropbox, google drive, webdav, системы контроля версий и т.д.
Как для кода, который работает с файлами, не получить комбинаторного взрыва? (локальные задачи подобны тем же, что и у предыдущего примера)
Есть ФС и есть две операции (упрощенно): получить детей и получить данные. Реализаций ФС куча: локальные фс, ftp, архивы, samba, dropbox, google drive, webdav и т.д.Например, через механизм драйверов.
Как для кода, который работает с файлами, не получить комбинаторного взрыва? (локальные задачи подобны тем, что и у коллекций)
Есть файл get_data.py, в котором делаются сами действия, общие для всех типов ФС.
def do_some_stuff (path, url):
children = get_children(path, url)
data = get_data(path, url)
do_some_stuff(children, data)
и есть несколько файлов типа:
get_data_localfs.py, get_data_ftp.py, get_data_samba.py и т.д.
В каждом из них есть определения двух функций с теми же именами - get_children и get_data.
Подключаем нужный нам модуль, например, get_data_localfs, и функция do_some_stuff получает данные с локальной фс. Потом подключаем модуль get_data_ftp, определения функций перепривязываются к новому коду, и тот же вызов do_some_stuff уже будет грузить с фтп. И т.д.
Потом захотелось добавить опцию dropbox - кладем рядышком файл get_data_dropbox.py и теперь тот же вызов do_some_stuff будет забирать с дропбокса
Можно сделать обвертку вокруг подключения драйверов, например, определить функцию do_some_stuff_1 с доп.аргументом method, и при вызове типа do_some_stuff(path, url, method="dropbox") сделает все автоматически.
Как лучше подгружать драйвер - зависит от языка. Где-то пойдет так, в компилируемых языках придется подгрузить их все с разными префиксами и выбирать через switch-case, если в языке есть макросы, можно на лету "собирать" имя вызываемой функции.
Давай решение, которое показывает как dsl позволяет избежать комбинаторного взрыва на следующих примерах.Ну dsl - это слишком широкое понятие. Если есть макросы наподобие лисповых, то можно собрать вообще другой язык с другим синтаксисом (пример - максима, первопроходческая программа символьной математики, которая исполняется интерпретатором лиспа, но имеет совсем не лисповый синтаксис).
В большинстве случаев dsl - это просто набор утилит, подогнанных под решение конкретной задачи. Сначала написал утилиты, затем просто работаешь с ними. Это та же инкапсуляция, но под другим соусом
это называется мультиметод, а не обобщенный метод: http://ru.wikipedia.org/wiki/%D0%9C%D1%83%D0%BB%D1%8C%D1%82..., http://en.wikipedia.org/wiki/Multiple_dispatch
Основные проблемы мультиметодов:
1. выбор необходимого метода выполняется черным ящиком компилятора и в это нельзя вмешаться.
2. нельзя сделать, чтобы конкретная реализация обрабатывала неконкретный вид элемента (например, "все упорядоченные коллекции" или "все, кроме")
2b. если же можно, то появляется другая проблема. добавление новой реализации легко может сломать весь предыдущих код (из-за того, что компилятор может предпочесть выбрать новую реализацию ранее используемым).
3. переиспользование метода приходится записывать явно в коде. в виде вызова предыдущей реализации
4. есть непонятки где именно искать необходимую реализацию. Проблема усугубляется, если окончательно тип становится известен в runtime
Основные проблемы мультиметодов:
1. выбор необходимого метода выполняется черным ящиком компилятора и в это нельзя вмешаться.
2. нельзя сделать, чтобы конкретная реализация обрабатывала неконкретный вид элемента (например, "все упорядоченные коллекции" или "все, кроме")
2b. если же можно, то появляется другая проблема. добавление новой реализации легко может сломать весь предыдущих код (из-за того, что компилятор может предпочесть выбрать новую реализацию ранее используемым).
3. переиспользование метода приходится записывать явно в коде. в виде вызова предыдущей реализации
4. есть непонятки где именно искать необходимую реализацию. Проблема усугубляется, если окончательно тип становится известен в runtime
Потом подключаем модуль get_data_ftp, определения функций перепривязываются к новому коду, и тот же вызов do_some_stuff уже будет грузить с фтп. И т.д.Что значит перепривязывается? Что происходит если несколько экземпляров do_stuff (через рекурсию или многопоточно) выполняются одновременно для разных фс?
Это та же инкапсуляция, но под другим соусомно речь-то шла о полиморфизме, а не о инкапсуляции. Как dsl может инкапсулировать - понятно, а вот для полиморфизма через dsl хочется конкретный пример.
это называется мультиметод, а не обобщенный метод: http://ru.wikipedia.org/wiki/%D0%9C%D1%83%D0%BB%D1%8C%D1%82..., http://en.wikipedia.org/wiki/Multiple_dispatchВ википедии - может быть, но в самом CLOS они называются Generic Functions (см defgeneric)
Основные проблемы мультиметодов:В CLOS - не черным ящиком, а специальным алгоритмом Method Combination, который допускает ручной доступ с помощью модификаторов :before, :after. К тому же, можно на лету переопределить method combibation на свою реализацию. Тот факт, что методы отдельно, объекты отдельно, процедура выбора метода отдельно, позволяет изменять одно, не затрагивая другое.
1. выбор необходимого метода выполняется черным ящиком компилятора и в это нельзя вмешаться.
2. нельзя сделать, чтобы конкретная реализация обрабатывала неконкретный вид элемента (например, "все упорядоченные коллекции" или "все, кроме")Можно!
достаточно просто не конкретизировать тип переменной в определении метода
(defmethod mult x 'number) y)
И все, кроме - тоже можно: (y (not 'array
И даже так можно! (y (or 'vector 'matrix
2b. если же можно, то появляется другая проблема. добавление новой реализации легко может сломать весь предыдущих код (из-за того, что компилятор может предпочесть выбрать новую реализацию ранее используемым).Не может, для этого есть прямые руки и алгоритм method combination, который выбирает наиболее специфичный метод.
Если ты написал новый метод, который работает с новым классом объектов, то тебе надо определить и сам класс, а раз его не было до этого, значит, и поведение предыдущего кода никак не изменится
3. переиспользование метода приходится записывать явно в коде. в виде вызова предыдущей реализацииЧто ты называешь переиспользованием?
4. есть непонятки где именно искать необходимую реализацию. Проблема усугубляется, если окончательно тип становится понятен в runtimeДык и method combination тогда работает в рантайме, так что нет никакой проблемы
Что значит перепривязывается? Что происходит если несколько экземпляров do_stuff (через рекурсию или многопоточно) выполняются одновременно для разных фс?Тогда лучше воспользоваться ООП
Ты же спросил, как можно заменить ООП модульной архитектурой? Вот пример. Кстати, драйверная архитектура очень распространенная, просто у нее немного другая сфера применения - где не требуется часто переподключать драйверы.
Не может, для этого есть прямые руки и алгоритм method combination, который выбирает наиболее специфичный метод.это противоречит предыдущему твоему тексту.
Если ты написал новый метод, который работает с новым классом объектов, то тебе надо определить и сам класс, а раз его не было до этого, значит, и поведение предыдущего кода никак не изменится
если был сначала метод (defmethod mult x 'number) y)
а позже добавили метод (defmethod mult x 'number) (y 'number
то предыдущий код может испортиться, если mult (number, number) имеет поведение отличное от mult(number, *)
но речь-то шла о полиморфизме, а не о инкапсуляции. Как dsl может инкапсулировать - понятно, а вот для полиморфизма через dsl хочется конкретный пример.Вроде речь шла, как избежать взрывного роста сложности, вот я и привел пример. Я же не утверждаю, что без полиморфизма можно всегда обходиться, а только что есть ситуации, где красивое решение может быть и без него.
это противоречит предыдущему твоему тексту.
если был сначала метод (defmethod mult x 'number) y)
а потом добавили метод (defmethod mult x 'number) (y 'number
то предыдущий код может испортиться, если mult (number, number) имеет поведение отличное от mult(number, *)
для этого есть прямые рукиЕсли есть возможность выстрелить в себе в ногу, не обязательно этим пользоваться.
Эта модель предоставляет возможности, а погромист должен понимать, что и как он делает, и какие будут последствия.
В любом случае, смешно говорить о потенциальных опасностях, которые вытекают из возможности, если другие системы ООП не дают этой возможности вообще
только что есть ситуации, где красивое решение может быть и без него.идет подмена понятий. В твоем примере полиморфизм как раз есть (набор модулей с единым именованием функций - это классический ad hoc полиморфизм и обобщенные функции (multi method) это также подвид полиморфизма.
В твоем примере удалось избежать vtable (механизм реализации полиморфизма специфичный для mainstream-ООП)
другие системы ООП не дают этой возможности вообщепоправочка - не дают на этапе компиляции. В runtime можно сделать что угодно - например, похожим способом как ты описал для драйверов: пробежаться по всем существующим методам, построить multidispatch-таблицу и поставить вызов конкретной реализации.
идет подмена понятий. В твоем примере полиморфизм как раз есть (набор модулей с единым именованием функций - это классический ad hoc полиморфизм и обобщенные функции (multi method) это также подвид полиморфизма.Ну ок, не вопрос
В твоем примере удалось избежать vtable (механизм реализации полиморфизма специфичный для mainstream-ООП)
я вообще не люблю разных красивых названий, типа полиморфизм, инкапсуляция и т.д, поэтому в терминах могу путаться. Мне достаточно понимания, как это работает и как этим пользоваться, а терминологию оставим мейнстрим-разработчикам для собеседований
поправочка - не дают на этапе компиляции. В runtime можно сделать что угодно - например, похожим способом как ты описал для драйверов: пробежаться по всем существующим методам, построить multidispatch-таблицу и поставить вызов конкретной реализации.Можно, но это будет наколеночным поделием, пятой ногой, пришитой к собаке. Вот если бы это была цельная модель, заложенная разработчиками языка, было б другое дело.
ЗЫ. очень жалко, что это так. Печально пользоваться убогим современным мейнстрим-ООП, когда есть такие нереализованные возможности.
Если есть возможность выстрелить в себе в ногу, не обязательно этим пользоваться.Кроме возможности выстрелить себе в ногу, так же всегда хочется возможность явно разделить код на тот, где можно себе в ногу стрелять, и на тот где нельзя.
Кроме возможности выстрелить себе в ногу, так же всегда хочется возможность явно разделить код на тот, где можно себе в ногу стрелять, и на тот где нельзя.Ну звиняйте тогда, выстрелить в ногу можно на любом языке, это вопрос прямоты рук, а не языка.
Вообще, я с трудом представляю искомую ситуацию, когда метод, дописанный чуть позже, может испортить уже написанный код. Но если вообще такое вдруг случилось, у этого погромиста следует немедленно отобрать клавиатуру
Опять же, 90% возможностей модели ООП на обобщенных функиях, которые я привел, отсутствуют либо реализуются через задницу в языках с мейнстрим-ООП, так что помойму вопрос о потенциальных опасностях ставить некорректно
можешь привести пример?
в django классы поверх БД строятся.
при этом класс - таблица, член класса - это поле таблицы.
Профит в том, что можно использовать разные БД для одного кода.
если нужна производительность какого-то запроса, можно rаw запрос сделать, а так есть такие объекты, как queryset
Blog.objects.filter(author__in=authors).annotate(number_of_entries=Count('entry'
В бд вообще не лезть.
Можно менять классы и тут же генерировать ALTER скрипты, чтобы потом они в репозиторий пошли.
и можно делать что-то вроде
manage.py migrate 0074
svn up -r 74
manage.py migrate 0055
svn up -r 55
svn up
manage.py migrate
чтобы вернуться в нужную структуру БД. Конечно, если добавилось поле и заполнилось данными, обратно без потери нельзя будет вернуться, но для этого существуют другие утилиты.
Вообще, я с трудом представляю искомую ситуацию, когда метод, дописанный чуть позже, может испортить уже написанный код.а вот разработчики стандартов языков обычно этим не пренебрегают.
http://stackoverflow.com/questions/4837399/c-rationale-behin...
В движках да, часто, но обычно только в районе игровой механики. Это удобно с точки зрения изолирования различных подсистем, внутри которых вполне себе может быть ООП
а вот разработчики стандартов языков обычно этим не пренебрегают.Разработка компиляторов - это особая ситуация, каких только извратов не встретишь в коде оптимизирующих компиляторов! Причем не всегда эти извраты бывают оправданными.
К тому же, разработка компиляторов - область, куда попадают очень опытные кодеры, которые знают что делают
Мне достаточно понимания, как это работает и как этим пользоваться, а терминологию оставим мейнстрим-разработчикам для собеседованийЭто ты зря. Computer science очень полезна для программиста. Позволяет принимать решения более осмысленно, а не тыкаться наугад.
Это ты зря. Computer science очень полезна для программиста. Позволяет принимать решения более осмысленно, а не тыкаться наугад.Я просто не люблю, когда въезжание в новую тему начинается с введения страшнозвучащих терминов, когда все можно объяснить на пальцах понятным языком. Я познакомился с ООП как раз на примере CLOS, для базового понимания которой нужны только термины класс (который можно на пальцах объяснить как структура и связанный с ней тип) и метод (как просто специфическая функция и этох понятий хватило, чтобы разобраться с ООП. В литературе по CLOS слова, пугавшие меня-новичка - полиморфизм, инкапсуляция, перегрузка, мультиметод не упоминались вообще, и это было круто.
Меня и сейчас отпугивает обилие непонятных терминов при въезжании в новую тему, хотя ни о чем позитивном это и не свидетельствует
В питоне делай скидку на его интерактивность. Когда работаешь в питоновской консоли, чтобы не повторять много однообразных действий и не плодить кучу глобальных переменных, проще запихнуть все в один объект. В таком виде это мало чем отличается от использования структур, зато сильно облегчает жизнь при интерактивной оладке.Так в данном случае глобальная переменная будет одна. Но в общем объяснение похоже на правду, действительно, смотреть в репле через точечку какие есть методы у объекта должно быть удобно.
Не совсем точно выражена суть. Всё становится понятным, когда разберешься с mutable состоянием. База данных это частный случай mutable состояния.Поясни, что ты имеешь в виду? В современных базах данные иммутабельные.
Кортеж функций это полиморфизм или нет?Кортеж функций, если они замкнуты на общем контексте, это объект в чистом виде.
сли его прочитать, то можно заметить, что автор описывает неправильные структуры данных: создаёт кольцевую ссылку между классами Card и Hand;Если структуры Card и Hand объявлены рядом в одном файле, то заметить проблему становится проще, чем когда у нас есть отдельные большие файлы Card и Hand с кучей методов.
неправильно использует наследование, где классы Hand и Table только ради кольцевой ссылки наследуют класс LocationЕсли бы он знал, что наследование вредно, то вообще не стал бы его использовать и вместо этого подумал бы, как реорганизовать программу.
Единственное, что относится к ООП - это смешивание разных ответственностей в одном классе, когда автор объединяет отрисовку изображения и игровую логику в классе Card.А в процедурном подходе такой проблемы вообще не возникает. Разные процедуры никак не связаны, не надо думать можно ли их в одном классе смешивать или нельзя.
> В ФП основной способ обхода - рекурсия, в императивщине
> основной способ обхода - цикл.
> При рекурсии много проще налажать с эффективностью
> и намного труднее обсчитывается сложность кода.
Это всего лишь твои фантазии, в неленивом языке это один чёрт.
---
"Люди недалёкие обычно осуждают всё, что выходит за пределы их понимания."
> основной способ обхода - цикл.
> При рекурсии много проще налажать с эффективностью
> и намного труднее обсчитывается сложность кода.
Это всего лишь твои фантазии, в неленивом языке это один чёрт.
---
"Люди недалёкие обычно осуждают всё, что выходит за пределы их понимания."
в неленивом языке это один чёрт.есть нюанс. для перевода одного в другое используется алгоритм с ненулевой сложностью, который не всегда может быть выполнен человеком, а уж тем более выполнен без ошибок. Для выполнения кода - такое преобразование в голове, конечно, делать не надо, но вот для оценки сложности - строго необходимо.
Это всего лишь твои фантазии, в неленивом языке это один чёрт.Не верю. Берёшь классический императивный алгоритм в стиле фортрана - и сразу видно, сколько нужно выделять память под массивы. Берёшь функциональщину, читаешь Окасаки, узнаёшь про волшебную амортизированную память и тратишь в разы больше усилий, чтобы их рассчитать.
P.S. Ты так и не сказал как строить суффиксное дерево за O(n) в функциональном стиле.
> есть нюанс. для перевода одного в другое используется алгоритм
> с ненулевой сложностью, который не всегда может быть выполнен
> человеком, а уж тем более выполнен без ошибок. Для выполнения
> кода - такое преобразование в голове, конечно, делать не надо,
> но вот для оценки сложности - строго необходимо.
Ты здесь о чём? Обычно человек переводит алгоритм с языка на язык
не тем методом, что компилятор, поэтому сложные для него приёмы
не используются.
Основная теорема, которую используют для оценки сложности алгоритмов,
сформулирована в терминах шага рекурсии, вообще-то.
---
"Унивеpситет pазвивает все способности, в том числе --- глупость."
> с ненулевой сложностью, который не всегда может быть выполнен
> человеком, а уж тем более выполнен без ошибок. Для выполнения
> кода - такое преобразование в голове, конечно, делать не надо,
> но вот для оценки сложности - строго необходимо.
Ты здесь о чём? Обычно человек переводит алгоритм с языка на язык
не тем методом, что компилятор, поэтому сложные для него приёмы
не используются.
Основная теорема, которую используют для оценки сложности алгоритмов,
сформулирована в терминах шага рекурсии, вообще-то.
---
"Унивеpситет pазвивает все способности, в том числе --- глупость."
> читаешь Окасаки
Окасаки это очень жёсткая функциональщина, совсем не та,
про которую говорят местные знатоки ФП.
Да, я знаю, что если брать Окасаки, то жизнь становится суровой.
Радикальный подход радикален, а ты не знал этого?
Ты можешь ощутить его прелести и в императивном языке,
если станешь писать код с аналогичными допущениями.
---
"Narrowness of experience leads to narrowness of imagination."
Окасаки это очень жёсткая функциональщина, совсем не та,
про которую говорят местные знатоки ФП.
Да, я знаю, что если брать Окасаки, то жизнь становится суровой.
Радикальный подход радикален, а ты не знал этого?
Ты можешь ощутить его прелести и в императивном языке,
если станешь писать код с аналогичными допущениями.
---
"Narrowness of experience leads to narrowness of imagination."
поэтому сложные для него приёмы не используются.я о том же.
При использовании циклов - подсчет вычислительной сложности кода фактически сводится к подсчету вложенных циклов, а при использовании рекурсии - подсчет сложности становится нетривиальным расчетом (и значит на практике такие оценки будут делаться много реже)
Основная теорема, которую используют для оценки сложности алгоритмов,Какое отношение теоремы имеют к среднему программисту?
сформулирована в терминах шага рекурсии, вообще-то.
> При использовании циклов - подсчет вычислительной сложности
> кода фактически сводится к подсчету вложенных циклов
Гон.
---
"Юношеству занятий масса.
Грамматикам учим дурней и дур мы."
> кода фактически сводится к подсчету вложенных циклов
Гон.
---
"Юношеству занятий масса.
Грамматикам учим дурней и дур мы."
Ты можешь ощутить его прелести и в императивном языке,Эти прелести будут намного удобнее для кодинга. Императивный стиль, даже радикальный вполне нормально кодится.
если станешь писать код с аналогичными допущениями.
А вот что такое нечистый функциональный стиль я что-то не догоняю. Функциональный стиль бывает только чистым. Иначе это императивное программирование.
> А вот что такое нечистый функциональный стиль я что-то не догоняю.
> Функциональный стиль бывает только чистым.
> Иначе это императивное программирование.
А если у тебя есть поддержка линейных типов?
---
"Narrowness of experience leads to narrowness of imagination."
> Функциональный стиль бывает только чистым.
> Иначе это императивное программирование.
А если у тебя есть поддержка линейных типов?
---
"Narrowness of experience leads to narrowness of imagination."
Просто посмотри на весьма популярную реализацию "quick sort" в ФЯ.Скажи, пожалуйста, что такое "популярная реализация «quick sort» в ФЯ".
Просто чтобы be on equal terms.
Поясни, что ты имеешь в виду?я имею ввиду sql-ные операции insert/update/delete.
В современных базах данные иммутабельные.
А ты современными базами называешь что-то из NoSQL+CQRS?
Кортеж функций, если они замкнуты на общем контексте, это объект в чистом виде.Вот и я о том же. Зачем так много разговора о полиморфизме, если это частный случай функций?
в django классы поверх БД строятся.
я по возрасту уже неоднократно видел и работал с этим. С базой напрямую гораздо прозрачнее работать.
В бд вообще не лезть.
Мой опыт говорит ровно противоположное. Проект — это база, а код приложения второстепенен. Тем не менее, чистые базданщики очень часто делают ужасные базы.
ты гонишь. Полиморфизм - это свойство, а функции - основной элемент языка. Одно не может быть частным случаем другого.
Полиморфизм - это свойство.свойство чего?
свойство языка, системы типов, либо конкретных функций и объектов.
свойство языка, системы типов, либо конкретных функций и объектов.а зачем мне, как разработчику, этот уровень терминологии? Я поговорил с заказчиком и написал код. Для общения с заказчиком такие термины как "полиморфизм" не подходят, для написания кода они мне тоже не нужны, мне проще сразу функции писать. Для сопровождения, чтения кода и внесения изменений в код тоже проще сразу функции читать. Т.е. для реальной активности разработчика эта терминология просто не требуется.
Т.е. для реальной активности разработчика эта терминология просто не требуется.
Мой опыт говорит ровно противоположное. Проект — это база, а код приложения второстепенен.Ну так ты тогда не программист, а базданщик. Для обслуживания баз понимание языков не нужно
ты не прочитал последнее предложение:
Тем не менее, чистые базданщики очень часто делают ужасные базы.
ты не прочитал последнее предложение:если в твоих проектах база первична, значит это проекты по разработке базы, и ты базданщик
если в твоих проектах база первична, значит это проекты по разработке базы, и ты базданщикречь не о моих проектах, а о тех что описал
Люди, пользующиеся ООП проектированием, напоминают мне Витю Малеева вот в этом эпизоде:
Им нужно нарисовать дерево, орехи, мальчика с девочкой ... наконец случайно нарисовать карманы, и тут их охватывает детский восторг, когда карманы дают им правильный дизайн системы.
А вот продолжение — ООП архитектор перед новобранцами:
... я взял задачник и стал читать задачу:
"Мальчик и девочка рвали в лесу орехи. Они сорвали всего 120 штук. Девочка сорвала в два раза меньше мальчика. Сколько орехов было у мальчика и девочки?"
Прочитал я задачу, и даже смех меня разобрал: "Вот так задача! - думаю. Чего тут не понимать? Ясно, 120 надо поделить на 2, получится 60. Значит, девочка сорвала 60 орехов. Теперь нужно узнать, сколько мальчик: 120 отнять 60, тоже будет 60... Только как же это так? Получается, что они сорвали поровну, а в задаче сказано, что девочка сорвала в два раза меньше орехов. Ага! - думаю. - Значит, 60 надо поделить на 2, получится 30. Значит, мальчик сорвал 60, а девочка 30 орехов". Посмотрел в ответ, а там: мальчик 80, а девочка 40.
- Позвольте! - говорю. - Как же это? У меня получается 30 и 60, а тут 40 и 80.
Стал проверять - всего сорвали 120 орехов. Если мальчик сорвал 60, а девочка 30, то всего получается 90. Значит, неправильно! Снова стал делать задачу. Опять у меня получается 30 и 60! Откуда же в ответе берутся 40 и 80? Прямо заколдованный круг получается!
Вот тут-то я и задумался. Читал задачу раз десять подряд и никак не мог найти, в чем здесь загвоздка.
"Ну, - думаю, - это третьеклассникам задают такие задачи, что и четвероклассник не может решить! Как же они учатся, бедные?"
Стал я думать над этой задачей. Стыдно мне было не решить ее. Вот, скажет Лика, в четвертом классе, а для третьего класса задачу не смог решить! Стал я думать еще усиленнее. Ничего не выходит. Прямо затмение на меня нашло! Сижу и не знаю, что делать. В задаче говорится, что всего орехов было 120, и вот надо разделить их так, чтоб у одного было в два раза больше, чем у другого. Если б тут были какие-нибудь другие цифры, то еще можно было бы что-нибудь придумать, а тут сколько ни дели 120 на 2, сколько ни отнимай 2 от 120, сколько ни умножай 120 на 2, все равно 40 и 80 не получится.
С отчаяния я нарисовал в тетрадке ореховое дерево, а под деревом мальчика и девочку, а на дереве 120 орехов. И вот я рисовал эти орехи, рисовал, а сам все думал и думал. Только мысли мои куда-то не туда шли, куда надо. Сначала я думал, почему мальчик нарвал вдвое больше, а потом догадался, что мальчик, наверно, на дерево влез, а девочка снизу рвала, вот у нее и получилось меньше. Потом я стал рвать орехи, то есть просто стирал их резинкой с дерева и отдавал мальчику и девочке, то есть пририсовывал орехи у них над головой. Потом я стал думать, что они складывали орехи в карманы. Мальчик был в курточке, я нарисовал ему по бокам два кармана, а девочка была в передничке. Я на этом передничке нарисовал один карман. Тогда я стал думать, что, может быть, девочка нарвала орехов меньше потому, что у нее был только один карман. И вот я сидел и смотрел на них: у мальчика два кармана, у девочки один карман, и у меня в голове стали появляться какие-то проблески. Я стер орехи у них над головами и нарисовал им карманы, оттопыренные, будто в них лежали орехи. Все 120 орехов теперь лежали у них в трех карманах: в двух карманах у мальчика и в одном кармане у девочки, а всего, значит, в трех. И вдруг у меня в голове, будто молния, блеснула мысль: "Все 120 орехов надо делить на три части! Девочка возьмет себе одну часть, а две части останутся мальчику, вот и будет у него вдвое больше!" Я быстро поделил 120 на 3, получилось 40. Значит, одна часть 40. Это у девочки было 40 орехов, а у мальчика две части. Значит, 40 помножить на 2, будет 80! Точно как в ответе. Я чуть не подпрыгнул от радости и скорей побежал к Ване Пахомову, чтоб рассказать ему, как я сам додумался решить задачу.
http://deti-online.com/skazki/rasskazy-nosova/vitya-maleev-v...
Им нужно нарисовать дерево, орехи, мальчика с девочкой ... наконец случайно нарисовать карманы, и тут их охватывает детский восторг, когда карманы дают им правильный дизайн системы.
А вот продолжение — ООП архитектор перед новобранцами:
Скоро вернулась Лика, я сейчас же принялся объяснять ей задачу. Нарисовал дерево с орехами, и мальчика с двумя карманами, и девочку с одним карманом.
- Вот, - говорит Лика, - как ты хорошо объясняешь! Я сама ни за что не догадалась бы!
- Ну, это пустяковая задача. Когда тебе надо, ты мне говори, я тебе все объясню в два счета.
И вот я как-то совсем неожиданно из одного человека превратился в совсем другого. Раньше мне самому помогали, а теперь я сам мог других учить. И главное, у меня ведь по арифметике была двойка!
Для сопровождения, чтения кода и внесения изменений в код тоже проще сразу функции читать.вот здесь чую неискренность. Читать код функции, не понимая абстракций, стоящих за ней, придётся гораздо дольше, чтобы осознать, что эта функция делает.
Для обслуживания баз понимание языков не нужноДаже в БД есть свои абстракции. Та же нормализация. Или отличие реляционной БД от иерархической.
Им нужно нарисовать дерево, орехи, мальчика с девочкой ... наконец случайно нарисовать карманы, и тут их охватывает детский восторг, когда карманы дают им правильный дизайн системы.абстракции нужны как раз для того, чтобы избегать избыточно сложных объяснений. Витя Малеев их не понимал, и ему пришлось говнокодить из-за всех сил, вводить лишние сущности, да ещё и три ревизии простейшего проекта сделать, пока из него не перестали вылазить баги.
А если бы он знал абстракцию алгебраических уравнений, он просто бы написал x + y = 120; y = 2 * x; переведя тем самым условие задачи напрямую в абстракции, и получил бы мгновенно верный ответ.
А ты современными базами называешь что-то из NoSQL+CQRS?Нет, любые базы с MVCC - PostgreSQL, Oracle.
А если бы он знал абстракцию алгебраических уравнений, он просто бы написал x + y = 120; y = 2 * x; переведя тем самым условие задачи напрямую в абстракции, и получил бы мгновенно верный ответ.Так вот, есть алгебра исходного кода — формальные правила для преобразований кода. Так же как для алгебраических уравнений есть правила преобразований.
Исходный код (по крайней мере на C#) уже является достаточной абстракцией для хорошего дизайна системы. Каждый раз выдумывать новые абстракции не требуется.
Впечатляющим результатом является тот факт, что понятие потока можно вывести с помощью алгебры исходного кода. В то время как в учебнике sicp понятие потока подается как чистое знание без вывода. , .
MVCCкак это связано с имутабельностью? Данные же меняются.
Данные же меняются.Если бы они менялись, то старые версии были бы затерты и недоступны, а это не так, например
http://www.postgresql.org/docs/9.2/static/functions-admin.ht...
Не говоря о том, что это неявным образом работает для изоляции транзакций.
Если бы они менялись, то старые версии были бы затерты и недоступны, а это не так, напримеру тебя что-то с логикой.
По определению, если запрос SELECT C1 FROM T1 выполнить два раза, и он вернет разные результаты, то это изменяемое состояние.
По определению, если запрос SELECT C1 FROM T1 выполнить два раза, и он вернет разные результаты, то это изменяемое состояние.Потому что в запрос неявно передается аргумент - время. Если ты сам передашь то время, которое тебя интересует, то будешь получать один и тот же результат.
Потому что в запрос неявно передается аргумент - время. Если ты сам передашь то время, которое тебя интересует, то будешь получать один и тот же результат.и что? я написал фактически определение изменяемого состояния. С чем ты еще споришь?
и что? я написал фактически определение изменяемого состояния. С чем ты еще споришь?Содержательно данные неизменямые, на этом построен движок СУБД. На уровне API для удобства вывели функцию, которая подставляет текущий таймстемп.
Каждый раз выдумывать новые абстракции не требуется.Совершенно не обоснованно. Прикладные абстракции в любом случае необходимо ввести. Где их лучше держать: в голове или в коде - это уже отдельный вопрос.
Исходный код (по крайней мере на C#) уже является достаточной абстракцией для хорошего дизайна системы. Каждый раз выдумывать новые абстракции не требуется.Ты попробуй почитать какое-нибудь динамическое программирование, можно и на твоём любимом C#. Вот увидел ты, что создали трёхмерный массив и что-то лопатят в нём непонятное. Не имея представления о концепции динамического программирования, как можно догадаться о сути происходящего?
Но каждый раз придумывать их не надо. Можно использовать готовые.
Я как-то не подумал о программистах от сохи, которые знают только один язык. Вполне возможно, они и не подозревают о базовых абстракциях. Чтобы понять существование разных типов полиморфизма нужно повстречать этот самый полиморфизм в разных языках и произвести обобщение.
Я вот видел как учат людей на курсах 1С, это мрак. У них там нет баз данных, есть библиотеки, и вообще для всех основных абстракций придумана кривая локализация, и везде используется только она. Это как в школе преподавали экономику, не касаясь понятия первой и второй производной. Зато для каждой величины ИмениВеликогоЭкономиста вводилась ещё одна величина ИмениДругогоВеликогоЭкономиста, которая называлась приростом первой и являлась производной. Но поскольку термины математики для экономистов оказались табу, они крайне простые для математика явления объясняли многосложно, путано и долго. За это я возненавидел школьную экономику.
Я как-то не подумал о программистах от сохи, которые знают только один язык. Вполне возможно, они и не подозревают о базовых абстракциях. Чтобы понять существование разных типов полиморфизма нужно повстречать этот самый полиморфизм в разных языках и произвести обобщение.
Я вот видел как учат людей на курсах 1С, это мрак. У них там нет баз данных, есть библиотеки, и вообще для всех основных абстракций придумана кривая локализация, и везде используется только она. Это как в школе преподавали экономику, не касаясь понятия первой и второй производной. Зато для каждой величины ИмениВеликогоЭкономиста вводилась ещё одна величина ИмениДругогоВеликогоЭкономиста, которая называлась приростом первой и являлась производной. Но поскольку термины математики для экономистов оказались табу, они крайне простые для математика явления объясняли многосложно, путано и долго. За это я возненавидел школьную экономику.
> и вообще для всех основных абстракций придумана
> кривая локализация, и везде используется только она.
А это при чём? Какая разница и как это влияет?
Если перевод плохой, то понятия существуют как отвлечённые,
если перевод хороший, это наоборот облегчает понимание.
---
"Каждый имеет право на пользование родные языком..."
> кривая локализация, и везде используется только она.
А это при чём? Какая разница и как это влияет?
Если перевод плохой, то понятия существуют как отвлечённые,
если перевод хороший, это наоборот облегчает понимание.
---
"Каждый имеет право на пользование родные языком..."
Но каждый раз придумывать их не надо. Можно использовать готовые.Прикладные сложно переиспользовать - просто из-за того, что они отличаются от задачи к задачи.
Содержательно данные неизменямые, на этом построен движок СУБД. На уровне API для удобства вывели функцию, которая подставляет текущий таймстемп.Для пользователей такого API данные изменяемые по определению. С чем тут можно спорить?
Ты попробуй почитать какое-нибудь динамическое программирование, можно и на твоём любимом C#. Вот увидел ты, что создали трёхмерный массив и что-то лопатят в нём непонятное. Не имея представления о концепции динамического программирования, как можно догадаться о сути происходящего?Всё в кучу свалил. Причем тут алгоритмика? ООП же это про организационные принципы для написания больших программ. На алгоритмику ООП не претендует.
Совершенно не обоснованно. Прикладные абстракции в любом случае необходимо ввести.Тебе нужно, мне нет.
Кому-то вон карманы нужно нарисовать для решения простейшей задачи. Потом немного абстрагируясь это называют задачи на части. А теми кто уже прошел курс алгебры все эти абстракции забываются как ненужные, поскольку есть простой универсальный метод решения через уравнения.
> Всё в кучу свалил. Причем тут алгоритмика?
> ООП же это про организационные принципы для написания больших программ.
> На алгоритмику ООП не претендует.
ФП закрывает обе потребности.
---
"Дилетантизм --- преступление перед обществом."
> ООП же это про организационные принципы для написания больших программ.
> На алгоритмику ООП не претендует.
ФП закрывает обе потребности.
---
"Дилетантизм --- преступление перед обществом."
Если структуры Card и Hand объявлены рядом в одном файле, то заметить проблему становится проще, чем когда у нас есть отдельные большие файлы Card и Hand с кучей методов.Щито? [wtf off]Если два файла Card и Hand, по 1000 строк в каждом, слить в один файл в 2000 строк, как это облегчит тебе поиск проблем? Или если Card и Hand только объявлены в одном файле, а методы для работы с ними разбросаны по десятку других мест, как это поможет тебе искать проблему в конкретном методе?[/wtf off]
Если бы он знал, что наследование вредно, то вообще не стал бы его использовать и вместо этого подумал бы, как реорганизовать программу.Если бы он хоть что-то знал, то составил бы более грамотную критику ООП подхода. Ошибки, о которых он пишет, слишком сильно бросаются в глаза.
А в процедурном подходе такой проблемы вообще не возникает. Разные процедуры никак не связаны, не надо думать можно ли их в одном классе смешивать или нельзя.Щито? [wtf off]Ты точно так же смешаешь их в одном файле, а состояние класса смешаешь в состояниях структур. Получится то же самое.[/wtf off]
Ты не понимаешь весьма простой вещи: процедурное программирование нельзя противопоставлять ООП. У них проблемы одинаковые, только процедурное программирование ещё и неудобное.
Тебе нужно, мне нет.Ну да, ну да. Ведь у тебя есть твой и ReSharper. Не удивительно, что базданщики потом жалуются на быдлокодеров.
Не удивительно, что базданщики потом жалуются на быдлокодеров.На твой ООП код ругаются базданщики? Неудивительно. ООП-шники очень часто крайне неэффективно работают с базой.
На твой ООП код ругаются базданщики? Неудивительно. ООП-шники очень часто крайне неэффективно работают с базой.На мой код никто не ругается, а вот автор темы явно работает с такими же крутыми умельцами, как ты.
На мой код никто не ругается, а вот автор темы явно работает с такими же крутыми умельцами, как ты.Да, автору всё никак не удается поработать с такими редкими гениями как ты.
мне нет.не совпадает с твоей же лексикой ранее.
Используются абстракции: Эксперимент, Тест, ГСЧ и т.д.
не совпадает с твоей же лексикой ранее.Совпадает. Эти понятия не выдумывались, я просто даю имена элементам кода.
Используются абстракции: Эксперимент, Тест, ГСЧ и т.д.
Эти понятия не выдумывались, я просто даю имена элементам кода.не правда. Если бы это были просто имена, то они бы были A, A1, B. Попробуй как-нибудь с такими именами пописать код, и воочию увидишь, что мозг оперирует именно конкретными абстракциями, а не бессмысленными именами.
Да, автору всё никак не удается поработать с такими редкими гениями как ты.Зато он вдоволь наработался с гениями,
не правда. Если бы это были просто имена, то они бы были A, A1, B. Попробуй как-нибудь с такими именами пописать код, и воочию увидишь, что мозг оперирует именно конкретными абстракциями, а не бессмысленными именами.Вопрос в том, что здесь означает слово "оперирует"?
Кстати, пробовал. Есть ситуации (лень описывать когда это наиболее удобный вариант.
Кстати, пробовал. Есть ситуации (лень описывать когда это наиболее удобный вариант.у меня для тебя плохие новости
выкладывай
Ошибки, о которых он пишет, слишком сильно бросаются в глаза.Мне кажется, ты живешь в каком-то идеальном мире. На практике я вижу что код пишут еще в десять раз хуже, чем в гипотетическом примере автора. Например, есть веб-фреймворк Ruby on Rails. Этот фреймворк добавляет к классу Number много разных методов, например там можно писать 3.days.ago и получить дату, которая была три дня назад.
Это карикатурное ООП головного мозга, которое не запрятано где-то в глубинах интеграторов, а лежит у всех на виду, многие даже восхищаются. На конференциях по джаве учат писать код в стиле AbstractSingletonProxyFactoryBean.
Или если Card и Hand только объявлены в одном файле, а методы для работы с ними разбросаны по десятку других мест, как это поможет тебе искать проблему в конкретном методе?Card - это просто пара (Масть, Ранг то есть просто (Int, Int). Никаких методов у него нет и быть не может, как например не может их быть у числа 5. Если там есть какие-то методы, то что-то глубоко неправильно, как в примере с Ruby on Rails.
Проблема в том, что недостаточно опытный программист (например я в прошлом наслушавшись чуши про какую-нибудь rich domain model, обязательно начнет писать методы. Чтобы высосать из пальца хоть каких-то методов, придется добавлять ссылки на Hand и другие объекты.
В качестве примера приведу orm, включая hibernate (ты может быть с ним встречался). Например есть отделы и сотрудники, у объекта отдел есть список сотрудников, у объекта сотрудник есть список отделов. Когда мы меняем с одной стороны, надо чтобы поменялось с другой. Это ПРОБЛЕМА, над которой бьются джава архитекторы. Но на самом деле, на уровне СУБД такой проблемы нет - просто есть строчка в таблице employee_department, мы ее удаляем и все. С помощью ООП удалось создать проблему на ровном месте.
Щито? [wtf off]Если два файла Card и Hand, по 1000 строк в каждом, слить в один файл в 2000 строк, как это облегчит тебе поиск проблем?Имелась в виду конкретная проблема, на которую ты указал - циклическая зависимость.
Проблема в том, что недостаточно опытный программист (например я в прошлом наслушавшись чуши про какую-нибудь rich domain model, обязательно начнет писать методы.я бы рекомендовал недостаточно опытному программисту помимо махрового ООП вроде явы чуток попрогать на хаскеле и лиспе. Увидеть, что к одной проблеме может быть множество разных подходов, и выбирать следует более подходящие.
я бы рекомендовал недостаточно опытному программисту помимо махрового ООП вроде явы чуток попрогать на хаскеле и лиспе.Моя точка зрения в том, что для простых прикладных задач хаскелли и лиспы дают очень избыточные средства и таким образом могут служить только для запутывания кода.
Как раз на простых задачах они и рулят. В хаскеле ты физически не сможешь прикрепить к таплу Достоинство-Масть никаких методов. А вот в ООП - вполне.
Понятное дело, я не отрицаю полезности экспиренса от голых процедурных языков, вроде паскаля. Просто подразумеваю, что их ещё в школе показали.
Понятное дело, я не отрицаю полезности экспиренса от голых процедурных языков, вроде паскаля. Просто подразумеваю, что их ещё в школе показали.
На практике я вижу что код пишут еще в десять раз хуже, чем в гипотетическом примере автора.Просто у тебя очень ограниченная практика, судя по твоим постам это какой-нибудь epam и всё.
На конференциях по джаве учат писать код в стиле AbstractSingletonProxyFactoryBean.Во-первых, если ты приводишь ссылку на видео, потрудись сообщить минуту и секунду, о которых ты говоришь. Во-вторых, глупо критиковать ООП с помощью Spring, Hibernate или составом Java Enterprise.
Card - это просто пара (Масть, Ранг то есть просто (Int, Int). Никаких методов у него нет и быть не может, как например не может их быть у числа 5. Если там есть какие-то методы, то что-то глубоко неправильно, как в примере с Ruby on Rails.Методы как раз могут быть, или ты для сравнения собрался всегда использовать два == вместо одного? А что на счёт вычисления хэш кода? Делать на месте или всё-таки написать метод? При чём такие же точно методы ты бы написал и в процедурном стиле.
Чтобы высосать из пальца хоть каких-то методов, придется добавлять ссылки на Hand и другие объекты.
Из пальца как раз высосал автор твоей статьи, на самом деле добавлять ссылки на Hand не придётся.
В качестве примера приведу orm, включая hibernate (ты может быть с ним встречался).ООП и ORM - это разные вещи, если хочешь критиковать ORM, то создай новую тему.
То, что описывает совершенно верно, это результат обучения ООП. Учат так – давайте воспроизводить объекты реального мира в программных объектах.
Ты, видимо, уже тоже понял, что это лажа. Но по каким-то причинам ты не отказываешься от термина ООП. Но понимаешь под ООП что-то свое. Причем все, что ты пишешь, имеет форму “так делать нельзя”. Форма “как надо делать” в твоих постах отсутствует. Попытайся придать термину ООП форму “как надо делать”. (Можно ссылки.)
Ты, видимо, уже тоже понял, что это лажа. Но по каким-то причинам ты не отказываешься от термина ООП. Но понимаешь под ООП что-то свое. Причем все, что ты пишешь, имеет форму “так делать нельзя”. Форма “как надо делать” в твоих постах отсутствует. Попытайся придать термину ООП форму “как надо делать”. (Можно ссылки.)
Просто у тебя очень ограниченная практика, судя по твоим постам это какой-нибудь epam и всё.Ты не мог бы предоставить примерный список компаний, практика работы в которых не считается ограниченной?
...
глупо критиковать ООП с помощью Spring
Вот, например, гугл для тебя нормальная компания? А он разрабатывает внутренние фреймворки, эквивалентные спрингу
Из пальца как раз высосал автор твоей статьи, на самом деле добавлять ссылки на Hand не придётся.Если не добавлять ссылки, то никаких методов написать не получится. hashCode - вырожденный случай, да и то нужно только в яве - на C например написание hashCode вручную не требуется.
То, что описывает совершенно верно, это результат обучения ООП.По большей части он описывает проблемы обычного процедурного программирования.
Форма “как надо делать” в твоих постах отсутствует.Надо внимательно читать мои посты.
Попытайся придать термину ООП форму “как надо делать”. (Можно ссылки.)
Какие ссылки? На книжки что ли? Так они гуглятся теми, кого не забанили.
Ты не мог бы предоставить примерный список компаний, практика работы в которых не считается ограниченной?Дело не в конкретных компаниях, тебе просто не с чем сравнивать.
А он разрабатывает внутренние фреймворки, эквивалентные спрингу
Ещё раз повторю: критиковать ООП на примерах конкретных фреймворков нельзя. Ты лучше покажи, где ссылка на минуту и секунду видео, в котором якобы учат плохому? Я уже молчу про то, что если в каком-то видео учат плохому, это вовсе не означает что всё, о чём упоминает это видео является плохим.
Если не добавлять ссылки, то никаких методов написать не получится.Щито? [wtf off] Ты утверждаешь, что без добавления кольцевых ссылок я не смогу написать никаких методов? [/wtf off]
hashCode - вырожденный случай, да и то нужно только в яве - на C например написание hashCode вручную не требуется.Щито? [wtf off] Нет, пожалуй сказать тут нечего... [/wtf off]
Так я и думал. Очередной пост как не надо делать. И ноль информации как надо делать.
Моя гипотеза такая. Под термином ООП нет никакого полезного содержания. Его отстаивают только по психологическим причинам. Иногда интуитивно угадывают удачное решение конкретной задачи. А затем срабатывает стандартная психология отстаивания своего решения. Естественно, иногда угадывают, иногда нет, поэтому общий результат таков, как описано в первом абзаце по ссылке из первого поста.
Моя гипотеза такая. Под термином ООП нет никакого полезного содержания. Его отстаивают только по психологическим причинам. Иногда интуитивно угадывают удачное решение конкретной задачи. А затем срабатывает стандартная психология отстаивания своего решения. Естественно, иногда угадывают, иногда нет, поэтому общий результат таков, как описано в первом абзаце по ссылке из первого поста.
И ноль информации как надо делать.
Ноль информации о том, что надо делать, даёт ноль информации о том, как это надо делать.
Естественно, иногда угадывают, иногда нет, поэтому общий результат таков, как описано в первом абзаце по ссылке из первого поста.Ты сам выше писал о том, что надо кодить, не занимаясь каким-то там моделированием. Поэтому не удивительно, что у тебя получается именно так. Вместо рационального, последовательного и обоснованного подхода - эмоции и необходимость отстаивания своего решения.
It is my belief that what is now called “object-oriented programming” (OOP) i
К содержательному знанию разве применяют такой оборот "now called"? И это не только в этом блоге, могу еще ссылок накидать.
Кто-нибудь скажет про теорему Пифагора или про уравнения Максвела "now called"?
Ты сам выше писал о том, что надо кодить, не занимаясь каким-то там моделированием. Поэтому не удивительно, что у тебя получается именно так. Вместо рационального, последовательного и обоснованного подхода - эмоции и необходимость отстаивания своего решения.Как раз я рассказываю как рационально, последовательно и обосновано работать, не опираясь на случайную интуицию. То, что нет стадии “без кода”, не противоречит указанным свойствам.
Как раз я рассказываю как рационально, последовательно и обосновано работать, не опираясь на случайную интуицию. То, что нет стадии “без кода”, не противоречит указанным свойствам.Ты сразу же кидаешься писать код, не думая об абстракциях и моделировании, и слепо веришь в IDE и ReSharper. Никак не похоже на рациональную, последовательную и обоснованную работу. Зато очень похоже на то, что написано в блоге, с которого и началась вся дискуссия.
Под термином ООП нет никакого полезного содержания.Какую абстракцию ты предлагаешь для оформления больших структур данных?
По факту массово сейчас используются три вида абстракций:
1. реляционка + процедуры
2. дерево структур + процедуры
3. ОО
a. простое ОО
b. ОО с явной передачей this в качестве параметра процедуры в виде handle-а, id-а или урла
c. ОО с массовым вызовом методов. Сервису передается набор this-ов и указание какие методы для них вызвать.
Реляционка+процедуры используется узко: только для стыка между БД и остальным миром.
Дерево+процедуры редкость: из массового вспоминается *nix cli, map/reduce и nosql-бд
ОО используется почти для всех тесных стыков: ОС (win abi, win cli, linux abi UI(html browser api, wpf, win api, QT и т.д. большая часть подгружаемых библиотек, а также для части web-сервисов
Под термином ООП нет никакого полезного содержания. Его отстаивают только по психологическим причинам.ООП имеет уникальные фишки в виде инкапсуляции и наследования. А также реализует один из видов полимформизма, но тут оно не одиноко. Соответственно, если тебе в языке нужны такие выразительные средства - добро пожаловать в ООП.
ООП имеет уникальные фишки в виде инкапсуляции и наследования.Инкапсуляция не связана с ООП, связана с понятием "абстрактный тип данных" - для этого ООП не нужен.
Наследование - таки да.
> Наследование - таки да.
Механизма объявления подтипов недостаточно?
---
"Narrowness of experience leads to narrowness of imagination."
Механизма объявления подтипов недостаточно?
---
"Narrowness of experience leads to narrowness of imagination."
ООП имеет уникальные фишки в виде инкапсуляции и наследования. А также реализует один из видов полимформизма, но тут оно не одиноко. Соответственно, если тебе в языке нужны такие выразительные средства - добро пожаловать в ООП.Попробуй объяснить, что такое наследование без привязки к конкретному языку. Если объяснение будет четкое, ясное и понятное, то можно подумать над тем, нужно оно мне или нет.
> Попробуй объяснить, что такое наследование
> без привязки к конкретному языку.
> Если объяснение будет четкое, ясное и понятное,
> то можно подумать над тем, нужно оно мне или нет.
Чем унаследованные классы фундаментально отличаются от подтипов?
А если рассмотреть более общий подход к полиморфизму операций?
---
"Narrowness of experience leads to narrowness of imagination."
> без привязки к конкретному языку.
> Если объяснение будет четкое, ясное и понятное,
> то можно подумать над тем, нужно оно мне или нет.
Чем унаследованные классы фундаментально отличаются от подтипов?
А если рассмотреть более общий подход к полиморфизму операций?
---
"Narrowness of experience leads to narrowness of imagination."
Механизма объявления подтипов недостаточно?по-моему, это оно и есть
>> Механизма объявления подтипов недостаточно?
> по-моему, это оно и есть
По-моему, не всё так просто.
То есть, вроде бы, где-то там внутри, среди много чего прочего
прячется механизм объявления подтипов. Я думаю, что невыделение
этого механизма как отдельной сущности приносит очень много вреда,
иначе откуда взялись многочисленные горе-архитектуры, в которых
наследование используется, гм, "креативно?"
---
"Narrowness of experience leads to narrowness of imagination."
> по-моему, это оно и есть
По-моему, не всё так просто.
То есть, вроде бы, где-то там внутри, среди много чего прочего
прячется механизм объявления подтипов. Я думаю, что невыделение
этого механизма как отдельной сущности приносит очень много вреда,
иначе откуда взялись многочисленные горе-архитектуры, в которых
наследование используется, гм, "креативно?"
---
"Narrowness of experience leads to narrowness of imagination."
А кто тогда отвечает за такие весёлые плюшки как private, protected, public? Я думал это ООП-онли фича.
> А кто тогда отвечает за такие весёлые плюшки как private,
> protected, public? Я думал это ООП-онли фича.
"Private" и "public" это модульность, а не какая-то "ориентация,"
что подтверждается наличием языков "ООП," где такие понятия отсутствуют.
Только "protected" взаимодействует одновременно с модульностью и
типизацией.
---
"Narrowness of experience leads to narrowness of imagination."
> protected, public? Я думал это ООП-онли фича.
"Private" и "public" это модульность, а не какая-то "ориентация,"
что подтверждается наличием языков "ООП," где такие понятия отсутствуют.
Только "protected" взаимодействует одновременно с модульностью и
типизацией.
---
"Narrowness of experience leads to narrowness of imagination."
а разве это не инкапсуляция?
> а разве это не инкапсуляция?
А что такое "инкапсуляция" и как она реализована в смолтолке?
---
"Narrowness of experience leads to narrowness of imagination."
А что такое "инкапсуляция" и как она реализована в смолтолке?
---
"Narrowness of experience leads to narrowness of imagination."
а разве это не инкапсуляция?Вот я об этом как раз выше говорил, что нафик с умным видом обсуждать толкования умных слов типа инкапсуляция, полиморфизм.
Лучше делитесь примерами хорошего ООП-кода
ЗЫ. свои выложу, как приду домой
Почитай тутhashCode - вырожденный случай, да и то нужно только в яве - на C например написание hashCode вручную не требуется.Щито? [wtf off] Нет, пожалуй сказать тут нечего... [/wtf off]
http://troydhanson.github.io/uthash/userguide.html#_add_ite...
Your key field can have any data type. To uthash, it is just a sequence of bytes. Therefore, even a nested structure can be used as a key.
Таким образом, в C писать hashCode и equals для структуры Card не требуется.
Ещё раз повторю: критиковать ООП на примерах конкретных фреймворков нельзя.На примере ORM нельзя, на примере фреймворков нельзя. На основе чего можно? Как ты определяешь критерий, можно ли критиковать ООП или нет?
На примере ORM нельзя, на примере фреймворков нельзя. На основе чего можно? Как ты определяешь критерий, можно ли критиковать ООП или нет?Все равно что критиковать язык за то, что на нем какой-то быдлокодер что-то наговнокодил
Нужно показывать проблемы, закономерно следующие из недостатков метода, во всех его применениях.
Микроскопом неудобно забивать гвозди, затруднительно раскатывать тесто и почти совсем не возможно закручивать болты с прямым шлицем. Это не делает сам микроскоп бесполезным прибором. Просто применять его нужно по-другому.
Микроскопом неудобно забивать гвозди, затруднительно раскатывать тесто и почти совсем не возможно закручивать болты с прямым шлицем. Это не делает сам микроскоп бесполезным прибором. Просто применять его нужно по-другому.
> Нужно показывать проблемы, закономерно следующие
> из недостатков метода, во всех его применениях.
Затык в "во всех его применениях."
Есть задачи, которые при иных подходах решаются почти одинаково с ООП,
как правило, оопешники приводят их в пример, забывая о более сложных
задачах, где ООП не влезает, если ты не начинаешь симулировать
что-то другое.
Ну, и есть общая проблема: есть, например, канонические оопешные приёмы,
которые вредно влияют на оптимизатор, но оопешники из кожи вон вылезут,
отстаивая их.
---
"Истина грядёт --- её ничто не остановит!"
> из недостатков метода, во всех его применениях.
Затык в "во всех его применениях."
Есть задачи, которые при иных подходах решаются почти одинаково с ООП,
как правило, оопешники приводят их в пример, забывая о более сложных
задачах, где ООП не влезает, если ты не начинаешь симулировать
что-то другое.
Ну, и есть общая проблема: есть, например, канонические оопешные приёмы,
которые вредно влияют на оптимизатор, но оопешники из кожи вон вылезут,
отстаивая их.
---
"Истина грядёт --- её ничто не остановит!"
Затык в "во всех его применениях."Тогда нужно говорить не о недостатках ООП вообще, а в каком-то конкретном случае.
На самом деле, это пустой разговор. Нужно уметь разные подходы, читать хороший код и набраться опыта в разнообразных задачах, тогда вопрос вообще будет неактуален.
Это судя по всему основная проблема топикстартера и отметившегося здесь Шурика.
Почитай тут
http://troydhanson.github.io/uthash/userguide.html#_add_ite...Your key field can have any data type. To uthash, it is just a sequence of bytes. Therefore, even a nested structure can be used as a key.Таким образом, в C писать hashCode и equals для структуры Card не требуется.
ну чел просто написал хеш-функций для С-ых типов данных, коих, благо, немного, и спрятал это все за кучей макросов. точно так же в плюсах ты можешь базовые типы юзать в тех же мапах без явной реализации хешей/операторо стравнения, т.к. они уже написаны (и можешь сам написать темплейтных аналогов этих макросов для сложных структур). Т.ч. непонятно, что ты тут такого чудесного увидел.
Таким образом, в C писать hashCode и equals для структуры Card не требуется.Ты сам прочитал документацию, ссылку на которую мне дал? Даже если ты возьмёшь эту библиотеку, то всё равно придётся писать много boilerplate. Если ты тащишь стороннее решение, то в Java как раз можно обойтись намного меньшими объёмами кода. Генерация какого-то метода - это тоже метод, представь себе.
Есть задачи, которые при иных подходах решаются почти одинаково с ООП,Очередной длинный пост без конкретики.
как правило, оопешники приводят их в пример, забывая о более сложных
задачах, где ООП не влезает, если ты не начинаешь симулировать
что-то другое.
Ну, и есть общая проблема: есть, например, канонические оопешные приёмы,
которые вредно влияют на оптимизатор, но оопешники из кожи вон вылезут,
отстаивая их.
Микроскопом неудобно забивать гвозди, затруднительно раскатывать тесто и почти совсем не возможно закручивать болты с прямым шлицем. Это не делает сам микроскоп бесполезным прибором. Просто применять его нужно по-другому.ты хочешь сказать, что у ООП узкая область применения? Тогда должно быть описания этой узкой области. Для микроскопа такое описание есть.
Нужно показывать проблемы, закономерно следующие из недостатков метода, во всех его применениях.
Это как про голого короля — нужно показывать проблемы, закономерно следующие из недостатков его одежды, во всех ее применениях.
Все, кто выше и ниже, упоролись.
Что-то кисло срач проходит, вброшу немножко.
Вот вам вести из академии, сочинение "почемукоммунизм ООП неизбежен":
http://www.cs.cmu.edu/~aldrich/papers/objects-essay.pdf
Краткий пересказ по-русски тут:
http://thedeemon.livejournal.com/88343.html
Что-то кисло срач проходит, вброшу немножко.
Вот вам вести из академии, сочинение "почему
http://www.cs.cmu.edu/~aldrich/papers/objects-essay.pdf
Краткий пересказ по-русски тут:
http://thedeemon.livejournal.com/88343.html
Статью дома почитаю.
Краткий пересказ по-русски тут:Лично я тут критикую ОО дизайн, а не сами объекты в конкретных языках. Поэтому, имхо, эта заметка может быть интересна только фанатам хаскеля.
http://thedeemon.livejournal.com/88343.html
Странный срач. Вполне можно реализовывать ООД и ООП на процедурном языке типа C. Это всё равно будет ООП, в Linux достаточно примеров таких модулей.
Ты сам прочитал документацию, ссылку на которую мне дал? Даже если ты возьмёшь эту библиотеку, то всё равно придётся писать много boilerplate. Если ты тащишь стороннее решение, то в Java как раз можно обойтись намного меньшими объёмами кода. Генерация какого-то метода - это тоже метод, представь себе.Количество бойлерплейта в С не обсуждалось. Изначально я, развивая мысль автора статьи, заметил, что пока Card - это просто пара интов, никаких методов для класса Card написать невозможно. Чтобы выдумать методы, придется в класс Card добавлять ненужные ссылки на другие объекты, из-за этого возникнут циклические ссылки.
Ты ответил, что требуется написать методы equals и hashCode. Я ответил, что эти методы требуются только в джаве - в C (или, например, в хаскелле) они не нужны.
Это кстати, можно присовокупить к критике ООП подхода. Джава считает, что все должно быть объектом, который скрывает свою реализацию, и поэтому вынужден сам себя хэшировать. Это требует писать бойлерплейт покруче чем в C. В IDE для этого есть даже специальная кнопка - Generate hashCode and equals, которая генерит такой изящный код:
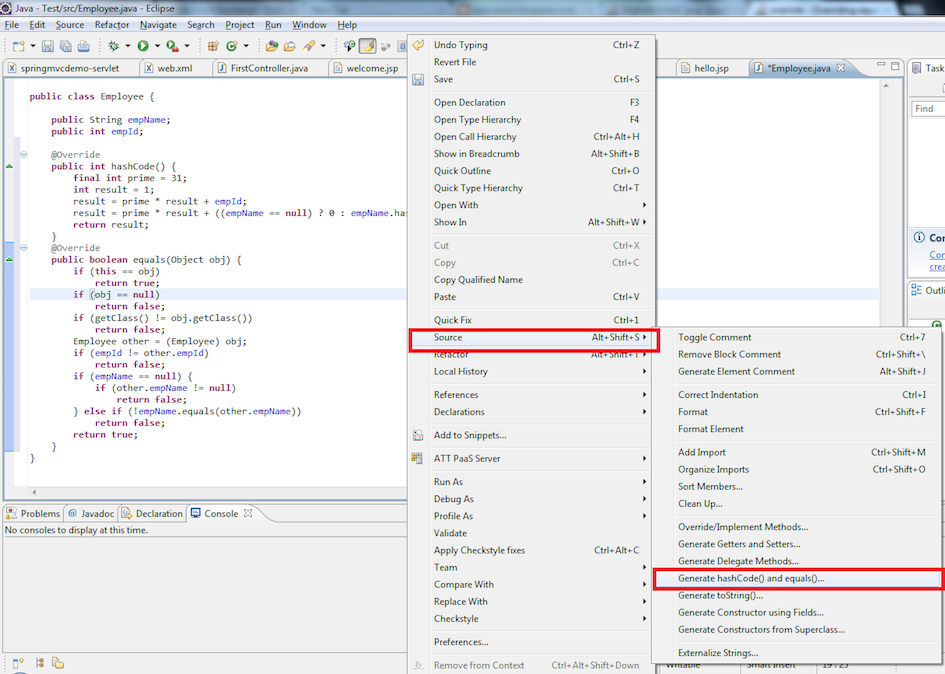
Вполне можно реализовывать ООД и ООП на процедурном языке типа C. Это всё равно будет ООП, в Linux достаточно примеров таких модулей.А при чем тут язык? Там и говорится, что ООП и в линупсе есть. Ибо неизбежно.
Количество бойлерплейта в С не обсуждалось.Ты не понял, что для использования той библиотеки, на которую ты дал ссылку, нужен boilerplate? Так ты сам-то читай содержимое страничек, на которые даёшь ссылки.
Я ответил, что эти методы требуются только в джаве - в C (или, например, в хаскелле) они не нужны.А я на это ответил "Щито?", и был прав.
Теперь возьми свою библиотеку и напиши здесь код, в котором данная структура используется в качестве ключа:
struct some_key
{
int keyNumber;
char* keyString;
};
Теперь возьми свою библиотеку и напиши здесь код, в котором данная структура используется в качестве ключа:Например, так:
struct some_key
{
int keyNumber;
char keyString[32];
};
Конечно, это не работает со строками произвольной длины, но так мы и программируем на портабельном ассемблере.
Вообще, я не вижу смысла сравнивать С и джаву. Моя мысль в том, что в джаве могли бы сделать так, что класс который состоит из примитивных типов и стрингов имеет встроенную нормальную хэшфункцию, и это покрывало бы 99.9 процентов случаев. Вместо этого при проектировании java collections угорели по ООП, результат налицо.
Например, так:Нет, не так, а напиши для конкретной стурктуры, которую я привёл. И с использованием конкретной библиотеки, на которую ты давал ссылку.
Моя мысль в том, что в джаве могли бы сделать так, что класс который состоит из примитивных типов и стрингов имеет встроенную нормальную хэшфункцию, и это покрывало бы 99.9 процентов случаев.добро пожаловать в скалу. Она так умеет. Она вообще много бойлерплейта из джавы выкидывает.
А я на это ответил "Щито?", и был прав.Конечно, ты не был прав. Ты усомнился, что для структуры Card в C не надо самому писать хэш-функцию, я продемонстрировал, что это не так. Ты теперь выдумал другую структуру и стал доказывать, что эта библиотека не справится с хэшированием этой структуры.
http://www.cs.cmu.edu/~aldrich/papers/objects-essay.pdf
Nontrivial abstraction. An interface that provides
at least two essential services.
...
The reason to consider only nontrivial abstractions
is that if an abstraction has only one service,
one can use a function to abstract it. Functions are completely
ideal in such cases—but some abstractions that
at first appear to be simple turn out to be richer than expected
in practice.
А кортеж функций не подходит?
стал доказывать, что эта библиотека не справится с хэшированием этой структуры.это не библиотека, а написанный кем-то набор макросов, которые вызывают написанные автором [макросов] хеш-функции
т.е. вместо того, чтобы написать свой код хеш-функции, ты пишешь код, указывающий, как вызвать чужую хеш-функцию. и никакого волшебного автоматического появления нужных функций не происходит - все равно всё указывает программист
В задаче не было ограничения на длину строки в 32 символа (а уже тем более в 15 символов если вспомнить про utf8). Ты его сам добавил.
А кортеж функций не подходит?если речь про чистые функции, то нет внутреннего состояния, поэтому не подойдет
если же речь про замыкания со внутренним состоянием, то это тот же объект - вид сбоку
если речь про чистые функции, то нет внутреннего состояния, поэтому не подойдетВ статье уже используется слово "функция", например, тут "Functions are completely ideal in such cases". Поэтому за определением термина "функция" обратитесь к статье. К моему вопросу это не имеет отношения.
если же речь про замыкания со внутренним состоянием, то это тот же объект - вид сбокуВ таком случаем понятие объект определяется из пары понятных терминов: функция и кортеж. Это же здорово!

если же речь про замыкания со внутренним состоянием, то это тот же объект - вид сбокунеужели можно было написать целую статью, доказывающую, что без кортежей функций не обойтись. Любому практикующему программисту это же очевидно.
В задаче не было ограничения на длину строки в 32 символа (а уже тем более в 15 символов если вспомнить про utf8). Ты его сам добавил.Я согласен, что с помощью данной библиотеки сделать такой ключ или очень неудобно, или вообще невозможно. Я никогда и не утверждал обратного.
доказывающую, что без кортежей функций не обойтись.под функцией обычно понимается все-таки чистая функция. И соответствено, нет. Одним лишь кортежем функций не обойтись.
Например, так:она не будет работать, если в keyString внезапно появится мусор после '\0'
struct some_key
{
int keyNumber;
char keyString[32];
};
Я согласен, что с помощью данной библиотеки сделать такой ключ или очень неудобно, или вообще невозможно. Я никогда и не утверждал обратного.ты утверждал, что
на C например написание hashCode вручную не требуется.и в качестве доказательства привел данную библиотеку
приведенный выше пример показывает, что написание вручную hashCode все-таки требуется в нетривиальных случаях. а в тривиальных случаях на других языках писать хешкод тоже не нужно - для int и string они есть готовые в большистве языков
> приведенный выше пример показывает, что написание вручную
> hashCode все-таки требуется в нетривиальных случаях.
Если ты определяешь равенство каким-то нетривиальным способом,
то да, а если у тебя равенство определено естественно, то тот
код очень даже работает, если не менять тип с указателя на массив.
---
"Narrowness of experience leads to narrowness of imagination."
> hashCode все-таки требуется в нетривиальных случаях.
Если ты определяешь равенство каким-то нетривиальным способом,
то да, а если у тебя равенство определено естественно, то тот
код очень даже работает, если не менять тип с указателя на массив.
---
"Narrowness of experience leads to narrowness of imagination."
она не будет работать, если в keyString внезапно появится мусор после '\0'
вообще, скорее всего будет - какая там разница, что в этих 10-ти байтах лежит?
В описании библиотеки написано, что она сравнивает структуры побайтово, откуда ей знать, что нужно остановиться после '\0'?
>если у тебя равенство определено естественно
Можешь рассказать, что такое определить равенство естественно?
Можешь рассказать, что такое определить равенство естественно?
>> если у тебя равенство определено естественно
> Можешь рассказать, что такое определить равенство естественно?
Это значит, что две величины равны, если равны в обычном
внутриязыковом смысле: "a = b" или, как в сях, "a == b".
---
"Narrowness of experience leads to narrowness of imagination."
> Можешь рассказать, что такое определить равенство естественно?
Это значит, что две величины равны, если равны в обычном
внутриязыковом смысле: "a = b" или, как в сях, "a == b".
---
"Narrowness of experience leads to narrowness of imagination."
Это значит, что две величины равны, если равны в обычномесли у тебя равенство определено естественно, то в той же java переопределять hashCode опять же не нужно и весь спор не имеет смысла от начала и до конца.
внутриязыковом смысле: "a = b" или, как в сях, "a == b".
ты утверждал, чтоЯ говорил это в контексте класса Card, наверное надо было лучше формулировать. Разумеется, я не имел в виду, что C каким-то волшебным способом хеширует структуру с поинтерами на другие структуры.
В ответ на:
на C например написание hashCode вручную не требуется.
и в качестве доказательства привел данную библиотеку
в тривиальных случаях на других языках писать хешкод тоже не нужно - для int и string они есть готовые в большистве языковДля структуры из двух интов в джаве надо написать самому методы equals и hashCode, а в C не надо.
Для структуры из двух интов в джаве надо написать самому методы equals и hashCode, а в C не надо.Хорошо, давай по-другому. Вот тебе структура:
struct some_key
{
int part_one;
int part_two;
};
Используя свою библиотеку, напиши на Си две простые функции:
void add(hash_t hashtable, struct some_key* key) - добавляет структуру в хэш таблицу
struct some_key* remove(hash_t hashtable, int part_one, int part_two) - удаляет и возвращает структуру из таблицы или NULL
вопрос со звездочкой: нужно ли писать в C хешкод для такой структуры
struct key {
char a;
int b;
}Для структуры из двух интов в джаве надо написать самому методы equals и hashCode, а в C не надо.да таких структур с готовыми хешкодами пруд пруди, бери любую и не пиши, ты же не гнушаешься использовать на C сторонний код?
да таких структур с готовыми хешкодами пруд пруди, бери любую и не пиши, ты же не гнушаешься использовать на C сторонний код?Я тебя не понимаю. Откуда я возьму структуру
struct Card{int rank; int suite}
?
В описании библиотеки написано, что она сравнивает структуры побайтово, откуда ей знать, что нужно остановиться после '\0'?
ну она вполне может побайтово сравнить, игнорируя \0
но вообще вряд ли она так делает, а то конфуз выйти может
ЗЫ и она же не сравнивает, а хеш считает
struct Card{int rank; int suite}
вообще, это спарта! зачем тут вообще структура, когда все данные в int влезут! тогда и хеш не нужен

ЗЫ и она же не сравнивает, а хеш считаетно хэш-то должен совпадать для одинаковых структур. Структуры {10, "A\0z"} и {10, "A\0y"} одинаковы, а хэши у них разные будут.
спасибо, кэп!
я потому и написал, что вряд ли она это делает
я потому и написал, что вряд ли она это делает
она не будет работать, если в keyString внезапно появится мусор после '\0'Я думал об этом, можно занулять память.
под функцией обычно понимается все-таки чистая функция. И соответствено, нет. Одним лишь кортежем функций не обойтись.что мешает понимать под функцией полноценную функцию?
Получаются простые и ясные базовые понятия. Функция с параметрами, локальными переменными и свободными переменными и кортеж. Причем ввести кортеж очень естественно. Функция может принимать несколько параметров, что собственно и является кортежем. Хочется иметь возможность и возвращать из функции несколько значений. Поэтому кортеж очень естественен.
В статье заявлено:
Some of the advantages of object-oriented programming
may be psychological in nature. For example,
Schwill argues that “the object-oriented paradigm...is
consistent with the natural way of human thinking”
[28]. Such explanations may be important, but
they are out of scope in this inquiry; I am instead interested
in whether there might be significant technical
advantages of object-oriented programming
А затем в статье идет всё обсуждение вокруг понятия abstraction. Открываем википедию по слову abstraction:
Abstraction tries to factor out details from a common pattern so that programmers can work close to the level of human thought ...
http://en.wikipedia.org/wiki/Abstraction_%28computer_science...
Вроде было заявлено, что это "out of scope in this inquiry".
Как не изворачивайся, но кроме "psychological in nature" в ООП ничего нет. Т.е. это такой же казус как соционика.
А затем в статье идет всё обсуждение вокруг понятия abstraction. Открываем википедию по слову abstraction:А зачем открывать википедию, когда в статье дают свое определение, и речь именно о нем, а не о том, что в википедии?
в статье дают свое определениегде? скопируй сюда.
я по возрасту уже неоднократно видел и работал с этим. С базой напрямую гораздо прозрачнее работать.
транзисторы по возрасту не паял? А то вот xchg в последнем интеле не очень прозначно сделан.
Ты спросил, где помогает - я ответил.
Ещё из плюшек - автоматом по классу строится адмика, в классе можно указать поля many-to-many и будет создана другая таблица (нового класса можно не делать).
Построить автоматом админку по базе данных,думаю гораздо сложнее, особенно, если база данных заранее неизвестна.
Таким образом сам объект отделён от способа его хранения. У кого-то были движения nosql повесить, но всё-таки там очень много исползьуется join и limit'ов и совсем другой код нужно писать. Работать-то будет, но не очень хорошо.
а вот нужно ли тебе такое отделение.
Если база определена, если куча процедур в самой базе - думаю, что не осбоо.
in the remainder of this essay I
will generally use the term service abstractions, reflecting
Kay’s view of objects as servers that provide services
to their clients. A service abstraction is, on a technical
level, the same form of abstraction as a procedural
data structure, but it may be used to abstract any
set of services, not just data structure manipulations.
Ну и дальше есть определение nontrivial abstraction, из которого если относящееся к nontrivial убрать, остается
An interface that provides .. essential services.
will generally use the term service abstractions, reflecting
Kay’s view of objects as servers that provide services
to their clients. A service abstraction is, on a technical
level, the same form of abstraction as a procedural
data structure, but it may be used to abstract any
set of services, not just data structure manipulations.
Ну и дальше есть определение nontrivial abstraction, из которого если относящееся к nontrivial убрать, остается
An interface that provides .. essential services.
Функция с параметрами, локальными переменными и свободными переменными и кортеж. Причем ввести кортеж очень естественно. Функция может принимать несколько параметров, что собственно и является кортежем.Понятие интерфейса ты как сюда введешь?
A service abstraction is, on a technicalТермин абстракция объясняется через английский глагол "to abstract". Смысл этого глагола берется общепринятый. Поэтому обратиться к википедии было вполне логично.
level, the same form of abstraction as a procedural
data structure, but it may be used to abstract any
set of services, not just data structure manipulations.
Не вижу я, чтобы они вводили какое-то свое хитрое понятие “абстракция”. Апеллируют к обычному общепринятому понятию. Уточняют лишь прилагательным “service”, которое тоже что-то аморфное.
An interface that provides .. essential services.
Это же чистой воды "psychological in nature ... the natural way of human thinking".
Всё это ваше ООП всего лишь разводка лохов под лейблом "the natural way of human thinking".
> Всё это ваше ООП всего лишь разводка лохов под лейблом
> "the natural way of human thinking".
Строго говоря, это, видимо, и правда ближе к естественному
мышлению человека, то есть с "чтением следа," эмпатией и т.д.
Вот только есть вопрос с ограничениями такого мышления и
ошибками, присущими этому способу.
---
"Всё, что можно сделать с крысой, можно сделать и с человеком.
А с крысой мы можем сделать почти всё."
> "the natural way of human thinking".
Строго говоря, это, видимо, и правда ближе к естественному
мышлению человека, то есть с "чтением следа," эмпатией и т.д.
Вот только есть вопрос с ограничениями такого мышления и
ошибками, присущими этому способу.
---
"Всё, что можно сделать с крысой, можно сделать и с человеком.
А с крысой мы можем сделать почти всё."
А ты заметил, что у тебя получилась цепочка OOP - abstraction - human thought, и из последнего ты делаешь выводы о первом, в то время, как абстракции присущи не только ООП, но и всем другим подходам к программированию? В ФП ведь тоже сплошные абстракции, например. Практически везде они, кроме может быть языков Си и Go, где авторы еще не покинули каменный век.
А в целом, конечно, правда - статья, как и большинство про ООП, гуманитарная и ненаучная. Хочешь научное описание ООП - читай Карделли. Только вряд ли понравится.
А в целом, конечно, правда - статья, как и большинство про ООП, гуманитарная и ненаучная. Хочешь научное описание ООП - читай Карделли. Только вряд ли понравится.
> Хочешь научное описание ООП - читай Карделли.
> Только вряд ли понравится.
Не проще ли тогда осилить Худака, Элиота и т.п. и забыть про ООП.
---
Моё знакомство с ООП началось со слова "интифада."
> Только вряд ли понравится.
Не проще ли тогда осилить Худака, Элиота и т.п. и забыть про ООП.
---
Моё знакомство с ООП началось со слова "интифада."
Есть, кстати, трансляторы ФЯ в javascript? И примеры так построенных сайтов?
> Есть, кстати, трансляторы ФЯ в javascript?
По-моему, уже давно были проекты трансляторов с хаскела и схемы.
> И примеры так построенных сайтов?
Под него уже несколько библиотечек ФРП есть, разве нет?
---
Моё знакомство с ООП началось со слова "интифада."
По-моему, уже давно были проекты трансляторов с хаскела и схемы.
> И примеры так построенных сайтов?
Под него уже несколько библиотечек ФРП есть, разве нет?
---
Моё знакомство с ООП началось со слова "интифада."
Есть, кстати, трансляторы ФЯ в javascript? И примеры так построенных сайтов?parenscript от CL, nagare от питона.
Есть, кстати, трансляторы ФЯ в javascript? И примеры так построенных сайтов?Over 9000! GHCJS, js_of_ocaml, Clojure, Idris, Ur/Web, Elm, Roy, Haste, Scala.js...
http://github.com/jashkenas/coffeescript/wiki/list-of-langu...
Среди них есть такие - на которых разработка динамичного сайта будет продуктивнее, чем на самом js?
И самое главное где посмотреть примеры реальных сайтов, которые используют код после этих трансляторов?
И самое главное где посмотреть примеры реальных сайтов, которые используют код после этих трансляторов?
меня смущает, что в этом списке аж 20 трансляторов C# -> Js. Причем, AFAIK, ни один из них не готов для полноценного использования для скриптинга на стороне браузера.
Основные проблемы:
- конвертится только подмножества языка
- нет деклараций под стандартные либы браузера (дом и т.д.)
- нет технической возможности задекларировать часто-используемые js-либы (типа jquery из-за того, что типы таких библиотек много богаче, чем типы в исходном транслируемом языке
Основные проблемы:
- конвертится только подмножества языка
- нет деклараций под стандартные либы браузера (дом и т.д.)
- нет технической возможности задекларировать часто-используемые js-либы (типа jquery из-за того, что типы таких библиотек много богаче, чем типы в исходном транслируемом языке
посмотри на nagare. Мне он показался простым и интуитивным.
http://www.nagare.org/
http://www.nagare.org/trac/wiki/WhoUsesNagare
http://www.nagare.org/
http://www.nagare.org/trac/wiki/WhoUsesNagare
http://www.nagare.org/он же не ФЯ-шный, там питон. Который по концепциям очень похож на js: ООП и без static types.
он же не ФЯ-шный, там питон. Который по концепциям очень похож на js: ООП и без static types.Ну тогда бери parenscript, это js на макросовых стероидах, нормальный ООП и сильная типизация в комплекте, работает стабильно.
он на замыканиях. Это вроде есть ФЯшная концепция.
Tutorial шандарашит без всяких замыканий
http://www.nagare.org/trac/wiki/NagareTutorial2
class Counter(object):
def __init__(self):
self.val = 0
def increase(self):
self.val += 1
def decrease(self):
self.val -= 1
Ну тогда бери parenscript, это js на макросовых стероидах, нормальный ООП и сильная типизация в комплекте, работает стабильно.Я использую TypeScript и он меня более менее устраивает.
Сейчас у меня интерес скорее академический: насколько ФЯ со статической типизацией совместимо с интерактивным UI
> он на замыканиях. Это вроде есть ФЯшная концепция.
Не-а. См. "funarg problem".
---
"Narrowness of experience leads to narrowness of imagination."
Не-а. См. "funarg problem".
---
"Narrowness of experience leads to narrowness of imagination."
Я использую TypeScript и он меня более менее устраивает.Что думаешь о flowtype?
Что думаешь о flowtype?мне в нем нравится type inference, надеюсь что-нибудь такое же прикрутят к TypeScript
мне в нем нравится type inference, надеюсь что-нибудь такое же прикрутят к TypeScriptА ты не думал использовать flowtype как drop in replacement для typescript?
Нет, не думал. Я люблю языки с хорошей поддержкой в IDE.
Вот вам вести из академии, сочинение "почему коммунизм ООП неизбежен":Я пока дочитал до примера с виджетами:
interface Widget {
Dimension getSize;
Dimension getPreferredSize;
void setSize(Dimension size);
void paint(Display display);
}
...
interface CompositeWidget extends Widget {
void addWidget(Widget chld, Position p);
}
Как мне кажется, код на таком фреймворке будет очень трудно отлаживать. Состояние виджета скрыто за интерфейсом, и даже информация о иерархии находится в непрозрачном виде в CompositeWidget. Намного удобнее было бы, если бы все состояние всего дерева виджетов можно было легко сериализовать и просмотреть, например, в текстовом реадкторе, либо с помощью каких-то специальных средств (типа как developer tools в браузере). Например, в IDE Lighttable все данные, которые есть - это одна большая структура, которая не содержит в себе объектов, указателей на функции или стейта, спрятанного в замыканиях. Функции, которые дают динамическое поведение, отделены от этой структуры данных.
а мне больше нравятся с хорошей поддержкой в консоли. REPL, дебаг, сборка проекта и всё такое.
Среди них есть такие - на которых разработка динамичного сайта будет продуктивнее, чем на самом js?Фиг знает. Тут очень многое зависит от того, кто делает и что именно надо сделать. Объективных сравнений ни у кого нет.
И самое главное где посмотреть примеры реальных сайтов, которые используют код после этих трансляторов?http://bazqux.com/ - замена гугл ридеру.
Фронтэнд на Ur/Web, бэкэнд на хаскеле.
Еще вот тут были примеры занятные:
http://elm-lang.org/Examples.elm
(но сгенеренный код страшен - там свой рантайм, гоняющий события по графу)
Про другие не знаю, надо ходить по ссылкам и смотреть, есть ли там что.
Как мне кажется, код на таком фреймворке будет очень трудно отлаживать. Состояние виджета скрыто за интерфейсом, и даже информация о иерархии находится в непрозрачном виде в CompositeWidget. Намного удобнее было бы, если бы все состояние всего дерева виджетов можно было легко сериализовать и просмотреть, например, в текстовом реадкторе, либо с помощью каких-то специальных средств (типа как developer tools в браузере).А что, у пишущих на Java и C# хоть раз были проблемы, чтобы при отладке нельзя было посмотреть данные или в рантайме сериализовать в строку? toString - чуть ли не первое умение всех объектов в ООЯ. Для отладчика, знакомого с реализацией языка, все совершенно прозрачно же.
Есть, кстати, трансляторы ФЯ в javascript? И примеры так построенных сайтов?Clojure работает на js-машине.
Пример сайта как раз clojure.org.
А что, у пишущих на Java и C# хоть раз были проблемы, чтобы при отладке нельзя было посмотреть данные или в рантайме сериализовать в строку? toString - чуть ли не первое умение всех объектов в ООЯ. Для отладчика, знакомого с реализацией языка, все совершенно прозрачно же.всё правильно написал, просмотр дерева состояния UI элементов очень важная фича. Например, в каждом браузере это сейчас есть, а для WPF это делают только сторонние тулзы, написанные на коленке энтузиастами. По слухам Майкрософт после трехлетнего забвения вдруг начинает вдыхать новую жизнь в WPF. И первое что они делают – это в Visual Studio 2015 делают такой просмотрщик. Из него даже редактировать свойства можно будет и изменения попаду прям в исходный код. Для HTML такое делает только плагин к Хрому от Jetbrains. Я с сомнение отношусь к тому, что это спасет от забвения WPF, но тем не менее.
Как мне кажется, код на таком фреймворке будет очень трудно отлаживать.Ты ничего не понимаешь, главное же the natural way of human thinking. Ты не понимаешь мощь эмпатии. Отладка, кодирование это же рутина, скучно. Главное же духовна близость, взаимные сочувствие и сопереживания программистов.
toString - чуть ли не первое умение всех объектов в ООЯ. Для отладчика, знакомого с реализацией языка, все совершенно прозрачно же.В условной джаве этот метод toString надо писать самому. Для сравнения, если мы пишем на javascript в процедурном стиле (структуры данных без объектов и ссылок на функции то никакой особый toString не нужен - достаточно JSON.stringify(object). Затем, хотелось бы обратную операцию к toString - parseFromString, и еще deepClone. В джаве этого уже нет (есть только нечитаемая бинарная сериализация). В js есть JSON.parse и возможность сделать deepClone с помощью JSON.parse(JSON.stringify(obj.
Теперь, допустим мы хотим играть со свойствами виджетов вживую и смотреть что получается. Как указал Шурик, это инновация, которая появится в WPF только в 2015 году. Как это можно было бы реализовать в условном фреймворке, сделанном в стиле lighttable? Надо было бы добавить в фреймворк для режима отладки сервер, который умеет отдавать и получать json с деревом виджетов. При получении json он будет просто заменять структуру с виджетами на полученный json. Также надо написать простейший плагин к любому текстовому редактору, который работает с этим сервером. В текстовом редакторе мы просто правим json. Это очень просто реализовать и тут просто нечему глючить.
В условной джаве этот метод toString надо писать самому.Я понял. не ничего не знает про reflection и про обилие библиотек на Java.
то никакой особый toString не нуженТы продолжаешь делать весьма странные утверждения. Ещё раз попрошу, реши вот эту задачку или слейся:
struct some_key
{
int part_one;
int part_two;
};
Используя свою библиотеку, напиши на Си две простые функции:
void add(hash_t hashtable, struct some_key* key) - добавляет структуру в хэш таблицу
struct some_key* remove(hash_t hashtable, int part_one, int part_two) - удаляет и возвращает структуру из таблицы или NULL
погугли на тему java serialization. Будешь удивлён.
Как указал Шурик, это инновация, которая появится в WPF только в 2015 году.Шурик говорит о другом, он говорит о том, что это добавилось в штатную IDE. До этого необходимо было или брать сторонную приблуду, или городить свою.
Свойства WPF с рождения без проблем просматриваются(и меняются) штатными контролами PropertyGrid и DataGrid, и для этого достаточно накидать пару строк кода, чтобы смотреть и произвольные классы, и произвольные свойства.
мне больше нравятся с хорошей поддержкой в консоли. REPL, дебаг, сборка проекта и всё такое.в хорошей IDE всё это тоже есть.
Зачем надо противоставлять одно другому, если вместе оно работает намного лучше?
Пример сайта как раз clojure.org.Где там динамика на стороне браузера?
ps
нашел ее только в вики, но там используется стандартный Confluence
Я не противопоставляю, я указываю свои приоритеты. Если есть богатое IDE и богатая консоль одновременно - это замечательно. Если есть консоль, но нет IDE - для меня удобнее, чем если есть IDE, но нет консоли.
Microsoft же исправился, и с командной строкой у них сейчас неплохо, а IDE они давно хорошие делают.
Да я про него и не говорю. Я просто рассказывал, что мне больше нужно от обвязки некоторой абстрактной программистской технологии, а что меньше.
Я понял. не ничего не знает про reflection и про обилие библиотек на Java.Если для какой-то задачи X есть обилие библиотек, это значит не то, что с этой задачей все хорошо, а наоборот - есть безнадежная нерешенная проблема, и все время предпринимаются новые неудачные попытки ее решить.
Обилие библиотек так же может означать, что разным людям необходимы разные виды решения задачи.
Если для какой-то задачи X есть обилие библиотек, это значит не то, что с этой задачей все хорошо, а наоборот - есть безнадежная нерешенная проблема, и все время предпринимаются новые неудачные попытки ее решить.То есть python и JavaScript - полное гавно, и в них тысячи нерешённых проблем? Ну да, ну да, другое дело Си - там надо с нуля всё писать каждый раз.
погугли на тему java serialization. Будешь удивлён.Сериализация - важная вещь, так как она напрямую связана с управлением состоянием. Я считаю, что простоту сериализации можно использовать как поверхностный показатель качества системы. Например, по этому критерию, РСУБД - хорошо, потому что данные сериализуются в CSV, благодаря тому что все строки адресуются по id. Это одно из важных решений в архитектуре СУБД, которое дает еще кучу других плюсов. Другой пример: doc и xls, насколько я знаю, первоначально состояли из дампов внутренних структур ворда и экселя, благодаря этому они открывали и сохраняли файлы очень быстро, а программисты смогли выпустить продукт раньше, сократив время на разработку специальной сериализации.
В общем, сериализации тесно связана с тем, как мы храним состояние программы, и относится к архитектуре программы. Это не та задача, которая решается добавлением в проект джава-библиотеки.
Приведу пример. Допустим, мы пишем прогу для редактирования блок-схем, которая поддерживает сохранение, undo и redo. Элемент блок схемы можно выделить (дать фокус). Возникает вопрос, где должны храниться данные о том, какой элемент выделен. Я уверен, что большинство людей скажет, что надо сделать атрибут isFocused в классе для элемента блок-схемы. На самом деле, это решение с большим количеством минусов, скорее всего вообще ошибочное. Проблема в том, что атрибут isFocused не является персистентным, и при сериализации надо его будет игнорировать. Это потребует какой-то явной настройки сериализатора. Намного круче иметь отдельную структуру, в которой будут храниться все персистентные данные (граф элементов в блок-схеме и прямо класть эту структуру данных в undo историю (решив как-то вопрос с мутабельностью). Неперсистентные атрибуты хранить в отдельной структуре. Тогда при нажатии undo достаточно будет просто заменить один указатель - задача решена.
Посмотрим теперь на это с точки зрения ООП. Нам надо к какой-то из структур присовокупить методы. Какую структуру выбрать? ООП кодер просто не дойдет до этого момента, так как ему не придет мысль разъять свой объект на части.
Другой возможный вариант - считать, что выделение элемента - это не состояние элемента, а состояние всего графа. Тогда надо хранить где-то focusedElementId. ООП нас потталкивает сделать метод isFocused у класса "элемент графа". Чтобы реализовать этот метод, надо иметь ссылку на структуру, где хранится isFocused. У нас появляются ненужные ссылки, в точности как писал автор статьи. Появление кольцевых ссылок неизбежно, и ситуация с сериализацией становится совсем плохой.
Таким образом, мы приходим к тому, что нужна функция isFocused(graph, elementId но это значит полный отказ от ООП.
То есть python и JavaScript - полное гавно, и в них тысячи нерешённых проблем? Ну да, ну да, другое дело Си - там надо с нуля всё писать каждый раз.Я написал про обилие библиотек для какой-то одной задачи. Например, ситуация с типизацией в js - полное говно, люди сочиняют десятки языков с типизацией, которые компилятся в js. Начиная с некоторого момента, каждый новый язык только увеличивает фрагментацию и общую дерьмовость ситуации.
С сериализацией в js наоборот все очень хорошо, поэтому большого количества библиотек не наблюдается (я ни одной не видел).
В общем, сериализации тесно связана с тем, как мы храним состояние программы, и относится к архитектуре программы. Это не та задача, которая решается добавлением в проект джава-библиотеки.А зачем ты тогда приводил её в пример? Рассказывал про волшебные макросы, которые генерируют toString автоматически для сишных структур.
С сериализацией в js наоборот все очень хорошо, поэтому большого количества библиотек не наблюдается (я ни одной не видел).значит плохо искал. Есть куча целей для сериализации помимо json - и для конверсии в них нужны библиотеки.
С сериализацией в js наоборот все очень хорошо, поэтому большого количества библиотек не наблюдается (я ни одной не видел).Во-первых, ООП тут давно не при чём.
Во-вторых, ты не понимаешь, что одна и та же задача может требовать десятки решений. Траффик на вес золота - protobuf, читаемость - simple, хоть какая-то совместимость - soap, обмен расшияемыми сообщениями - xmpp, и так далее. И всё это обилие реально нужно и позволяет наиболее эффективно решать конкретные задачи. И все эти виды сериализации есть на всех платформах, а одного только json было бы недостаточно.
В-третьих, когда ты по не знанию ляпнул, что в Си у тебя будет меньше boilerplate, чем в Java для работы с хэш таблицей, тебе тоже пришлось откопать какую-то библиотеку.
В-третьих, когда ты по не знанию ляпнул, что в Си у тебя будет меньше boilerplate, чем в Java для работы с хэш таблицейЯ утверждал, что C требует меньше бойлерплейта для хэширования структуры Card.
Я утверждал, что C требует меньше бойлерплейта для хэширования структуры Card.Тогда напиши код, который я просил. Чтобы сравнить, где будет больше и чего. Или ты согласен, что ООП опережает структурный язык даже в такой простой задаче, как сохранение в хэш таблице?
Во-вторых, ты не понимаешь, что одна и та же задача может требовать десятки решений. Траффик на вес золота - protobuf, читаемость - simple, хоть какая-то совместимость - soap, обмен расшияемыми сообщениями - xmpp, и так далее. И всё это обилие реально нужно и позволяет наиболее эффективно решать конкретные задачи. И все эти виды сериализации есть на всех платформах, а одного только json было бы недостаточно.Да, ты прав что под разные протоколы обязательно требуются специальные библиотеки. Я имел в виду (конечно, надо было сформулировать это явно) родную сериализацию для языка, которая используется для отладки, клонирования, простой реализации load/save итд. Для javascript используется json. Для джавы есть два родных формата - java.io.Serializable и xml (в силу того что jaxb официально является частью Java SE). Serializable - бинарный, а JAXB - крайне неудобный, поэтому делают альтернативные библиотеки для XML или подрубают либы для того же json.
В общем, когда мне надо в js вывести структуру в лог, я делаю json.stringify(data и задача решена, а джаве надо еще предпринимать какие-то действия. В таком смысле, у джавы ситуация с сериализацией хуже чем в js.
В общем, когда мне надо в js вывести структуру в лог, я делаю json.stringify(data и задача решена, а джаве надо еще предпринимать какие-то действия. В таком смысле, у джавы ситуация с сериализацией хуже чем в js.Ты не понимаешь, что действия в обоих случаях надо предпринимать одинаковые?
Или ты согласен, что ООП опережает структурный язык даже в такой простой задаче, как сохранение в хэш таблице?Я согласен, что высокоуровневый язык опережает ассемблер. Объектность тут ни при чем. Уберем из явы возможность писать методы в классах, добавим указатели на функции. Работа с хэштаблицей станет выглядеть так:
int hashCard(Card card){...}
java.util.HashSet<Card> cards = java.util.HashSet.create<Card>(hashCard);
Card card = new Card(1,1);
java.util.HashSet.put(cards,card);
Ты не понимаешь, что действия в обоих случаях надо предпринимать одинаковые?А расскажи, как ты поступаешь, когда надо в отладочных целях распечатать структуру на джаве (даже без ссылок на другие структуры, состоящую только из String,int итд)?
Card card = new Card(1,1);Это вызов метода.
Работа с хэштаблицей станет выглядеть так:То есть кода станет больше, что и требовалось доказать.
Это вызов метода.Почему метода, а не функции?
А расскажи, как ты поступаешь, когда надо в отладочных целях распечатать структуру на джаве (даже без ссылок на другие структуры, состоящую только из String,int итд)?У меня такой цели обычно не возникает. Я даже не задумывался, почему. Наверное, из-за удобства и доступности отладчиков. Если же требуется систематический вывод в лог каких-то данных, то я не против использования toString только оформление строки должно быть human readable, а не около того.
То есть ты фактически взял какую-то проблему, которую тебе нужно решать, и которую ты знаешь или привык решать каким-то определённым образом. Затем ты пытаешься с помощью этой проблемы критиковать другую технологию, о которой не имеешь понятия, и в которой могут быть свои способы решения твоей проблемы.
Почему метода, а не функции?Потому что ты вкладывал такой смысл в эту строку.
В общем, когда мне надо в js вывести структуру в лог, я делаю json.stringify(data)А если структура - закольцованный двухсвязный список, он осилит stringify сделать?
В общем, сериализации тесно связана с тем, как мы храним состояние программы, и относится к архитектуре программы. Это не та задача, которая решается добавлением в проект джава-библиотеки.

Проблема в том, что атрибут isFocused не является персистентным, и при сериализации надо его будет игнорировать.Проблема в том, что ты сам выдумал задачу, и сам решаешь её неправильно. Сериализуемые данные отделяют от рантайм данных уже давно, в том числе для этого придумали DTO.
Намного круче иметь отдельную структуру, в которой будут храниться все персистентные данные (граф элементов в блок-схеме и прямо класть эту структуру данных в undo историю (решив как-то вопрос с мутабельностью).И регулярно получая out of memory от клиентов, когда они двигают один блок мышью. А вот при использовании ООП мы выберем паттерны Command, Composite и Memento. И сможем легко хранить в истории одну сущность, а не весь граф. При желании даже сериализация не потребуется.
Посмотрим теперь на это с точки зрения ООП. Нам надо к какой-то из структур присовокупить методы. Какую структуру выбрать?Если нам это надо, то мы, очевидно, понимаем, какую структуру мы выбрали. Ты же сам отделил сериализуемые данные и рантайм в процедурном подходе, с чего ты взял, что при использовании ООП будет что-то другое?
ООП кодер просто не дойдет до этого момента, так как ему не придет мысль разъять свой объект на части.Оригинальная критика, блядь! Ты понимаешь, что "кодеру" на процедурном языке тоже ничего в голову не придёт? Твоя аргументация на уровне "закрыл глаза - стало темно - меня никто не видит". Ты ещё напиши, что ООП подталкивает сделать один класс и всё написать внутри него, тогда как в процедурном стиле будет полное разделение ответственностей между функциями, модулями и структурами данных. Или напиши, что Ока круче Ховера, потому что Ховер подталкивает тебя сразу же въехать в столб, а на Оке ты аккуратно едешь, соблюдая ПДД.
Ты ещё напиши, что ООП подталкивает сделать один класс и всё написать внутри него, тогда как в процедурном стиле будет полное разделение ответственностей между функциями, модулями и структурами данных.Если бы ключевым моментом было бы разделение ответственности, то и назвали бы Ответственность Ориентированное Программирование. В название обычно выносят ключевое свойство. То, что сохраняя ООП, пытаются подсунуть какую-то еще идеологию, это от слабости и несамостоятельности этой новой идеологии. Как раз ровно вот так "закрыл глаза - стало темно - меня никто не видит". Вместо того чтобы признать, что объектная идеология вредит, пытаются закрывать глаза на проблему — до сих пор нет ясной методологии как правильно разбивать на модули.
Если бы ключевым моментом было бы разделение ответственности, то и назвали бы Ответственность Ориентированное Программирование.Любая технология содержит много ключевых моментов, которые не помещаются в её определение. Так что это не аргумент.
Вместо того чтобы признать, что объектная идеология вредит, пытаются закрывать глаза на проблему — до сих пор нет ясной методологии как правильно разбивать на модули.Есть методологии, и они вполне себе ясные. Ты же сам от них отказываешься, говоря, что надо кодить, а не заниматься проектированием. Поэтому тебе кажется, что данный подход вредит. Точно так же тебе будет казаться и при использовании любого другого подхода, в которых ты слабо разбираешься.
Есть методологии, и они вполне себе ясные. Ты же сам от них отказываешься, говоря, что надо кодить, а не заниматься проектированием. Поэтому тебе кажется, что данный подход вредит. Точно так же тебе будет казаться и при использовании любого другого подхода, в которых ты слабо разбираешься.я вижу как другие применяют эти методологии и вижу результат. Без слез на него не посмотришь.
я вижу как другие применяют эти методологии и вижу результат. Без слез на него не посмотришь.Пока что только результат, когда никаких методологий не применяют. И да, я плакал. От смеха.
Пока что мы видели только результат, когда никаких методологий не применяют. И да, я плакал. От смеха.Покажи как с помощью ООП можно написать лучше.
Хороший код, который удобно поддерживать и развивать. Что не так?Зачем же ты стёр свой замечательный комментарий?
Покажи как с помощью ООП можно написать лучше.Переписывать ко-ку? Нет уж, простите. Приводи короткие примеры такого говна, на которое я дал ссылку. Если ответ будет не очевиден, то я покажу, как можно написать лучше.
Переписывать ко-ку? Нет уж, простите. Приводи короткие примеры такого говна, на которое я дал ссылку. Если ответ будет не очевиден, то я покажу, как можно написать лучше.Т.е. лучшего варианта у тебя нет, и при этом ты делаешь вывод, что тот плохой. Убедительно.
Т.е. лучшего варианта у тебя нет, и при этом ты делаешь вывод, что тот плохой. Убедительно.Мы уже неоднократно обсуждали, почему твой код выглядит плохо, не является читаемым и слишком сложен для доработок и исправлений. Для этого не нужен никакой "лучший вариант". Потому что тогда можно привести любой кусок говна на сотни строк и сказать то же самое: перепишите красиво и не ебёт. Увы, выводы можно сделать и без переписывания твоего кода.
Мыэто ты о себе, так возвышено?
это ты о себе, так возвышено?А ты не принимал участие в той дискуссии? Я хорошо помню слёзки, обидки и два или три игнора, когда ты окончательно сливался.
Нашел очень крутой пост. Описывается Entity component system в программировании игр. Объект представляется как набор компонентов, компонент - это кусок данных. Например, могут быть компоненты position, attack. Компоненты группируются не по сущностям, а по типам компонентов. Например, все компоненты position могут лежать в отдельном массиве, что увеличивает производительность системы, которая работает с компонентами этого типа. Например, систему вычисления столкновений интересуют только компоненты, которые отвечают за размер и позицию объекта в пространстве, и не интересуют никакие другие.
аспект-ориентированное программирование типа?
Понятно, а ООП тут причем?
ООП тебя ведь не обязывает держать данные в классе описываеющий какую то сущность.
Можешь сслылаться на что угодно, на всякие таблицы где данные сортированны в угодном порядке.
ООП тебя ведь не обязывает держать данные в классе описываеющий какую то сущность.
Можешь сслылаться на что угодно, на всякие таблицы где данные сортированны в угодном порядке.
аспект-ориентированное программирование типа?Если это и АОП, то "для бедных". В АОП появляется, что аспекты собираются в единую сущность компилятором, а здесь такой сборки нет.
Отличное видео с демонстрацией сериализации состояния. Пользователь открывает два окна в браузере, в одном окне открывает GUI и вводит в текстовое поле какой-то текст. Затем он сериализует состояние GUI в строку, копирует строку в буфер обмена, переходит в другое окно браузера, копипастит туда эту строку, и получает в этом окне такое же состояние интерфейса, включая введенный текст.
Используется библиотека Om, в которой состояние интерфейса представлено в виде одного большого немутабельного дерева. У каждого виджета есть что-то типа линзы, которая позволяет менять эту структуру.
Используется библиотека Om, в которой состояние интерфейса представлено в виде одного большого немутабельного дерева. У каждого виджета есть что-то типа линзы, которая позволяет менять эту структуру.
Мне эти теоретические извращения не нравятся, поскольку там всё равно в итоге работа с DOM-ом. Если бы они эти концепции строили с более низкого уровня, прям от графического рендеринга, т.е. как замену DOM-у, тогда это еще стоило бы внимания. Работа напрямую с DOM-ом плюс состояние в самом DOM-е плюс статическая типизация вполне дает управляемый код.
Нашел очень крутой пост. Описывается Entity component system в программировании игр. Объект представляется как набор компонентов, компонент - это кусок данных. Например, могут быть компоненты position, attack. Компоненты группируются не по сущностям, а по типам компонентов. Например, все компоненты position могут лежать в отдельном массиве, что увеличивает производительность системы, которая работает с компонентами этого типа. Например, систему вычисления столкновений интересуют только компоненты, которые отвечают за размер и позицию объекта в пространстве, и не интересуют никакие другие.Это выглядит очень красиво, особенно если делать инструмент для создания игр без программирования. Например, так устроена Unity 3D, на которой я выпустил уже 10 игр под мобильные платформы. На самом деле не всё так радужно, как ты описываешь. Всё хорошо, пока ты рисуешь обычную не интерактивную сцену, где объекты не реагируют друг на друга и нет никакой игровой логики. Как только ты начнёшь делать логику, у тебя начнутся различные проблемы.
Если написать игру полностью на компонентах, которые обмениваются сообщениями, то её производительность умирает в overhead-ах. Это связано в том числе с тем, что компоненты используются для описания поведения игровых объектов. Например, для передвижения игрока ты должен не просто поменять поле position класса Player, а менять поле position компонента Transform, привязанного к тому же объекту, что и класс Player.
Пойдём дальше: наличие или отсутствие компонентов влияет на другие компоненты и диктует правила их работы. Если на объекте игрока есть компонент Rigidbody, то есть он подключен к физическому движку, то его уже нельзя двигать, меняя поле position компонента Transform. Теперь игрока надо двигать, прилагая физические силы или импульсы, или вызывая MoveTo для нереалистичного движения.
В любой игре компоненты должны обмениваться данными. Если это делать неявно, то в более-менее большой игре ты просто утонешь в попытках понять связи между компонентами, и в попытках избавиться от побочных эффектов. Например, в компоненте Monster (где реализуется логика работы монстра) ты получаешь сообщение от компонента физики OnCollisionEnter что может означать столкновение монстра с пулей. Допустим, ты убиваешь монстра, уничтожая его объект и подменяя его на ragdoll. Это ведёт к побочным эффектам, например, другой компонент тоже столкнулся с монстром и присылает OnCollisionEnter где уже нельзя работать с объектом, потому что ты его уничтожил.
Как итог, чтобы сделать стабильную, не падающую игру, не потеряв FPS, компоненты приходится использовать как View в MVP/Passive View, а для реализации игровой логики лучше оставаться в рамках ООП.
вообще, я пробовал в своем движке вводить entity components, но в с++ это все превращается в месиво из dynamic_cast и бесконечные проверки на тип и такие костыли приходится вворачивать, что страшно становится
к тому же компонентная архитектура с определенного момента требует писать какую-то систему сборки мусора, т.к. становится сложно отследить зависимости объектов, их время жизни и прочее, что очень плохо с архитектурной точки зрения. ИМХО, хорошая архитектура должна позволять в любой момент времени понять время жизни объекта и его зависимости
в сухом остатке: красивая идея, но на практике слишком много подводных камней
к тому же компонентная архитектура с определенного момента требует писать какую-то систему сборки мусора, т.к. становится сложно отследить зависимости объектов, их время жизни и прочее, что очень плохо с архитектурной точки зрения. ИМХО, хорошая архитектура должна позволять в любой момент времени понять время жизни объекта и его зависимости
в сухом остатке: красивая идея, но на практике слишком много подводных камней
и каждый модуль разместить в отдельной папке/файле, использовать его как отдельную единицу линковки итд. ООП подход, как он повсеместно используется, вынуждает создать огромный файл с классом, в котором реализованы все методы, как-то связанные с этим классом.Т.е. вопрос в папках и файлах? Сейчас при работе в IDE (для статически типизированного языка) папки и файлы становятся мало заметными, поскольку навигация идет непосредственно по элементам кода. Папки и файлы совсем редко использую для навигации.
Допустим, ты убиваешь монстра, уничтожая его объект и подменяя его на ragdoll. Это ведёт к побочным эффектам, например, другой компонент тоже столкнулся с монстром и присылает OnCollisionEnter где уже нельзя работать с объектом, потому что ты его уничтожил.Спасибо за развернутый ответ.
А эта проблема которую ты описываешь возникает именно из-за компонентов?
Оставить комментарий
luna89
Наткнулся на отличный пост с критикой ООП подхода.Абсолютно все web и enterprise приложения, в разработке которых я участвовал, страдали от проблем, перечисленных в статье. Основная причина проблем - смешивание структур данных и алгоритмов в одном файле, в результате чего становится непонятно, какие в программе данные, а какие алгоритмы. ООП не дает собрать объявления всех структур данных в одном файле. Зачастую, если посмотреть на объявления структур данных, то алгоритмы становятся очевидными и тривиальными. Например, часто enterprise приложение состоит из сотен пакетов с тысячами классов, в которых разобраться очень сложно. Но если посмотреть на структуру таблиц в базе данных и на внешние ключи, то все становится понятно.
Затем, если бы процедуры лежали отдельно от данных, то автоматически бы исчезли многие проблемы с модульностью. Мы бы могли сделать сколько угодно модулей, которые работают с одной и той же структурой данных, и каждый модуль разместить в отдельной папке/файле, использовать его как отдельную единицу линковки итд. ООП подход, как он повсеместно используется, вынуждает создать огромный файл с классом, в котором реализованы все методы, как-то связанные с этим классом.
Очень серьезная проблема возникает с повторным использованием кода. Я говорю о известной критике Joe Armstrong:
Там, где в процедурном подходе была бы обычная функция, которая принимает данные в аргументах, в ООП эта функция становится методом класса, который содержит в себе данные, нужные для ее работы, но кроме них еще кучу других данных и методов. Отдельно инстанцировать этот класс, чтобы дернуть один метод становится невозможным.
Опытные "ООП-архитекторы" знают о самых очевидных из этих граблей и умеют их избегать, но корень зла в изначально неверном подходе. В заключение процитирую самый важный отрывок из исходной статьи: