Смешивание данных и указателей на функции
на.хер->
Мне тоже не нравится, что функции нельзя сериализовать. События - это, вообще, тихий ужас.
Заменил и то, и другое в бизнес логике на декларативное задание функций. Фактически, получился недо-Lisp.
Заменил и то, и другое в бизнес логике на декларативное задание функций. Фактически, получился недо-Lisp.
События - это, вообще, тихий ужас.Да, кошмар конкретный. Насуют в массив указателей, куда они ведут можно потом разобраться только пошаговым отладчиком.
immutable указатели на функцию вполне себе ок
Насуют в массив указателей, куда они ведут можно потом разобраться только пошаговым отладчиком.Имхо, проблема в том, что по указателю на функцию нельзя штатными средствами получить идентификатор функции и тело функции. С самими указателями проблемы нет.
> f = function(x){return x}
[Function]
> a = f
[Function]
> a.toString()
'function (x){return x}'
> a.length
1
Хотя контекст функции ты так не получишь конечно

Хотя контекст функции ты так не получишь конечноесли поковыряться, то и контекст можно получить, правда только в GUI
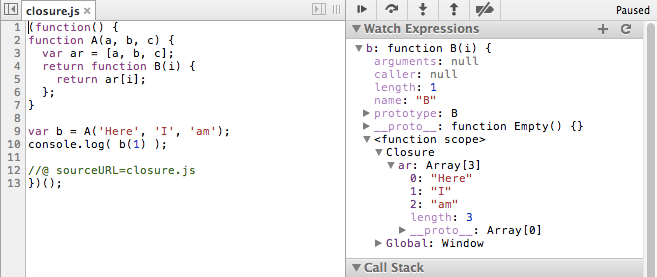
Хотя контекст функции ты так не получишь конечноКак будто в ООП языках, можно получить все проперти объекта.
[Function]Это не работает в более-менее нетривиальных случаях. Стоит обернуть функцию в другую функцию, и это не работает:
> a.toString()
function test(){
console.log('test');
}
function logInvocation(fn){
return function(){
console.log('invoked ' + fn.name);
return fn.apply(this, arguments);
}
}
(logInvocation(test)).toString()
/* prints
"function (){
console.log('invoked! ' + fn.name);
return fn.apply(this, arguments);
}"
*/
К тому же, это работает за счет возможностей js-рантайма. Нормальная архитектура должна работать без использования специфичных для платформы возможностей.
Это не работает в более-менее нетривиальных случаях.Случай тривиальный. Тебе же пишут тут про контекст.
Замыкания нетрудно превращать в строки, надо только, чтобы разработчики платформы
Случай тривиальный. Тебе же пишут тут про контекст.Это работает под одну платформу - Google Chrome, и доступно только через GUI. Программно контекст не достать. В других языках программирования это вообще может быть невозможно.
Замыкания нетрудно превращать в строки, надо только, чтобы разработчики платформы имели это у себя дома задумались наконец об этом.Мне надо сериализовать данные, чтобы потом загрузить их или сохранить. Если я буду сериализовывать замыкания в строки, то что, мне на диск в файлы эти строки с кодом сохранять что ли? В том-то и смысл, что я могу модифицировать программу, а данные останутся те же.
ну так добавь к функции метод сериализовать и десериализовать.
В том-то и смысл, что я могу модифицировать программу, а данные останутся те же.В чем проблема тогда? Ты хочешь изменить программу, но так, чтобы не изменить программу?
Программно контекст не достать. В других языках программирования это вообще может быть невозможно.Абсолютно верно.
Немало есть языков, в которых и замыкания-то не возможны.
И ч0?
И вообще, что такое "указатели на функции"? Зачем люди постоянно смешивают понятия и способы низкоуровневой реализации?
И вообще, что такое "указатели на функции"?Тип T с операциями:
- Call: позвать выполнение функции
- (не везде) Еqual: сравнить на равенство с экземпляром типа T
- (не везде) ToTempId: преобразовать к идентификатору примитивного типа. Соответствие между идентификатором и типом T локально для процесса и существует не дольше времени жизни процесса.
Ужас!
Где?
Где?Сигнатура где?
type FunctionPointer<TResult, TArgs, TId> where TId:TPrimitive
{
TResult Call(TArgs args);
static bool Equal(FunctionPointer p1, FunctionPointer p2)
TId ToTempId();
static FunctionPointer FromTempId<TProcess(TProcess process, TId id);
}
Зачем люди постоянно смешивают данные и указатели на функции?Ответ: Abstract Data Types.
То, о чем ты думаешь, годится лишь когда у тебя все данные в публично описанных структурах всеми кишками наружу. Это работает на маленьких проектах, но чтобы сделать что-то побольше, нужно уметь абстрагироваться, когда о типе неизвестно, что там внутри, зато известны доступные операции (это не обязательно должно быть ООП, можно и тайпклассы, один хрен). Тут же и получаем сабж.
это не обязательно должно быть ООП, можно и тайпклассы, один хренВроде бы тайпклассы не добавляют к данным указатели? Насколько я знаю, если есть функция:
sequence :: Monad m => [m a] -> m [a]
то у нее первым аргументом (Monad m) неявно передается таблица вирутальных методов. Таким образом, смешения данных с функциями не происходит.
нужно уметь абстрагироваться, когда о типе неизвестно, что там внутри, зато известны доступные операцииМожно выдавать хэндлы, которые представляют из себя просто идетификаторы (как при работе с файловой системой). Можно написать в документации, что надо расценивать тип как opaque, и работать с ним через функции из такого-то пакета.
Это работает на маленьких проектахКстати, если делать API, смешивая данные с указателями на функции, то мы теряем возможность вызывать API из другого процесса (так как нельзя сериализовать и передавать указатели на функции). Как раз предположение "все должно быть внутри одного процесса" работает только для маленьких программ.
Кстати, если делать API, смешивая данные с указателями на функции, то мы теряем возможность вызывать API из другого процесса (так как нельзя сериализовать и передавать указатели на функции). Как раз предположение "все должно быть внутри одного процесса" работает только для маленьких программ.Вовсе нет, если эти функции (а не указатели) передаются тоже.
первым аргументом (Monad m) неявно передается таблица вирутальных методов. Таким образом, смешения данных с функциями не происходит.Это не так уж отличается от неявной передачи первым аргументом ссылки на объект (а в нем ссылка на VMT). Да, они не хранятся вместе, но передаются туда-сюда вместе все равно.
Можно написать в документации, что надо расценивать тип как opaque, и работать с ним через функции из такого-то пакета.
Т.е. все равно эти данные кроме как теми функциями не обработать, все равно они логически привязаны, только теперь компилятор не особо гарантирует соответствие одних другим.
нужно уметь абстрагироваться, когда о типе неизвестно, что там внутри, зато известны доступные операцииКстати, подобный подход опасен тем, что возникают трудности, когда надо залогировать все вызовы API. Логировать все вызовы API может быть очень полезно, пример - strace.
В случае strace, линукс выдает хэндлы объектов (например файловые дескрипторы). Можно легко понять, когда появился дескриптор и какие операции с ним можно делать.
Другой пример, когда API устроено неправильно - HTML DOM. Там оперирование элементами делается через вызовы методов DOM элементов. Если бы там API было устроено так:
DOM.setAttribute(elementID, attr, value)
То я мог бы обернуть все функции из объекта DOM, и например логировать вызовы, цепляя к вызову таймстемп. Открываются интересные возможности, например можно проигрывать реплей пользовательской сессии.
Но API там устроено так:
element.setAttribute(attr,value)
Теперь я не могу обернуть методы элементов, так как я не контролирую создание объектов. Кроме того, я не могу залогировать вызов метода, так как у элементов нет никакой идентичности, которую я мог бы записать в лог.
Кроме того, я не могу залогировать вызов метода, так как у элементов нет никакой идентичности, которую я мог бы записать в лог.В .NET можно делать ID для объектов http://blogs.msdn.com/b/csharpfaq/archive/2015/02/23/edit-an...
Теперь я не могу обернуть методы элементов, так как я не контролирую создание объектов. Кроме того, я не могу залогировать вызов метода, так как у элементов нет никакой идентичности, которую я мог бы записать в лог.В js ты можешь заменить методы у существующих объектов, и к каждому объекту можешь добавить идентификатор, если это требуется для задач логирования.
ps
Имхо, для данной задачи большая проблема будет, что js - мутабельный и построен на событиях.
> проблемы с сериализацией
> проблемы с отладкой
> проблемы с горячей заменой кода
kexec?
пример:
boot tftp://192.168.0.1/vmlinuz
> проблемы с отладкой
(gdb) bt
0xffffffff80004d60 in __r4k_wait ()
0xffffffff8004ebe8 in cpu_startup_entry ()
0xffffffff8074db64 in start_kernel ()
> проблемы с горячей заменой кода
kexec?
пример:
struct clocksource {
/*
* Hotpath data, fits in a single cache line when the
* clocksource itself is cacheline aligned.
*/
cycle_t (*read)(struct clocksource *cs);
cycle_t mask;
u32 mult;
u32 shift;
u64 max_idle_ns;
u32 maxadj;
#ifdef CONFIG_ARCH_CLOCKSOURCE_DATA
struct arch_clocksource_data archdata;
#endif
const char *name;
struct list_head list;
int rating;
int (*enable)(struct clocksource *cs);
void (*disable)(struct clocksource *cs);
unsigned long flags;
void (*suspend)(struct clocksource *cs);
void (*resume)(struct clocksource *cs);
/* private: */
#ifdef CONFIG_CLOCKSOURCE_WATCHDOG
/* Watchdog related data, used by the framework */
struct list_head wd_list;
cycle_t cs_last;
cycle_t wd_last;
#endif
struct module *owner;
} ____cacheline_aligned;
В .NET можно делать ID для объектов http://blogs.msdn.com/b/csharpfaq/archive/2015/02/23/edit-an...У меня от этой картинки кровь из глаз пошла: http://blogs.msdn.com/cfs-file.ashx/__key/communityserver-bl...
Типа, дотнет позволяет сделать мутабельный круг, а потом следить в дебаггере за судьбой этого круга - как ему радиус меняют?
В js ты можешь заменить методы у существующих объектов, и к каждому объекту можешь добавить идентификатор, если это требуется для задач логирования.Зачем, если можно сразу все нормально закодировать? Менять методы существующих объектов - вообще фигня какая-то, добавлять идентификатор в существующий объект - тоже не очень, например с точки зрения производительности - рантайм уже не может рассчитывать на фиксированное представление объекта в памяти.
рантайм уже не может рассчитывать на фиксированное представление объекта в памяти.JIT + деоптимизация, не?

Да как нефиг делать
oldMethod = HTMLElement.prototype.setAttribute;
HTMLElement.prototype.setAttribute = function() {
console.log(arguments);
return oldMethod.apply(this,arguments);
}
Оставить комментарий
luna89
Зачем люди постоянно смешивают данные и указатели на функции? Из-за этого постоянно возникают- проблемы с сериализацией (указатели на функции несериализуемы). Трудно сделать сохранение/загрузку состояния, что важно в любой нетривиальной программе.
- проблемы с отладкой. Указатель - какой-то бинарный адрес, непонятно куда он ведет и что значит.
- проблемы с горячей заменой кода. Если указатель на функцию свободно расползается по структурам данных, то становится невозможно пройтись по всем местам и заменить его на другой указатель.
Примеры:
- С++ пихает в объект указатель на VMT. Вообще ООП в этом смысле самый раковый подход.
- в HTML DOM, чтобы добавить в элемент реакцию на событие, требуется сохранить в нем указатель на js функцию. После этого DOM невозможно сериализовать, и невозможно заменить эту функцию на другую функцию.
Как я предлагаю бороться с этим:
В структурах данных держим тэг типа (для низкоуровневых языков просто число, для высокоуровневых - строка). Тэг можно спокойно сериализовать/десериализовать. Отдельно держим таблицу тэг->указатель на функцию. Теперь мы спокойно можем манипулировать этой таблицей, и это изменение сразу будет отражаться на всех структурах с этим тэгом.
Расскажите о своем опыте. Перемешиваете ли вы в своем коде данные с указателями на функции?