Объясните нубу, почему сейчас сайты модно делать на python
Язык медленный достаточно, высокоскоростные вещи строго не стоит писать, но зато остальное...
Чертовский краткий, удобно писать,не склоняет к говнокоду.
Чертовский краткий, удобно писать,не склоняет к говнокоду.
а чем RoR хуже django и соответственно ruby питона?
Что-то куда не плюнь, везде питон, тындекс плавненько переводит все разработки на него, стартапы модно на нем ваять сейчас.Да ну? Руби вроде в разы популярнее.
В чем заключаются преимущества именно питона перед другими языками для сайтостроения?
PS: предрекаю, что они будут убиты кофескриптом.
Объектно ориентирован.
Высокая скорость развертывания и модификации. Да, скорость выполнения страдает, но в интернет-запросах итак присутствуют лаги, поэтому для веб-посетителей это практически незаметно.
Модульность (применяешь уже написанные и обкатанные инструменты, или кем-то, или свои).
Отмечу, что при любви к написанию сайтов на Python очень не люблю Django. Использую свою связку аналогичных обкатанных фреймворков (Pylons, SQLA, Mako/Genshi, PyQGIS).
В стартапах-однодневках важно, чтобы сайт работал не "быстро", а "завтра". Плюс, как правило, сам заказчик не имеет четкой схемы, чего он от сайта хочет. Может менять ТЗ каждые 4 часа.
Предполагается, что после меня (когда сайт уже написан, пяток раз переделан, утвержден и функционирует), заказчик должен пригласить программера, который один раз переведет всё на высокий уровень. Но этого часто не делают. С чем я собственно не согласен (за исключением работы с C-библиотеками).
Высокая скорость развертывания и модификации. Да, скорость выполнения страдает, но в интернет-запросах итак присутствуют лаги, поэтому для веб-посетителей это практически незаметно.
Модульность (применяешь уже написанные и обкатанные инструменты, или кем-то, или свои).
Отмечу, что при любви к написанию сайтов на Python очень не люблю Django. Использую свою связку аналогичных обкатанных фреймворков (Pylons, SQLA, Mako/Genshi, PyQGIS).
В стартапах-однодневках важно, чтобы сайт работал не "быстро", а "завтра". Плюс, как правило, сам заказчик не имеет четкой схемы, чего он от сайта хочет. Может менять ТЗ каждые 4 часа.
Предполагается, что после меня (когда сайт уже написан, пяток раз переделан, утвержден и функционирует), заказчик должен пригласить программера, который один раз переведет всё на высокий уровень. Но этого часто не делают. С чем я собственно не согласен (за исключением работы с C-библиотеками).
вопрос скорее какие альтернативы ты видиш?
а что ты можешь сказать о питоновском фреймворке nagare?
Предполагается, что после меня ...спасибо за честное признание
заказчик должен пригласить программера, который один раз переведет всё на высокий уровень. Но этого часто не делают.
Ты знаешь почему они этого не делают?

а что ты можешь сказать о питоновском фреймворке nagare?Только то, что я с ним не работал. Фреймворк требует stackless, я на его изучение времени так пока и не выделил. Их философия мне тоже неизвестна.
Так исторически сложилось, что я работаю с TurboGears 2 (с 2009 г.). Автор — европеец, хороший feedback, проект постоянно развивается и становится все более гибким. Всё необходимое, что мне нужно для быстрого развертывания, присутствует.
Ты знаешь почему они этого не делают?Нет. Могу только предполагать:
- сайты не достигают высоких нагрузок,
- экономят,
- стартап умирает раньше.
Ты знаешь почему они этого не делают?Экономически не выгодно?
Если софт работает не на сотне серверов, то вместо того чтобы нанимать хорошего программиста, который перепишет всё на быстром языке может оказаться дешевле воткнуть рядом второй сервер или заапегрейдить первый. учитывая, что хороший программист за месяц хочет денег, больше чем стоит сервер приличный.
а что по вашему хороший программист только проблему производительности решает?
Яндекс давно уже в своих проектах перешел на Джанго. Сначала все команды писали на разных языках и довольно часто не успевали запустить первую версию к срокам. Поэтому было решено всем освоить питон и писать прототипы на Джанго. Потом оказалось, что эти прототипы почти всегда имеют достаточную производительность(если нужно то высоконагруженные части переписываются на C). Скорость разработки на Джанго действительно очень высока, производительность достаточна, используются современные подходы и технологии, Питон легок в изучении для опытных программистов - все это делает данный фреймворк хорошим выбором для web-разработки в большинстве случаев разработки с нуля.
Хорошей альтернативой с похожим языком и концепциями является RoR.
Хорошей альтернативой с похожим языком и концепциями является RoR.
Яндекс давно уже в своих проектах перешел на Джанго.Какая субд используется в яндексовых джанго проектах, если не секрет?
А можешь привести примеры проектов Я. сделанных на Django? Скажем, Музыка, Видео, Карты, Маркет или Почта, они используют Django?
Какая субдСтавлю на mysql.
А можешь привести примеры проектов Я. сделанных на Django? Скажем, Музыка, Видео, Карты, Маркет или Почта, они используют Django?через гугл вот это нашел http://www.youtube.com/watch?v=_VyPNATTC4w

Если посмотреть видио дальше, то чувак рассказывает плюшки питона, которые как раз уже есть в C#, но нет в Java. Сложилась вот такая херовая ситуация в не виндоз мире: java отстала в развитии, а если не java, то остаются только динамические языки. Это похоже на ситуацию в браузере, где только javascript. А виндовс для разработчиков не алё.
ну насколько я в курсе про тындекс они сейчас множество разработок с перла переводят на питон, проблема связана как раз таки с тем что кадров перловых мало и поддерживать перл сложнее.
но чето в питоне тоже не все так просто язык вроде развивается, только они сейчас держат 2 лид бренча 2.7 и 3.х, без обратной совместимости со стороны последнего, вот тоже спрашивается нашуя ?
но чето в питоне тоже не все так просто язык вроде развивается, только они сейчас держат 2 лид бренча 2.7 и 3.х, без обратной совместимости со стороны последнего, вот тоже спрашивается нашуя ?
которые как раз уже есть в C#, но нет в Javaя знаю у java только одну проблему: type erasure (которую почему-то даже не пытаются решить в новых версиях java). Ты имел в виду именно его или что-то иное?
Что ты называешь обратной совместимостью? 2.х и 3.х это две разные ветки развития. Считать 3.х следующей версией — заблуждение.
Оффтоп: забыл указать еще одно преимущество: кроссплатформенность.
Оффтоп: забыл указать еще одно преимущество: кроссплатформенность.
я имел ввиду язык java. Ты, наверное, имеешь ввиду scala. Почему яндекс не переходит на scala? Ну...
Почему яндекс не переходит на scalaА кто сказал, что он вообще куда-то там должен переходить? Может у них там зоопарк технологий внутри и их это не особо парит? Ну не всем же должен нравиться подход "один язык, один фреймворк, одна ОС".
А кто сказал, что он вообще куда-то там должен переходить?ну чувак в начале видео рассказывает же почему и зачем они на питон+джанго перешли.
почему и зачем они на питон+джанго перешли
Они это кто и сколько их? Явно не весь Я. Вон, часть Музыки сделана на clojure, но никто не говорит "Яндекс переходит на clojure". И слайд с перечнем их проектов на питоне меня как-то не впечатлил, ничего большого и светлого, чем лично я пользуюсь у Яндекса, в этом списке нет.
ну что ты цепляешься к словам, понятно что не весь яндекс. Но на предыдущий твой вопрос, почему надо переходить, парень отвечает:

Добавлю к этому. Еще лучший язык должен помогать в придумывании клевый штук.  Через структурирование мыслей.
Через структурирование мыслей.
Через структурирование мыслей.через гугл вот это нашел http://www.youtube.com/watch?v=_VyPNATTC4wВот тут в презентации пример запроса на питоновском ОРМе:
http://youtu.be/_VyPNATTC4w?t=14m47s
Непонятно, почему надо вместо простого понятного sql запроса городить какую-то мутную фигню на питоне.
При этом докладчик утверждает, что орм - половина джанги.
Никто не принуждает тебя юзать джанговский orm даже если у тебя проект на джанге. Ты можешь спокойно юзать sqlalchemy или вообще тупо MySQLdb/psycopg2. Но джанговский orm довольно таки удобен. Простые CRUD действия он обрабатывает на ура (и даже сам сгенерит gui для этого). А для сложных вещей часто проще сделать хитро замудренный view и указать его в качестве src table для django model, и далее из проекта обращатся с ним через django orm, чем средствами того же SQLA выполнять "простой и понятный sql запрос" и далее результат перекладывать на объектную модель.
Быстро сделав работающий прототип на django, никто потом не мешает вкорячить туда genshi/mako вместо "тормознутого" встроенного шаблонизатора, sqla вместо "корявого встроенного orm", и потом оставшуюся от django часть перевести на любой "нормальный" python framework.
Захостив всё это дело на чем нить типа nginx + uwsgi можно получить хорошо масштабируемое и возможно достаточно производительное решение, и может быть даже не придётся переписывать на чём нить более производительном.
Быстро сделав работающий прототип на django, никто потом не мешает вкорячить туда genshi/mako вместо "тормознутого" встроенного шаблонизатора, sqla вместо "корявого встроенного orm", и потом оставшуюся от django часть перевести на любой "нормальный" python framework.
Захостив всё это дело на чем нить типа nginx + uwsgi можно получить хорошо масштабируемое и возможно достаточно производительное решение, и может быть даже не придётся переписывать на чём нить более производительном.
не принуждает тебя юзать джанговский ormрусская вики врет?
Некоторые компоненты фреймворка между собой связаны слабо, поэтому их можно достаточно просто заменять на аналогичные. Например, вместо встроенных шаблонов можно использовать Mako (англ.) или Jinja.
В то же время заменять ряд компонентов (например, ORM) довольно сложно.
http://ru.wikipedia.org/wiki/Django
Непонятно, почему надо вместо простого понятного sql запроса городить какую-то мутную фигню на питоне.Не знаю. Это один из видов ментального извращения.
Меня тут еще вот что заинтересовало. Я загуглил упомянутый в этом треде TurboGears. У него второй в списке фич идет:
Support for Horizontal data partitioning (aka, sharding)
http://turbogears.org/
Почему шардинг делает орм, а не субд? По идеи шардингку самое место в модуле, который выполняет запросы. Вроде NewSQL этим и занимаются.
эммм
да, признаю, насчет не использовать совсем - это я погорячился. На него как минимум завязаны механизмы сессий и аутентификации. Да и чуть менее чем все дополнительные готовые apps для джанги (за что ее собственно и выбирают - за обилие готовых велосипедов). но никто не мешает в части касающейся собственно проекта совсем не использовать джанговский orm.
да, признаю, насчет не использовать совсем - это я погорячился. На него как минимум завязаны механизмы сессий и аутентификации. Да и чуть менее чем все дополнительные готовые apps для джанги (за что ее собственно и выбирают - за обилие готовых велосипедов). но никто не мешает в части касающейся собственно проекта совсем не использовать джанговский orm.
Вот тут в презентации пример запроса на питоновском ОРМеНе лучший пример, замечу.
а чем RoR хуже django и соответственно ruby питона?Джагно — срань и говнище, там ORM.
Писать надо без ORM. На любом языке найдутся пидорасы, которые придумают ORM, это не повод говорить что язык плохой.
Джагно — срань и говнище, там ORM.это неправославно?
ORM — это плохо во всех отношениях.
Первый раз за 13 лет занятий программированием слышу мнение, что "ORM это сраное говно, придуманное гомосексуалистами, писать надо без ORM".
Это я такой пещерный, или мнение уж больно нетрадиционное?
Это я такой пещерный, или мнение уж больно нетрадиционное?
ORM — это плохо во всех отношениях.Все три буквы? Или какие-то особенно плохи?
Это я такой пещерный, или мнение уж больно нетрадиционное?ты реально пещерный
да и еще, нет тут никаких традиций, есть то, что работает хорошо, есть то, что — плохо.
ПОТОМУЧТО
.......

.......
Первый раз за 13 лет занятий программированием слышу мнение,Серьезный выигрыш от orm-а есть в бизнес-ПО: там много разнообразных запросов, они часто меняются. Скорость вникания в код и разработки важнее скорости работы кода. Типичный use case: стажер должен быстренько влезть в код, поменять формулу расчета скидки, зачекинить и при этом ничего не уронить.
В сервисном ПО (типа yandex-а и т.д.), наоборот, вариативность запросов низкая, производительность кода важнее скорости вникания в код. Лишняя прослойка (в виде orm-а) частенько мешает воспользоваться функциональностью и производительностью db по максимуму.
ps
фанатичный и зашоренный разработчик сервисного ПО, и его мнение по поводу orm-а надо делить на порядок.
Что такое сервисное ПО?
Что такое сервисное ПО?Основные признаки: малое кол-во функций, малое кол-во настроек, пакетный(неинтерактивный) режим работы. Типичный пример: поисковик.
Массовые веб-сайты сейчас почти все такие. Даже соц. сети (хоть для них и кажется, что функций там много) имеют очень ограниченное кол-во функций. Особенно если это число сравнивать с теоретическом набором функций, который доступен для информации, крутящейся в соц. сетях.
Серьезный выигрыш от orm-а есть в бизнес-ПО: там много разнообразных запросов, они часто меняются. Скорость вникания в код и разработки важнее скорости работы кода. Типичный use case: стажер должен быстренько влезть в код, поменять формулу расчета скидки, зачекинить и при этом ничего не уронить.в SQL запрос проще вникать, и с ним проще разрабатывать
ps
фанатичный и зашоренный разработчик сервисного ПО, и его мнение по поводу orm-а надо делить на порядок.
я разработчик бизнес ПО. Мнение пианиста относительно orm полностью разделяю.
psмнение пианиста звучало каждые 45 минут на конференции разработчиков
фанатичный и зашоренный разработчик сервисного ПО, и его мнение по поводу orm-а надо делить на порядок
there was something in there telling us all to heap scorn upon ORMs at least once every 45 minutes. http://martinfowler.com/bliki/OrmHate.html
Удивительно прямо слышать анафему ORM-у от автора самой известной на форуме ORM Controllable Query.
Кажется, у нас имеет место конфликт определений.
Кажется, у нас имеет место конфликт определений.
Типичный use case: стажер должен быстренько влезть в код, поменять формулу расчета скидки, зачекинить и при этом ничего не уронитьэто неправильный юз кейс
такое отвалится на производительности или еще где
соседний тред про ява архитекторов подтверждает
Типичный use case: стажер должен быстренько влезть в код, поменять формулу расчета скидки, зачекинить и при этом ничего не уронить.Ну да, всякие Озоны регулярно проводят распродажи по таким use case-ам.

Controllable QueryCQ никогда не был ORM-ом
Кажется, у нас имеет место конфликт определений.
Контекст обсуждения в этом треде задал вот этот пример запроса
Т.е. для начала можно обсудить нахера запросы делать не на SQL.
А потом можем перейти и Unit of Work, Itity Map. А если зайдем слишком далеко, то можем и до ООП моделирования добраться.

Т.е. для начала можно обсудить нахера запросы делать не на SQL.у sql-я бедные возможности по добавлению абстрактных слоев.
CQ никогда не был ORM-омНу да, я все правильно понял:
Кажется, у нас имеет место конфликт определений.Я вот считаю, что и CQ, и Dapper - это все ORM. Другое дело, что они занимаются только маппингом, а запросы сами не генерируют. Ну и прекрасно, генерация запросов - не определяющая фича. Даже и название как бы намекает.
Т.е. для начала можно обсудить нахера запросы делать не на SQL.ОК. Почему бы не расписать, кто как будет делать определенную задачу на разных языках? Возьмем самую простую.
Не ради холивара, на который некоторые тут ориентированы. Просто для понимания, как работает незнакомый язык.
И не ради "ты мудак потому, что делаешь не так". Просто для объяснения.
М?
я за
Вот простая (и популярная) задача:
3 объекта (отражаемые в таблицы б.д.): Пользователи, Группы, Права.
Каждая отражаемая таблица имеет связь с другой m2m.
До завтрашнего обеда я выложу, как строится ORM и выполняются запросы в Turbogears 2.x.x, т.е. с применением SQLA.ORM (сейчас просто уже спать пора).
3 объекта (отражаемые в таблицы б.д.): Пользователи, Группы, Права.
Каждая отражаемая таблица имеет связь с другой m2m.
До завтрашнего обеда я выложу, как строится ORM и выполняются запросы в Turbogears 2.x.x, т.е. с применением SQLA.ORM (сейчас просто уже спать пора).
дать пользователю возможность с помощью gui настроить вывод в табличной форме набор элементов и их свойств.
Элементы могут располагаться как в одной таблице, так и в нескольких, быть как однотипными, так и разнотипными.
Свойства бывают трех видов:
- simple property. поля в той же таблице, что и сам элемент
- custom property. свойства хранящие в дочерней таблице в виде propid, propvalue
- aggregate property. некая функция над полями и связями элемента, возвращающая скалярное значение
Элементы могут располагаться как в одной таблице, так и в нескольких, быть как однотипными, так и разнотипными.
Свойства бывают трех видов:
- simple property. поля в той же таблице, что и сам элемент
- custom property. свойства хранящие в дочерней таблице в виде propid, propvalue
- aggregate property. некая функция над полями и связями элемента, возвращающая скалярное значение
Ну да, всякие Озоны регулярно проводят распродажи по таким use case-ам.(Вспоминая форум -а) Другие варианты вообще не взлетают.
Вот простая (и популярная) задача:Могу придумать 100500 задач, которые потребуют использования вендорских расширений сиквеля
3 объекта (отражаемые в таблицы б.д.): Пользователи, Группы, Права.
Каждая отражаемая таблица имеет связь с другой m2m.
До завтрашнего обеда я выложу, как строится ORM и выполняются запросы в Turbogears 2.x.x, т.е. с применением SQLA.ORM (сейчас просто уже спать пора).
1)Найти все группы которые по составу не менее чем на 50% совпадают с данной группой.
2)Группы иерархические, у пользователя есть права на объект если есть права у любой группы в иерархии.
3)Найти самую длинную последовательность дней, такую что каждый день численность группы увеличивалась.
в SQL запрос проще вникать, и с ним проще разрабатывать
o'rly?
как строится ORM и выполняются запросыт.е. будем сравнивать SQLAlchemy запросы с SQL запросами?
дать пользователю возможность с помощью gui настроить вывод в табличной форме набор элементов и их свойств.в СУБД для хранения метаданных используются тоже реляционные таблицы, тут всё замкнуто и хорошо
Элементы могут располагаться как в одной таблице, так и в нескольких, быть как однотипными, так и разнотипными.
Свойства бывают трех видов:
- simple property. поля в той же таблице, что и сам элемент
- custom property. свойства хранящие в дочерней таблице в виде propid, propvalue
- aggregate property. некая функция над полями и связями элемента, возвращающая скалярное значение
o'rly?естественно, поскольку SQL это DSL построенный с нуля, а то что встраивается в ORM-ы это DSL на базе существующего языка L1 (например Python). Очень вероятно, что конструкции языка L1 будут мешать, ограничивая свободу решений, при дизайне языка DSL. Так и происходит практически на всех языках от Haskell/Scala до Python.
Нет, будет показано, как работает orm в Python. В SQL вообще лезть не придется.
Могу придумать 100500 задачНе сомневаюсь. А доки по orm питона почитать можешь? Полагаю, что на презентации YouTube твое ознакомление с ним и закончилось. Так и выходит: одни вешают не лучший пример, другие делают заключение о всем языке/движке/фреймворке.
Отмечу, что в питоне тебя никто не заставляет пользоваться orm, можешь писать прямой понятный SQL запрос. Используй вендорские расширения до упячки.
я о том, какая наша общая цель? Сравнить подход с и без ORM. Для этого нужно иметь примеры кода с и без ORM.
Не сомневаюсь. А доки по orm питона почитать можешь? Полагаю, что на презентации YouTube твое ознакомление с ним и закончилось. Так и выходит: одни вешают не лучший пример, другие делают заключение о всем языке/движке/фреймворке.Этот мой пост не был критикой питона, просто ремарку вставил.
Отмечу, что в питоне тебя никто не заставляет пользоваться orm, можешь писать прямой понятный SQL запрос. Используй вендорские расширения до упячки.
Используй вендорские расширения до упячки.
Не совсем так. SQL запрос я инкапсулирую во вьюху. Из этих вьюх я построю другие вьюхи, и т. д. Таким образом, я получаю сущности, который замкнуты относительно композиции. Питоновские запросы, заключенные внутрь функций, не обладают этим свойством.
Моя цель — показать, в чем удобство ORM в Python. В принципе и без orm могу привести пример. Правда, там результат будет менее объектно-ориентирован.
(сейчас будет простыня, потом несколько примеров удобства)
(сейчас будет простыня, потом несколько примеров удобства)
ОК, ОК. Я, например, в SQL знаю только ключевые запросы. К внутренним функциям ни разу не приходилось обращаться. При питоне вообще не имел необходимости влезать в SQL.
Тут три куска. Каждый кусок — дописывание к предыдущему.
Немного сахара для работы с пользователями.
3 объекта (отражаемые в таблицы б.д.): Пользователи, Группы, Права.
from sqlalchemy.orm import scoped_session, sessionmaker
maker = sessionmaker(autoflush=True, autocommit=False)
DBSession = scoped_session(maker)
from sqlalchemy.ext.declarative import declarative_base
DeclarativeBase = declarative_base()
metadata = DeclarativeBase.metadata
from sqlalchemy.engine import create_engine
engine = create_engine('mysql://admin:localhost/mybase', echo=True)
metadata.bind = engine
from sqlalchemy import Table
from sqlalchemy.types import Unicode, Integer, DateTime
from datetime import datetime
class Group(DeclarativeBase):
__tablename__ = 'group'
id = Column(Integer, autoincrement=True, primary_key=True)
name = Column(Unicode(16), unique=True, nullable=False)
created = Column(DateTime, default=datetime.now)
class User(DeclarativeBase):
__tablename__ = 'user'
id = Column(Integer, autoincrement=True, primary_key=True)
name = Column(Unicode(16), unique=True, nullable=False)
email_address = Column(Unicode(255), unique=True, nullable=False)
_password = Column('password', Unicode(128))
created = Column(DateTime, default=datetime.now)
class Permission(DeclarativeBase):
__tablename__ = 'permission'
id = Column(Integer, autoincrement=True, primary_key=True)
name = Column(Unicode(63), unique=True, nullable=False)
description = Column(Unicode(255))
Каждая отражаемая таблица имеет связь с другой m2m.
from sqlalchemy.orm import scoped_session, sessionmaker, relation # добавлен relation
maker = sessionmaker(autoflush=True, autocommit=False)
DBSession = scoped_session(maker)
from sqlalchemy.ext.declarative import declarative_base
DeclarativeBase = declarative_base()
from sqlalchemy.engine import create_engine
engine = create_engine('mysql://admin:localhost/mybase', echo=True)
metadata.bind = engine
from sqlalchemy import Table, ForeignKey, Column # добавлены ForeignKey, Column
from sqlalchemy.types import Unicode, Integer, DateTime
from datetime import datetime
# Добавлена таблица m2m для пользователей и групп
user_group_table = Table('user_group', metadata,
Column('user_id', Integer, ForeignKey('user.id',
onupdate="CASCADE", ondelete="CASCADE"), primary_key=True),
Column('group_id', Integer, ForeignKey('group.id',
onupdate="CASCADE", ondelete="CASCADE"), primary_key=True)
)
# Добавлена таблица m2m для групп и прав
group_permission_table = Table('group_permission', metadata,
Column('group_id', Integer, ForeignKey('group.id',
onupdate="CASCADE", ondelete="CASCADE"), primary_key=True),
Column('permission_id', Integer, ForeignKey('permission.id',
onupdate="CASCADE", ondelete="CASCADE"), primary_key=True)
)
class Group(DeclarativeBase):
__tablename__ = 'group'
id = Column(Integer, autoincrement=True, primary_key=True)
name = Column(Unicode(16), unique=True, nullable=False)
created = Column(DateTime, default=datetime.now)
users = relation('User', secondary=user_group_table, backref='groups') # Добавлена двустороняя связь
class User(DeclarativeBase):
__tablename__ = 'user'
id = Column(Integer, autoincrement=True, primary_key=True)
name = Column(Unicode(16), unique=True, nullable=False)
email_address = Column(Unicode(255), unique=True, nullable=False)
_password = Column('password', Unicode(128))
created = Column(DateTime, default=datetime.now)
class Permission(DeclarativeBase):
__tablename__ = 'permission'
id = Column(Integer, autoincrement=True, primary_key=True)
name = Column(Unicode(63), unique=True, nullable=False)
description = Column(Unicode(255))
groups = relation(Group, secondary=group_permission_table, backref='permissions') # Добавлена двустороняя связь
Немного сахара для работы с пользователями.
from sqlalchemy.orm import scoped_session, sessionmaker, relation, synonym # добавлен synonym
maker = sessionmaker(autoflush=True, autocommit=False)
DBSession = scoped_session(maker)
from sqlalchemy.ext.declarative import declarative_base
DeclarativeBase = declarative_base()
from sqlalchemy.engine import create_engine
engine = create_engine('mysql://admin:localhost/mybase', echo=True)
metadata.bind = engine
from sqlalchemy import Table, ForeignKey, Column
from sqlalchemy.types import Unicode, Integer, DateTime
import os # добавлен os
from datetime import datetime
from hashlib import sha256 # добавлен sha256
user_group_table = Table('user_group', metadata,
Column('user_id', Integer, ForeignKey('user.id',
onupdate="CASCADE", ondelete="CASCADE"), primary_key=True),
Column('group_id', Integer, ForeignKey('group.id',
onupdate="CASCADE", ondelete="CASCADE"), primary_key=True)
)
group_permission_table = Table('group_permission', metadata,
Column('group_id', Integer, ForeignKey('group.id',
onupdate="CASCADE", ondelete="CASCADE"), primary_key=True),
Column('permission_id', Integer, ForeignKey('permission.id',
onupdate="CASCADE", ondelete="CASCADE"), primary_key=True)
)
class Group(DeclarativeBase):
__tablename__ = 'group'
id = Column(Integer, autoincrement=True, primary_key=True)
name = Column(Unicode(16), unique=True, nullable=False)
created = Column(DateTime, default=datetime.now)
users = relation('User', secondary=user_group_table, backref='groups')
class User(DeclarativeBase):
__tablename__ = 'user'
id = Column(Integer, autoincrement=True, primary_key=True)
name = Column(Unicode(16), unique=True, nullable=False)
email_address = Column(Unicode(255), unique=True, nullable=False)
_password = Column('password', Unicode(128))
created = Column(DateTime, default=datetime.now)
# =====================================
# Сахар
# =====================================
@property
def permissions(self):
perms = set()
for g in self.groups:
perms = perms | set(g.permissions)
return perms
@classmethod
def _hash_password(cls, password):
salt = sha256()
salt.update(os.urandom(60))
hash = sha256()
hash.update(password + salt.heigest())
password = salt.heigest() + hash.heigest()
return password
def _set_password(self, password):
self._password = self._hash_password(password)
def _get_password(self):
return self._password
password = synonym('_password', descriptor=property(_get_password, _set_password))
@classmethod
def by_email_address(cls, email):
return DBSession.query(cls).filter_by(email_address=email).first()
@classmethod
def by_user_name(cls, username):
return DBSession.query(cls).filter_by(name=username).first()
class Permission(DeclarativeBase):
__tablename__ = 'permission'
id = Column(Integer, autoincrement=True, primary_key=True)
name = Column(Unicode(63), unique=True, nullable=False)
description = Column(Unicode(255))
groups = relation(Group, secondary=group_permission_table, backref='permissions')
Схему выше уже можно использовать, как готовый кусок для всех проектов, имеющих авторизацию. Запаковать в свой модуль и дорабатывать в зависимости от требований заказчика.
Как с этим работать...
для начала нужно создать в базе таблицы по схеме.
Далее (предположим, мы всю выше написанную хрень сохранили в mymodule.py)...
Добавление нового пользователя:
Создание новой группы и внесение в нее существующего пользователя, добавление прав группе:
В таблицах m2m записи появятся сами. Обращение к ".users" у группы сразу вернет список объектов пользователей.
Обращение к ".permissions" у пользователя выдаст список прав в зависимости от групп, к которым он принадлежит, и прав, которые есть у этих групп.
Т.е. мы гуляем по объектам через relation, не залезая в базу. Это основное удобство orm в Питоне (точнее в SQLAlchemy).
Как делаются запросы (без прямого обращения к sql), и идет подключение к базе (любой), напишу чуть позже. Там же приведу пример без orm. Заодно попробую изобразить что-нибудь более приличное, чем было написано на презентации YouTube.
Как с этим работать...
для начала нужно создать в базе таблицы по схеме.
meatadata.create_all()
Далее (предположим, мы всю выше написанную хрень сохранили в mymodule.py)...
Добавление нового пользователя:
from mymodule import User, DBSession
import transaction
moo_shu = User()
moo_shu.name = u''
moo_shu.password = u'_Password' #Запишется хэш, спасибо сахару
moo_shu.email_address = 'moo-moo-shu.ru'
DBSession.add(moo_shu)
transaction.commit()
Создание новой группы и внесение в нее существующего пользователя, добавление прав группе:
from mymodule import User, Group, Permission, DBSession
import transaction
# запрашиваем пользователя из базы
moo_shu = User.by_user_name(u'')
# создаем группу, сразу занесем в нее пользователя
usergroup = Group()
usergroup.name = u'Users'
usergroup.users.append(moo_shu)
DBSession.add(usergroup)
# создаем права
readperm = Permission()
readperm.name = u'read'
readperm.description = u'allows to read threads'
readperm.groups.append(usergroup)
DBSession.add(p)
transaction.commit()
В таблицах m2m записи появятся сами. Обращение к ".users" у группы сразу вернет список объектов пользователей.
Обращение к ".permissions" у пользователя выдаст список прав в зависимости от групп, к которым он принадлежит, и прав, которые есть у этих групп.
Т.е. мы гуляем по объектам через relation, не залезая в базу. Это основное удобство orm в Питоне (точнее в SQLAlchemy).
Как делаются запросы (без прямого обращения к sql), и идет подключение к базе (любой), напишу чуть позже. Там же приведу пример без orm. Заодно попробую изобразить что-нибудь более приличное, чем было написано на презентации YouTube.
#Запишется хэш, спасибо сахаруКак ты проверишь пароль пользователя?
ну не знаю, я конечно быдлокодер, но воспринимать linq гораздо проще чем sql-запрос, да ещё и с последующим разбором полученного...
Вопрос не понял. Как я сверю пароль с тем, который уже записан?
Вопрос не понял. Как я сверю пароль с тем, который уже записан?Да.
В моем примере соль содержится в первых 64 знаках.
1) Беру соль из базы.
2) Приставляю ее в высланному на проверку паролю.
3) Хеширую полученную сумму строк.
4) сверяю со следующими 64 знаками записи в базе.
расписать код?
Еще бы я вставил 2 проверки, просто не стал писать в примере:
1) Беру соль из базы.
2) Приставляю ее в высланному на проверку паролю.
3) Хеширую полученную сумму строк.
4) сверяю со следующими 64 знаками записи в базе.
расписать код?
Еще бы я вставил 2 проверки, просто не стал писать в примере:
def _hash_password(cls, password):
# проверить, что пароль -- str, т.к. мы не можем хешировать объект unicode
if isinstance(password, unicode):
password = password.encode('utf-8')
salt = sha256()
salt.update(os.urandom(60))
hash = sha256()
hash.update(password + salt.heigest())
password = salt.heigest() + hash.heigest()
# В конце проверить, что хешированный пароль -- unicode, т.к. этого типа столбец
if not isinstance(password, unicode):
password = password.decode('utf-8')
return password
расписать код?Просто твой сахар выглядит очень странно без кода проверки пароля.
Кроме этого я бы покритиковал за отсутствие юнит тестов, т.к. без них проекты от 100kb кода на python поддерживать очень и очень сложно.
И, как обычно, твой пример из песочницы. В реальном проекте всё перевернётся с ног на голову: путаница в индексах и отношениях, которую не сразу заметно; сложность обновления БД при выпуске новых версий; смесь ORM и простых запросов, т.к. они всё равно потребуются.
Например, интересно как в твоём случае будет выглядеть код, который строит отчёт по правам пользователей и выгружает его в виде таблицы user p1 p2 p3 p4 ... pn? Или как приделать права к пользователю, чтобы они переписывали права соответствующих групп?
Просто твой сахар выглядит очень странно без кода проверки пароля.Ну, не строить же мне тут весь проект сайта.
Просто пример наворотов к объекту. Геттер/сеттер хотел показать, хешер предусмотрел. Валидатор — да, не написал. Что, от этого объяснение orm стало хуже?
интересно как в твоём случае будет выглядеть код, который строит отчёт по правам пользователей и выгружает его в виде таблицы user p1 p2 p3 p4 ... pn?Весь список импортов опущу, чтобы не городить простыню.
Внутри контроллера:
...
@expose('myproject.templates.userperms')
def userperms(self):
userlist = DBSession.query(User).all()
permlist = DBSession.query(Permission).all()
return dict(userlist = userlist, permlist = permlist)
...
Внутри templates/userperms.mak
...
<table>
<thead>
<tr>
<th>Имя пользователя</th>
% for perm in permlist:
<th>${perm.name}</th>
% endfor
</tr>
</thead>
<tbody>
% for user in userlist:
<tr>
<td>${user.name}</td>
% for perm in perms:
% if perm in user.permissions:
<td>+</td>
% else:
<td>-</td>
% endif
% endfor
</tr>
% endfor
</tbody>
<table>
...
Таблица доступна по адресу http://example.com/userperms
Или как приделать права к пользователю, чтобы они переписывали права соответствующих групп?Вунтри контроллера:
...
@expose('myproject.templates.edit_group_permission')
@require(predicates.has_permission('manage_permissions', msg=u'Вы не можете менять права групп.'))
def edit_group_permission(self, group_id):
...#some code of appending/removing permissions in group.permissions list.
Внутри контроллера:Это выгрузка в память?
% for user in userlist:Это O(U * P)?
<tr>
<td>${user.name}</td>
% for perm in perms:
% if perm in user.permissions:
<td>+</td>
% else:
<td>-</td>
% endif
% endfor
</tr>
% endfor
Таблица доступна по адресу http://example.com/userperms
The requested URL /userperms was not found on this server.
Вунтри контроллера:
Вообще ничего не понял, меня интересуют эффективные права пользователя, где часть наследована из группы, а часть добавлена или запрещена у пользователя. При чём это всё должно быть редактируемым.
В таком случае я ничего не понял.
Например, интересно как в твоём случае будет выглядеть код, который строит отчёт по правам пользователей и выгружает его в виде таблицы user p1 p2 p3 p4 ... pn?В каком виде отчет и куда выгружает?
меня интересуют эффективные права пользователя, где часть наследована из группы, а часть добавлена или запрещена у пользователя.В моем примере пользователи получают права исключительно через группы, в которых находятся.
В таком случае я ничего не понял.Выгружать отчёт в память с квадратной алгоритмической сложностью не принято. Отчёт может быть в твоём виде и выгружаться в HTML. Но ты же понимаешь, что в реальности он должен разбиваться на страницы, поддерживать фильтры, сортировку, и ясное дело не грузить в память всех пользователей, которых больше 100500.
В моем примере пользователи получают права исключительно через группы, в которых находятся.То есть замодерировать Вансона из Development нельзя? А в реальном проекте это потребуется.
Речь идёт о том, что примеры из песочницы на коленке всегда красиво выглядят, особенно на питоне. Но в реальной жизни всё будет несколько хуже.
кстати, немного не в тему, но как прекрасны джанговые декораторы:
http://stackoverflow.com/questions/1473543/django-view-funct...
http://stackoverflow.com/questions/1473543/django-view-funct...
Выгружать отчёт в память с квадратной алгоритмической сложностью не принято.еще интересно посмотреть в SQL profiler сколько
Речь идёт о том, что примеры из песочницы на коленке всегда красиво выглядят, особенно на питоне. Но в реальной жизни всё будет несколько хуже.При старте проекта манагеры, понятное дело, предпочтут то, что красиво выглядит в песочнице.
Да тут уже ТЗ формируется.
Да, это не реальный проект, а песочница. И она настрочена исключительно для понимания orm в python. Тебе движок форума нужен? Написанного выше для этого маловато.
То есть замодерировать Вансона из Development нельзя? А в реальном проекте это потребуется.Можно. Только куда Development будем записывать? В пользователей, группы и ли права?
Да, это не реальный проект, а песочница. И она настрочена исключительно для понимания orm в python. Тебе движок форума нужен? Написанного выше для этого маловато.
Запросов там идет прилично. Обращение к каждому объекту — это запрос. Но на этапе старта падений скорости особых нет.
При старте проекта манагеры, понятное дело, предпочтут то, что красиво выглядит в песочнице.Ещё один проект попадёт в 90% не выстреливших. Впрочем, песочницу можно сделать на чём угодно, под любой платформой для этого предостаточно всякого гавна.
Да, это не реальный проект, а песочница. И она настрочена исключительно для понимания orm в python.и на этой песочнице мы увидели, что твой код с orm грузит всю базу в память или/и получаем известную n+1 проблему загрузки.
Запросов там идет прилично.Вот, да. А когда ты работаешь с СУБД через стандартный интерфейс, ты знаешь сколько пойдет запросов к СУБД, в примере выше два три запроса.
Давай пример.
Т.е. мы гуляем по объектам через relation, не залезая в базу. Это основное удобство orm в Питоне (точнее в SQLAlchemy).Короче, нам только что в явном виде продемонстрировали:
Current Java ORMs wrap a high level language (SQL) into a lower level API
A JPA style ORM expose an object model on which user code navigates from one entity to another via relations that are represented as collections. While this approach is adequate for simple cases it can lead to verbose imperative code and excessive round trips to the database ...
http://squeryl.org/introduction.html#squeryl-control-granula...
Давай пример.сначала мы вместе с постановщиком задачи нарисовали бы от руки, что должно быть на экране
Спасибо за пример, помогло составить поверхностное мнение о джанге. Мне рельсы показались несколько более аккуратными. Вот этот код отдает джавой:
from sqlalchemy.ext.declarative import declarative_base
DeclarativeBase = declarative_base()
metadata = DeclarativeBase.metadata
При старте проекта манагеры, понятное дело, предпочтут то, что красиво выглядит в песочнице.А с хуя ли менеджеры смотрят на "красоту" кода? Если взялся отвечать за красоту кода, то будь добр при росте проекта объяснить как поддерживать красоту, а не сваливаться в говно. Менеджеры обычно боятся кода и обращаются с ним как-то неуклюже.
сначала мы вместе с постановщиком задачи нарисовали бы от руки, что должно быть на экране
Таблица user p1 p2 p3 p4 ... pn
Продолжай.
Ещё один проект попадёт в 90% не выстреливших.а если делать сразу уродливо и на джаве, тогда выстрелит?
Таблица user p1 p2 p3 p4 ... pn1. Если пермишенов много, то будет горизонтальная полоса прокрутки, это ок?
Продолжай.
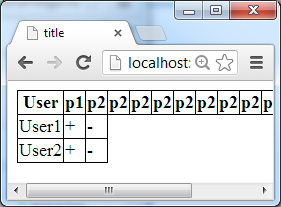
2. Таблица редактируемая?
3. Если пользователь получает пермишен через группу, то как осуществляется редактирование? Например, пользователь имел пермишен, что должно происходить, если убираем у пользователя этот пермишен?
4. Сортировка по любому столбцу?
5. Нужен ли пейджинг?
6. Нужен ли поиск? По имени пользователя?
Нет. Наворотов не нужно. Без сортировки, без поиска, без пейджинга. На первом этапе просто тупая таблица. Горизонтальная полоса — ок. Пользователей — не больше 100, групп — не больше 10, прав — не больше 3 на группу. Просто мне интересен сам код генерации запроса и подстановки ответа в html.
Повторю: не ради холиваров. Просто интересно, как это выглядит на ЯВУ. Сколько времени займет. Как будет составлено минимум запросов.
Повторю: не ради холиваров. Просто интересно, как это выглядит на ЯВУ. Сколько времени займет. Как будет составлено минимум запросов.
к пользователям можно добавлять пермишены напрямую без группы?
Почему спрашиваю, у нас нет, нельзя, так исторически сложилось, не знаю плохо это или хорошо
//ухожу
Почему спрашиваю, у нас нет, нельзя, так исторически сложилось, не знаю плохо это или хорошо
//ухожу
помогло составить поверхностное мнение о джангезато там так красиво выглядит всё!
http://www.sublimereddit.aesptux.com/comments/r/pics/comment...
а если делать сразу уродливо и на джаве, тогда выстрелит?Я же написал: если делать сразу уродливо, тогда вряд ли выстрелит. При чём тут Java?
к пользователям можно добавлять пермишены напрямую без группы?Нет.
У меня тоже так исторически сложилось, что нельзя. Конечно, можно сделать, чтоб можно было, но пока ни разу не требовалось. Вообще не представляю, нафига.
На него как минимум завязаны механизмы сессий и аутентификации.вообще говоря, это неправда, Session/AuthenticationMiddleware подменяется очень просто, можно вообще отвязать аутентификацию от базы в пару десятков строчек, если хочется.
Внутри контроллера:
Html темплейт:
Замечание. Программист везде пишет T000. Замена T000->T*** и генерация T*** происходит автоматически в процессе билда.
public ActionResult Index()
{
var result = Query.Create<T001, T002, T003>(@"
SELECT * FROM [User]
SELECT * FROM Permission
SELECT DISTINCT
UserId,
PermissionId
FROM UserGroup
JOIN GroupPermission ON UserGroup.GroupId = GroupPermission.GroupId", new {}).GetResult();
return View(new {
Users = result.Item1,
Permissions = result.Item2,
UserPermission = result.Item3
}.Duck(Type<T004>._));
}
Html темплейт:
@model T004
...
<table class="myTable">
<thead>
<tr>
<th>User</th>
@foreach (var permission in @Model.Permissions)
{
<th>@permission.Name</th>
}
</tr>
</thead>
<tbody>
@{ var userPermission = Model.UserPermission.ToDictionary(_ => new {_.UserId, _.PermissionId}); }
@foreach (var user in Model.Users)
{
<tr>
<td>@user.Name</td>
@foreach (var permission in @Model.Permissions)
{
if (userPermission.ContainsKey(new {user.UserId, permission.PermissionId}))
{
<td>+</td>
}
else
{
<td>-</td>
}
}
</tr>
}
</tbody>
</table>
Замечание. Программист везде пишет T000. Замена T000->T*** и генерация T*** происходит автоматически в процессе билда.
SELECT * FROM [User]Что это за синтаксис? В первый раз такое вижу.
SELECT * FROM Permission
SELECT DISTINCT
UserId,
PermissionId
FROM UserGroup
JOIN GroupPermission ON UserGroup.GroupId = GroupPermission.GroupId
Я, пока вникаю, выложу, как в sqla.orm работают запросы в бэкграунде.
Открыл среду, решил посмотреть:
Хэши потер для экономии.
Открыл среду, решил посмотреть:
>>> from gisgate.model import DBSession, User
>>> users = DBSession.query(User).all()
22:03:59,157 INFO [sqlalchemy.engine.base.Engine] BEGIN (implicit)
22:03:59,160 INFO [sqlalchemy.engine.base.Engine] SELECT user.password AS user_password, user.id AS user_id, user.name AS user_name, user.email_address AS user_email_address, user.display_name AS user_display_name, user.created AS user_created
FROM user
22:03:59,161 INFO [sqlalchemy.engine.base.Engine] ()
22:03:59,163 DEBUG [sqlalchemy.engine.base.Engine] Col ('user_password', 'user_id', 'user_name', 'user_email_address', 'user_display_name', 'user_created')
22:03:59,164 DEBUG [sqlalchemy.engine.base.Engine] Row (u'44d1*', 1, u'pupkin', u'example.com', u'Vasily Pupkin', u'2013-07-15 19:41:45.395580')
22:03:59,164 DEBUG [sqlalchemy.engine.base.Engine] Row (u'544e*', 2, u'mistrelia', u'example.com', u'Milana Strelkova', u'2013-07-26 23:28:31.408918')
22:03:59,165 DEBUG [sqlalchemy.engine.base.Engine] Row (u'edde*', 3, u'vladimir', u'example.com', u'Vladimir Kalinin', u'2013-08-01 12:16:05.951116')
>>> users[0].permissions
22:04:26,074 INFO [sqlalchemy.engine.base.Engine] SELECT group.id AS group_id, group.name AS group_name, group.display_name AS group_display_name, group.created AS group_created
FROM group, user_group
WHERE ? = user_group.id AND group.id = user_group.id
22:04:26,074 INFO [sqlalchemy.engine.base.Engine] (1,)
22:04:26,075 DEBUG [sqlalchemy.engine.base.Engine] Col ('group_id', 'group_name', 'group_display_name', 'group_created')
22:04:26,075 DEBUG [sqlalchemy.engine.base.Engine] Row (1, u'managers', u'Managers Group', u'2013-05-15 19:41:45.391917')
22:04:26,078 INFO [sqlalchemy.engine.base.Engine] SELECT permission.id AS permission_id, permission.name AS permission_name, permission.description AS permission_description
FROM permission, group_permission
WHERE ? = group_permission.id AND permission.id = group_permission.id
22:04:26,079 INFO [sqlalchemy.engine.base.Engine] (1,)
22:04:26,081 DEBUG [sqlalchemy.engine.base.Engine] Col ('permission_id', 'permission_name', 'permission_description')
22:04:26,082 DEBUG [sqlalchemy.engine.base.Engine] Row (1, u'close_issues', u'Rights to close issues')
22:04:26,082 DEBUG [sqlalchemy.engine.base.Engine] Row (2, u'read_issues', u'Rights to read issues')
set([<Permission: name=read_issues>, <Permission: name=close_issues>])
>>> users[0].groups
[<Group: name=managers>]
>>> users[0].permissions
set([<Permission: name=read_issues>, <Permission: name=close_issues>])
>>> # Второй раз запрашивать не стал.
Хэши потер для экономии.
Что это за синтаксис? В первый раз такое вижу.SQL Server может возвращать несколько result set-ов из запроса или из хранимой процедуры. Вот (но там код не очень аккуратный) http://msdn.microsoft.com/en-us/library/haa3afyz.aspx#sectio...
>>> users[0].permissionsа если выполнить users[1].permissions будут запросы?
29
set([<Permission: name=read_issues>, <Permission: name=close_issues>])
30
>>> # Второй раз запрашивать не стал.
Да, по той же схеме, только уже id указывает (2,) вместо (1,)
Тоже одноразово. То есть при втором обращении запрос не идет.
Так же и с циклом: при запуске первого цикла шлет запросы, второй раз нет.
При удалении объекта (списка users через 'del users') повторный query, логично, шлет запрос, и при первом обращении к каждому permission посылается по запросу. Значит, объекты выгружаются в память.
Отсюда вывод: при запросе страницы память наполняется. Чем больше реляционных данных, тем больше объем. Высвобождается память по окончании рендера.
Тоже одноразово. То есть при втором обращении запрос не идет.
Так же и с циклом: при запуске первого цикла шлет запросы, второй раз нет.
При удалении объекта (списка users через 'del users') повторный query, логично, шлет запрос, и при первом обращении к каждому permission посылается по запросу. Значит, объекты выгружаются в память.
Отсюда вывод: при запросе страницы память наполняется. Чем больше реляционных данных, тем больше объем. Высвобождается память по окончании рендера.
Да, по той же схеме, только уже id указывает (2,) вместо (1,)Это и есть известная N+1 проблема. Когда количество запросов к базе пропорционально количеству данных (строк), это херово. Каждое обращение к базе дорогое удовольствие. У меня все необходимые данные возвращаются за одно обращение к базе.
В принципе количество запросов можно уменьшить, если не пользоваться реляционными переходами. Пример позже. В дороге.
Я тут накидал решение на рельсах:
Миграция (индексы и внешние ключи опущены для простоты)
Модельки:
Контроллер:
Вьюшка:
Как это работает: мы создаем вьюху, в которую выставляем связь между пользователями и пермиссиями. Так как вьюхи и таблицы неразличимы с точки зрения рельс, то они используют ее для загрузки пермиссий пользователя. В результате мы загружаем пользователей и пермиссии одним sql запросом. В принципе, запрос инкапсулированный во вьюхе может быть сколь угодно сложным. Развивая приложение таким образом, мы получим не только ОРМ маппинги, но и слой вьюх, которые морно использовать в запросах для подсчета разной аналитики. Получаем чистое, модульное DRY решение.
PS: подскажите, как код вставлять с подсветкой.
Миграция (индексы и внешние ключи опущены для простоты)
class CreateModel < ActiveRecord::Migration
def change
create_table :users do |t|
t.text :name
t.timestamps
end
create_table :groups do |t|
t.text :name
t.timestamps
end
create_table :permissions do |t|
t.text :name
t.timestamps
end
create_table :groups_users, id: false do |t|
t.integer :group_id
t.integer :user_id
end
create_table :groups_permissions, id: false do |t|
t.integer :group_id
t.integer :permission_id
end
execute <<-HERE
create view v_user_permission as
select gp.permission_id,gu.user_id
from groups_users gu,groups_permissions gp
where gu.group_id = gp.group_id
HERE
end
end
Модельки:
class User < ActiveRecord::Base
validates :name, presence: true
has_and_belongs_to_many :groups
has_and_belongs_to_many :permissions, join_table: 'v_user_permission'
end
class Group < ActiveRecord::Base
validates :name, presence: true
has_and_belongs_to_many :users
has_and_belongs_to_many :permissions
end
class Permission < ActiveRecord::Base
validates :name, presence: true
has_and_belongs_to_many :groups
has_and_belongs_to_many :users, join_table: 'v_user_permission'
end
Контроллер:
class PermissionsController < ApplicationController
def index
@users = User.all.eager_load :permissions
@permissions = Permission.all
end
end
Вьюшка:
<table>
<thead>
<td>User/Permission</td>
<% @permissions.each do |permission| %>
<td><%=permission.name%></td>
<% end %>
</thead>
<tbody>
<% @users.each do |user| %>
<tr>
<td><%=user.name %> </td>
<% @permissions.each do |permission| %>
<% if user.permissions.include? permission %>
<td>+</td>
<% else %>
<td>-</td>
<% end %>
<% end %>
</tr>
<% end %>
</tbody>
</table>
Как это работает: мы создаем вьюху, в которую выставляем связь между пользователями и пермиссиями. Так как вьюхи и таблицы неразличимы с точки зрения рельс, то они используют ее для загрузки пермиссий пользователя. В результате мы загружаем пользователей и пермиссии одним sql запросом. В принципе, запрос инкапсулированный во вьюхе может быть сколь угодно сложным. Развивая приложение таким образом, мы получим не только ОРМ маппинги, но и слой вьюх, которые морно использовать в запросах для подсчета разной аналитики. Получаем чистое, модульное DRY решение.
PS: подскажите, как код вставлять с подсветкой.
не только ОРМ маппингиа зачем нужен такой орм?
PS: подскажите, как код вставлять с подсветкой.я пишу [code=cshrap] .... [/code]
а зачем нужен такой орм?тут объекты — это же источник говна. С таких объектов и начинает разрастаться говно. В базе лежат аккуратненькие кортежи. Сделали запрос к кортежам, получили кортежи, вывели их в html. Зачем тут объекты?
Первый раз за 13 лет занятий программированием слышу мнение, что "ORM это сраное говно, придуманное гомосексуалистами, писать надо без ORM".Есть много вещей, которые представляют из себя УГ. Часто случается, что уродец не только рождается в воспалённом сознании организма, не просто выживает, но и начинает заражать здоровых людей.
Это я такой пещерный, или мнение уж больно нетрадиционное?
В своё время Ломоносова высмеивали за то, что он не признаёт теплород. Пройдёт время, найдётся пассионарная личность, которая в пух и прах разнесёт всё что связано с ORM.
Тебя же сейчас я призываю задуматься:
1. Зачем нужен ORM? Что он даёт лично тебе?
2. Что именно нельзя или сложнее реализовать без ORM?
Если ты посмотришь трезво, то фактически единственный аргумент в пользу ORM любого — возможность подменить одну БД другой "прозрачно". Но я за свои 13 лет ни разу не сталкивался с задачей "подменить mysql на pgsql/oracle". И даже когда требовалась миграция, никакой ORM не спас бы.
Зато ORM ведёт к тому, что ты не можешь работать с БД нормально. Разработчики старались, писали, алгоритмы улучшали. Тут так эффективней, тут — сяк, тут такая фича для запросов. А тебе между тобой и твоей БД становится педрила и говорит — нехрена вот фичи использовать, живи на варианте "SQL для бедных".
Кстати, есть хоть один ORM-щик, который сможет (не подглядывая) привести три причины использовать БД А и три причины использовать БД Б? Уверен, что они _НЕ_ знают тонкостей баз, только упорото "абстрагируются", и считают что это круто.
Тебе же уже сказали: хочешь интересные запросы, хуячь view для каждого. Тогда ты можешь их дебагать и оптимизировать прямо в своей базе, и это будет в миллион раз удобней чем пытаться что-то сделать со своими raw sql queries в коде.
А потом берёшь такой вью и ОРМ автоматически выплёвывает тебе объекты в терминах твоего языка программирования.
Конечно, не все программмисты так делают, и многие пытаются прям в терминах ОРМ чота из базы вытащить нетривиальное. Ну, для этого есть инструмент, бейсбольная бита, приходишь с ней к такому программисту и он срочно начинает хуячить views. А ОРМ по-прежнему удобен для него.
То есть, о чём мы спорим, конкретно? ORM vs raw sql queries, or ORM + views vs ORM or raw SQL queries?
А потом берёшь такой вью и ОРМ автоматически выплёвывает тебе объекты в терминах твоего языка программирования.
Конечно, не все программмисты так делают, и многие пытаются прям в терминах ОРМ чота из базы вытащить нетривиальное. Ну, для этого есть инструмент, бейсбольная бита, приходишь с ней к такому программисту и он срочно начинает хуячить views. А ОРМ по-прежнему удобен для него.
То есть, о чём мы спорим, конкретно? ORM vs raw sql queries, or ORM + views vs ORM or raw SQL queries?
тут объекты — это же источник говна. С таких объектов и начинает разрастаться говно. В базе лежат аккуратненькие кортежи. Сделали запрос к кортежам, получили кортежи, вывели их в html. Зачем тут объекты?Довольно удобно делать формочки для редактирования сущности со вложенными сущностями со вложенными сущностями etc. Врукопашную ты затрахаешься все это говно в базу маршаллить, нужно какое-то декларативное описание этого процесса.
Кроме того, современные js фреймворки делаются разработчиками с rails бэкграундом, поэтому эти фреймворки умеют слать данные на сервер в формате понятном рельсам. В результате можно быстро наклепать CRUD single page app.
Тебя же сейчас я призываю задуматься:Ты, похоже, тоже считаешь, что ORM - это обязательно генерация запросов. А мне нужен маппинг! У меня есть объект Settings с тридцатью пропертями разных (простых) типов и таблица Settings в БД, которая хранит их в 30 колонках. Я не хочу писать 60 присваиваний вручную.
1. Зачем нужен ORM? Что он даёт лично тебе?
2. Что именно нельзя или сложнее реализовать без ORM?
Я срать хотел на генерацию запросов, потому что она прячет от меня реальную сложность моего запроса.
Композиция объекта из нескольких таблиц через relationships удобна тем, что можно за две минуты написать прототип, работающий с БД. Но я понимаю, что, вероятнее всего, этот прототип надо будет переписать с использованием вьюшки, хранимой процедуры или SQL запроса. Это уже будет не две минуты, а двадцать.
Я срать хотел на генерацию запросов, потому что она прячет от меня реальную сложность моего запроса.Так для этого и используют ORM. Чтобы не думать.
Если тебе надо написать 50 однотипных запросов из серии "UPDATE xxx SET field_N = value_N WHERE id = 100500", то ты можешь что написать сам на коленке.
Если я что-то напишу на коленке, то это, очень вероятно, будет ORM
Если я что-то напишу на коленке, то это, очень вероятно, будет ORMЕсли ты вот из-за этой малюсенькой проблемки, а точнее даже не проблемы: "Я не хочу писать 60 присваиваний вручную" — сделаешь ОRM, то ты создашь, себе проблемы на ровном месте. Ну что ж дело твое и твоего заказчика. А потом будешь героически сражаться с тобою же созданными проблемами.
для редактированияу тебя что вьюхи обновляемые?
Если ты вот из-за этой малюсенькой проблемки, а точнее даже не проблемы: "Я не хочу писать 60 присваиваний вручную" — сделаешь ОRM, то ты создашь, себе проблемы на ровном месте.Без, определений этот спор лишен, смысла.
Довольно удобно делать формочки для редактирования сущности со вложенными сущностями со вложенными сущностями etc. Врукопашную ты затрахаешься все это говно в базу маршаллить, нужно какое-то декларативное описание этого процесса.Тебе, наверное, легко будет привести пример, где врукопашную затрахаешься?
 Пока код в этом треде показывает, что код без ORM нисколько не проигрывает коду с ORM (скорее наоборот).
Пока код в этом треде показывает, что код без ORM нисколько не проигрывает коду с ORM (скорее наоборот).Думаю, примера у тебя не получится. Всегда можно сделать ToDictionary/ToLookup и релейшены тогда не нужны. Остаются только плоские объекты аля реляционные кортежи.
Тебе же уже сказали: хочешь интересные запросы, хуячь view для каждого. Тогда ты можешь их дебагать и оптимизировать прямо в своей базе, и это будет в миллион раз удобней чем пытаться что-то сделать со своими raw sql queries в коде.Отлично. Все согласились, что запросы надо писать на SQL. То, что перед SQL запросом вы предлагаете писать CREATE VIEW, это совсем не принципиально, хотите пишите, хотите нет, главное запрос пишется на SQL. (*1) Тем самым, все согласны не использовать жирный кусок большинства известных ORM — подсистему запросов. Это уже хорошо, с одним куском справились.
А потом берёшь такой вью и ОРМ автоматически выплёвывает тебе объекты в терминах твоего языка программирования.
Конечно, не все программмисты так делают, и многие пытаются прям в терминах ОРМ чота из базы вытащить нетривиальное. Ну, для этого есть инструмент, бейсбольная бита, приходишь с ней к такому программисту и он срочно начинает хуячить views. А ОРМ по-прежнему удобен для него.
То есть, о чём мы спорим, конкретно? ORM vs raw sql queries, or ORM + views vs ORM or raw SQL queries?
Переходим к следующему куску. Зачем нужны релейшены между объектами? Почему нельзя просто делать ToDictionary/ToLookup?
(*1) Для обсуждаемой темы — ORM не нужен — это не важно, но всё же интересно, как ваш подход через view и с запретом raw sql queries работает, когда в запросах есть параметры, и когда надо склеивать запрос из кусочков?
Пока код в этом треде показывает, что код без ORM нисколько не проигрывает коду с ORM (скорее наоборот).В случае написания отчета для определенной страницы в плане запросов — да.
Мы тут не разбирали готовые CRUD, которые подцепляют модель и позволяют работать с данными через web-интерфейс.
Плюс о базе: мне приходилось иметь дело с тем, что на этапе создания заказчику "и SQLite сойдет", а потом "Мы передумали, переведи на Postgre". В случае SQLA я переключаю движок (Drizzle, Firebird, Informix, Microsoft SQL Server, MySQL, Oracle, PostgreSQL, SQLite, Sybase), при наличии накопленных нужных данных провожу их перенос. В короткие сроки.
При постоянной смене тз нужно применять изменения оперативно. Когда всё утвердили и сделали, моя работа окончена. Время прихода высокоуровневого программиста.
а когда у тебя 5 разных человек пишет эти 50 даже однотипных запросов на протяжении полугода --- получается цирк с конями.
а если у тебя достаточно большая база и вдруг пришлось изменить ее структуру, то весь этот цирк с конями нужно переписать и протестировать с нуля.
вообще, люди, которые говорят, что писать руками запросы --- это самое лучшее, что было в их жизни, никогда не работали со сложными базами и не поддерживали проекты, которые с ними работают.
про использовать ORM, чтобы не думать --- уж и вообще как-то даже неловко, потому что использование ORMа обычно предполагает (располагает или обязывает даже, иногда) к подробному проектированию перед имплементацией.
а если у тебя достаточно большая база и вдруг пришлось изменить ее структуру, то весь этот цирк с конями нужно переписать и протестировать с нуля.
вообще, люди, которые говорят, что писать руками запросы --- это самое лучшее, что было в их жизни, никогда не работали со сложными базами и не поддерживали проекты, которые с ними работают.
про использовать ORM, чтобы не думать --- уж и вообще как-то даже неловко, потому что использование ORMа обычно предполагает (располагает или обязывает даже, иногда) к подробному проектированию перед имплементацией.
а когда у тебя 5 разных человека пишет эти 50 даже однотипных запросов на протяжении полугода --- получается цирк с конями.ну да, а когда ты посыпаешь их волшебным порошком все сразу меняется
ну, если для человека проектирование и обобщение --- это волшебный порошок, то его надо менять на другого человека, а человеку надо менять профессию, что тут поделаешь.
проектирование и обобщениекак связаны со спором SQL / ORM?
Плюс о базе: мне приходилось иметь дело с тем, что на этапе создания заказчику "и SQLite сойдет", а потом "Мы передумали, переведи на Postgre". В случае SQLA я переключаю движок (Drizzle, Firebird, Informix, Microsoft SQL Server, MySQL, Oracle, PostgreSQL, SQLite, Sybase), при наличии накопленных нужных данных провожу их перенос. В короткие сроки.Про такой самообман Фаулер еще десять лет назад писал:
... to change their database vendor. Despite the fact that few people actually did this, many liked having the option to change vendors without too high a porting cost. ...
ftp://ftp.heanet.ie/mirrors/sourceforge/w/we/webtune/Pattern...
Многим приятно иметь такую опцию, но реально этим пользуются очень немногие.
а если у тебя достаточно большая база и вдруг пришлось изменить ее структуру, то весь этот цирк с конями нужно переписать и протестировать с нуля.но для этого не надо городить ORM, достаточно лишь иметь механизм checking-а запросов
а когда у тебя 5 разных человек пишет эти 50 даже однотипных запросов на протяжении полугода --- получается цирк с конями.если в команде настолько плохая коммуникация, что даже из простого кода получается цирк с конями, то в любом случае хорошего эта команда не напишет
У меня все необходимые данные возвращаются за одно обращение к базе.
Многим приятно иметь такую опцию, но реально этим пользуются очень немногие.
если в команде настолько плохая коммуникация, что даже из простого кода получается цирк с конями, то в любом случае хорошего эта команда не напишетне знаю, откуда ты берешь такой продакшон, в котором и смена движков случается редко, и любые данные можно вынуть одним запросом (sic!), и релационные схемы не нужны.
речь-то не о том, что из простого кода получается цирк с конями, проектов, состоящих только из простого кода, не бывает.
проекты из простого кода, в котором можно себе позволить писать все руками, не заморачиваясь на оверхедах, которые возникнут при тестировании и рефакторинге --- это прототипы из пары человек "с прекрасными коммуникациями", не доживающие до какого-либо релиза, поддержки и развития.
не знаю, откуда ты берешь такой продакшон, в котором и смена движков случается редко, и любые данные можно вынуть одним запросом (sic!), и релационные схемы не нужны.чё? ты что за ерунду мелешь?
Html темплейтНе могу догнать в плане знака @
7 строка
@foreach (var permission in @Model.Permissions)
стоит перед лупом и Model.Permissions
15 строка
@foreach (var user in Model.Users)
стоит только перед лупом
21 строка
if (userPermission.ContainsKey(new {user.UserId, permission.PermissionId}))не стоит перед условием
Я завис...

используя mapping связей и доп. абстрактный уровень, скрывающий как именно свойство хранится в базе
без маппинга связей и без абстракций
ps
первый код легко ревьюится. Второй код охренеешь ревьюить.
var tasks = db.Tasks
.ByUser(illUser)
.Opened()
.Where(_task => _task.PlanDate == null || _task.PlanDate <= DateTime.Now.AddDays(30)))
.ToArray();
foreach (var task in tasks)
{
task.UserId = reserveUser.Id;
task.PlanDate = NewPlanDate(task, tasks);
}
db.Commit();
без маппинга связей и без абстракций
var tasks = db.Tasks.Where(_task => _task.UserId == illUser.Id && _task.StatusId == TaskStatus.Opened &&
(db.TaskProperty
.Where(_tprop => _tprop.Kind == TaskPropertyKind.PlanDate && _tprop.Value <= DateTime.Now.AddDays(30))
.Select(_tprop => _tprop.TaskId)
.Contains(_task.TaskId)
||
!db.TaskProperty
.Where(_tprop => _tprop.Kind == TaskPropertyKind.PlanDate).Select(_tprop => _tprop.TaskId).Contains(_task.TaskId)
).ToArray();
var taskProperties = db.TaskProperties
.Where(_tprop => tasks.Select(_task => _task.Id).Contains(_tprop.TaskId) && _tprop.PropKind == TaskPropertyKind.PlanDate)
.ToDictionary(tprop => tprop.TaskId);
foreach (var task in tasks)
{
task.UserId = reserveUser.Id;
var tprop = taskProperties.Find(task.TaskId);
var newPlanDate = NewPlanDate(task, tprop != null ? tprop.Value : null, tasks, taskProperties);
if (newPlanDate != null)
{
if (tprop != null)
tprop.Value = newPlanDate;
else
db.TaskProperties.Add(new TaskProperty{TaskId = task.TaskId, Kind = TaskPropertyKind.PlanDate, Value = newPlanDate});
}
else if (tprop != null)
db.TaskProperties.Delete(tprop);
}
db.Commit();
ps
первый код легко ревьюится. Второй код охренеешь ревьюить.
а если у тебя достаточно большая база и вдруг пришлось изменить ее структуру, то весь этот цирк с конями нужно переписать и протестировать с нуля.а если у тебя в базе живые объекты с перекрестными ссылками, то типа не надо это всё делать?
Не могу догнать в плане знака @перед Model он не нужный, но движок такое хавает.
вообще знак @ переключает контекст между html и кодом. В первом приближении, если после @ стоит <, то переключается в html, иначе в код. Окончание переключения рассчитывается по балансу вложенных блоков.
Переключения из кода в код, и из html-я в html также допустимы.
7 строкав "@Model.Permissions" знак "@" не нужен, это моя опечатка. Это сработало, поскольку строчка преобразовалось в C# код "@Model.Permissions", а это валидное с точки зрения C# выражение. В C# знак "@" используется для идентификаторов, которые совпадают с ключевыми словами, например, можно ввести переменную с именем "this", вот так @this. Если идентификатор не является ключевым словом, то "@" ни на что не влияет.
1
@foreach (var permission in @Model.Permissions)
С подсветкой, думаю, понятнее:

Тебе, наверное, легко будет привести пример, где врукопашную затрахаешься?Building Complex Forms
Так ясней.
вот ссылку забыл дать inside razor - part 1 - recursive ping-pong
абстрактный уровень, скрывающий как именно свойство хранится в базея правильно понимаю, ты сначала создал себе геморрой в виде хранения key-value в реляционной базе, а потом гордишься навернутым "абстрактным уровнем"?
Building Complex Formsя мало что там понял, попахивает махровым ООП — формочки строят по объектам.
 Пример надо начинать с того, что видит пользователь.
Пример надо начинать с того, что видит пользователь.Пример надо начинать с того, что видит пользователь.Да там понятно, какой хтмл генерится.
Да там понятно, какой хтмл генерится.ну изобрази. В чем проблема изобразить? Можно от руки.
а если у тебя в базе живые объекты с перекрестными ссылками, то типа не надо это всё делать?тогда можно разделить тестирование объектов и функционала, который поверх них строится.
изменения функционала будут менее завязаны на реализацию объектов, отсюда меньше ресурсов на тестирование, рефакторинг и фичекрип.
Да там понятно, какой хтмл генерится.Кстати, я реализовывал редактируемую формучку вот с такими связями:
Entity1->Entity2
Entity2->Entity3
Entity1->Entity4
Где "->" означает связь один ко многим.
Поэтому я в курсе всей внутренней кухни.
У меня было так:
Html генерируется на сервере.
После того как пользователь поредактировал, по форме собирается JSON и отправляется на сервер.
На сервере берем пришедший JSON и данные из базы, производим валидацию, вычисления и другую бизнес-логику, в итоге опять выгружаем html на клиента.
Всё под статической типизацией (JSON в том числе), поэтому "лишние" переливания данных проблем не вызывали, всё прозрачно, естественно и расширяемо на любом уровне.
изменения функционала будут менее завязаны на реализацию объектов, отсюда меньше ресурсов на тестирование, рефакторинг и фичекрипну это же маркетинговое блаблабла
"функционал поверх объектов" - это то, что требует правильного доступа к объектам с сохранением, чтоб все нужные ссылки были живы и работали
если ты "вдруг" меняешь структуру базы, то это же не просто так, это значит что старая база почему-то не справляется; то ли фичи новые нужны, то ли масштабирование не получается
всё это нужно написать и оттестировать, не забыв про миграцию по-живому
"маркетинговое блаблабла" my ass.
не было сказано, что не нужно тестировать, было сказало, что тестировать проще: писать тесты проще, вероятность переиспользовать те же тесты при кардинальном изменении функционала или структуры базы --- выше.
например, потому что разделение удобно с точки зрения написания автотестов.
приложение с ORM проще покрыть вменяемым набором тестов, подменяя базу mock-обжами для проверки функционала и отдельно проверяя правильность сохранения объектов.
не было сказано, что не нужно тестировать, было сказало, что тестировать проще: писать тесты проще, вероятность переиспользовать те же тесты при кардинальном изменении функционала или структуры базы --- выше.
например, потому что разделение удобно с точки зрения написания автотестов.
приложение с ORM проще покрыть вменяемым набором тестов, подменяя базу mock-обжами для проверки функционала и отдельно проверяя правильность сохранения объектов.
подменяя базу mock-обжами для проверки функционалаа как это работает, если бизнес-логика включает запросы (пусть оформленные через view или еще как-то)? как в этом случае без базы?
Скажем, есть грида с пейдингом. Как ты напишешь на объектах без базы тест, который проверяет появление строчки в гриде?
приложение с ORM проще покрыть вменяемым набором тестов, подменяя базу mock-обжами для проверки функционала и отдельно проверяя правильность сохранения объектов.Но зачем, если можно в тестах использовать базу, и сразу тестировать все вместе?
В рельсах, например, так и делают.
приложение с ORM проще покрыть вменяемым набором тестов, подменяя базу mock-обжами для проверки функционалану а какая тут может быть проблема?
даже если у тебя инсерты с апдейтами равномерно размазаны по всему сраному коду, то ты просто в одном месте подменяешь продакшн-базу на тестовую и хоть обтестируйся
а вот например другая проблема, из практики
понадобилось базу мигрировать на кластер
а все эти кластерные решения накладывают определённые ограничения на транзакции - типа например поля (условно) largetext не умеют обновляться атомарно, и ещё на 10-20 пунктов похожих список
используется навороченный фреймворк, все запросы генерятся где-то у него внутре
как ты собираешься проверять, укладывается ли твоё приложение в ограничения?
понадобилось базу мигрировать на кластер
а все эти кластерные решения накладывают определённые ограничения на транзакции - типа например поля (условно) largetext не умеют обновляться атомарно, и ещё на 10-20 пунктов похожих список
используется навороченный фреймворк, все запросы генерятся где-то у него внутре
как ты собираешься проверять, укладывается ли твоё приложение в ограничения?
я правильно понимаю, ты сначала создал себе геморрой в виде хранения key-value в реляционной базе, а потом гордишься навернутым "абстрактным уровнем"?это какие-то странные отмазы из разряда "вы не должны такого хотеть" и "мы предлагаем очень мощное и гибкое решение, поэтому вы можете выбрать любой цвет, главное чтобы он был черным".
ps
база сторонняя и на ней сидит уже готовый код, соответственно, никто не даст менять структуру БД под то, чтобы raw sql был красивый.
вообще, люди, которые говорят, что писать руками запросы --- это самое лучшее, что было в их жизни, никогда не работали со сложными базами и не поддерживали проекты, которые с ними работают.Как раз это говорят те, кто разгрёб порядком чужого говна. Вообще, сложных баз быть не должно, надо упрощать проект и систематизировать существующее.
Часто добавление новой фичи должно стать не новой таблицей, а перестройкой всей структуры целиком. Это дорого, но зато не накапливается технический долг.
это какие-то странные отмазы из разряда "вы не должны такого хотеть" и "мы предлагаем очень мощное и гибкое решение, поэтому вы можете выбрать любой цвет, главное чтобы он был черным".Не, не то. Просто для меня твой пример не очень интересен. Известная и обсосанная архитектурная ошибка там присутствует. Мои решения может и в такой ситуации хорошо отработают, но я не могу тратить время на разбор таких примеров.
вот и получается, что raw sql подходит только для мелких прототипных проектов, когда еще все красиво.
а с orm-ом удобнее в реальных больших работающих проектах, для которых норма, что большая часть кода является страшненькой, но работающей.
и смысл orm-а как раз, что он поверх непонятной фигни сделать вполне вменяемый и удобный интерфейс.
ps
ты на контрактах сидишь? или делаете какую-то свою систему?
а с orm-ом удобнее в реальных больших работающих проектах, для которых норма, что большая часть кода является страшненькой, но работающей.
и смысл orm-а как раз, что он поверх непонятной фигни сделать вполне вменяемый и удобный интерфейс.
ps
ты на контрактах сидишь? или делаете какую-то свою систему?
вот и получается, что raw sql подходит только для мелких прототипных проектов, когда еще все красиво.гыы лол, твое "получается" не соответствует смыслу этого слова в русском языке
а с orm-ом удобнее в реальных больших работающих проектах, для которых норма, что большая часть кода является страшненькой, но работающей.
и смысл orm-а как раз, что он поверх непонятной фигни сделать вполне вменяемый и удобный интерфейс.
ты на контрактах сидишь? или делаете какую-то свою систему?я сижу на зарплате, заказчики у нас крупные транснациональные компании
А у нас (у меня, конечно, имеется в виду) ИП и ЧП. Вот и основной ответ. Кому кто по карману.
заказчики у нас крупные транснациональные компаниивы для них прототипы шлепаете? или продаете свою развивающуюся систему?
Есть развивающиеся системы. Иногда перед заключением контракта они хотят увидеть часть своих данных уже в системе, это типа прототипа. Короче, есть разное, я бы даже не стал такую классификацию производить.
Скажем, есть грида с пейдингом. Как ты напишешь на объектах без базы тест, который проверяет появление строчки в гриде?я мб че-нить не понимаю, но сложности в этом вроде же нет, мы решали такую проблему тестом контроллера, с фейковой моделью, джаверы пошли дальше они еще и вью умудрялись тестить. но у нас гуй был рукописный ибо хендлов в винде не хватало для приложения =)
или вы юзаете говноконтролы от мелкомягких ?
не, тут еще до UI-я, хотя бы источник данных протестировать
хотя бы источник данных протестироватьу нас это проверяли функциональные тесты, была дырка на выход(где сторили что источник отдал) и эмулятор на вход, еще вход на нескольких узлах был и тест периодически узлы клал по очереди либо оба и смотрел в конце все ли он получил целостность апдейты итд. основные сервисы, которые имели такие тесты, без сбоя стояли по 2-3 года ну и рефакторить любой кусок их было проще, закрытыми глазами не боясь, что либо сломать
SQL база одна? Если нет, то какова схема распределения данных по базам?
база одна была. но мы ее никогда не тестили ибо то не интересно так как были более интересные источники данных, тем более назначение базы было туда только писать в процессе работы и зачитывать кеш на старте сервиса. основное правило как щас помню, база данных это медленно, кто не согласен в лес
назначение базы было туда только писать в процессе работы и зачитывать кеш на старте сервисаwrite only база это прикольно
это не прикольно, это в быстрых финансах необходимо, мы меряли чтение базы на соседнем сервере только tcp соединение 300 мс жрет. а так спокойненько пропатчил кеш внутренний и отправил в очередь на запись и все счастливы + еще масштабируемость скажем есть у тебя 70 тысяч финансовых инструментов, делишь их на 5 серверов например по 14 тыщ по любому признаку, каждый читает свой кэш и пишет в свою зону, блокировок базы нет и все счастливы
мы меряли чтение базы на соседнем сервере только tcp соединение 300 мс жрет.лол
, это открытие конекшена первый раз, потом конекшены беруться из пулаэто да но такой подход был все равно оправдан, там же еще всякое говно лезит, скажем если множество запросов то экзекьшен план 90 мс строится ну итд.
я как раз помню писал подобие орм для одной штуки типа свои датасеты только без сохранение всякого левого говна и превдварительной аллокацией(как раз таки кеш) и в построении скля записи шарахнул где-то автоинкремент в синтаксисе столько выслушал в свой адрес так как получили не хилую просадку всей очереди записи.
но это все не интересно самое интересное во всей этой штуки - это время старта сервиса, скажем когда обе ноды ложатся, когда одна из двух переключение занимало 9 секунд. но у нас фолттолеранс был на тибке построен и там факап возникал иногда когда две ноды между собой связь теряли становились двумя мастерами, правда было один раз за 3 года, но был пиздец
я как раз помню писал подобие орм для одной штуки типа свои датасеты только без сохранение всякого левого говна и превдварительной аллокацией(как раз таки кеш) и в построении скля записи шарахнул где-то автоинкремент в синтаксисе столько выслушал в свой адрес так как получили не хилую просадку всей очереди записи.
но это все не интересно самое интересное во всей этой штуки - это время старта сервиса, скажем когда обе ноды ложатся, когда одна из двух переключение занимало 9 секунд. но у нас фолттолеранс был на тибке построен и там факап возникал иногда когда две ноды между собой связь теряли становились двумя мастерами, правда было один раз за 3 года, но был пиздец
это да но такой подход был все равно оправдан, там же еще всякое говно лезит, скажем если множество запросов то экзекьшен план 90 мс строится ну итд.Опять лол
, в MSSQL/Oracle/DB2 планы кешируются.
в построении скля записи шарахнул где-то автоинкремент в синтаксисе столько выслушал в свой адрес так как получили не хилую просадку всей очереди записи.
ну тк, это всем известно. Надо либо guid-ы использовать, либо int-ы брать отдельной короткой транзакцией.
Опять лол , в MSSQL/Oracle/DB2 планы кешируются.сам ты лол, ты блять читать не умеешь - это я уже давно заметил, ты всегда видешь то что хочешь видеть
>>множество запросов
это те у кого синтаксис разный
сам ты лол, ты блять читать не умеешь - это я уже давно заметил, ты всегда видешь то что хочешь видетья вижу то, что написано, ты пишешь, что план строится 90 мс. План строится одни раз, потом достается из кеша. У вас проблемы в выполнении запроса первый раз? Ну тк можно прогревать кеш планов. (*1)
>>множество запросов
это те у кого синтаксис разный
В блоге одного консультанта читал, что он столкнулся с системой, где кеш планов был настолько огромным (десятки гигов), что достать план из кеша стало дорого, но там не грамотно генерировались запросы. У вас, что кеш планов запросов получался огромным?
(*1) По идеи, в Controllable Query это сделать крайне просто — выполнять CheckAllQuery при старте приложения. Надо попробовать и посмотреть.
В принципе количество запросов можно уменьшить, если не пользоваться реляционными переходами.Внутри контроллера:
...
@expose('myproject.templates.userperms')
def userperms(self):
user_group = metadata.tables['user_group']
group_permission = metadata.tables['group_permission']
user_permission = DBSession.query(user_group.c.user_id, group_permission.c.permission_id)
.filter(user_group.c.group_id == group_permission.c.group_id)
.all()
u_perm_dict = {}
for u_id, perm_id in user_permission:
if u_id in u_perm_dict: u_perm_dict[u_id].append(perm_id)
else: u_perm_dict[u_id] = [perm_id]
userlist = DBSession.query(User).all()
permlist = DBSession.query(Permission).all()
return dict(userlist = userlist, permlist = permlist, userpermdict = u_perm_dict)
...
Внутри templates/userperms.mak
...
<table>
<thead>
<tr>
<th>Имя пользователя</th>
% for perm in permlist:
<th>${perm.name}</th>
% endfor
</tr>
</thead>
<tbody>
% for user in userlist:
<tr>
<td>${user.name}</td>
% if user.id in userpermdict:
% for perm in permlist:
<td>${('-','+')[ perm.id in userpermdict[user.id] ]}</td>
% endfor
% else:
% for perm in permlist:
<td>-</td>
% endfor
% endif
</tr>
% endfor
</tbody>
<table>
...
Запросы в среде:
>>> from gisgate.model import DBSession, User, Permission, metadata
>>> user_group = metadata.tables['user_group']
>>> group_permission = metadata.tables['group_permission']
>>> user_permission = DBSession.query(user_group.c.user_id, group_permission.c.permission_id).filter(user_group.c.group_id==group_permission.c.group_id).all()
14:30:15,466 INFO [sqlalchemy.engine.base.Engine] BEGIN (implicit)
14:30:15,466 INFO [sqlalchemy.engine.base.Engine] SELECT user_group.user_id AS user_group_user_id, group_permission.permission_id AS group_permission_permission_id
FROM user_group, group_permission
WHERE user_group.group_id = group_permission.group_id
14:30:15,467 INFO [sqlalchemy.engine.base.Engine] ()
>>> userlist = DBSession.query(User).all()
14:39:17,519 INFO [sqlalchemy.engine.base.Engine] SELECT user.password AS user_password, user.id AS user_id, user.user_name AS user_user_name, user.email_address AS user_email_address, user.display_name AS user_display_name, user.created AS user_created
FROM user
14:39:17,519 INFO [sqlalchemy.engine.base.Engine] ()
>>> permlist = DBSession.query(Permission).all()
14:39:34,877 INFO [sqlalchemy.engine.base.Engine] SELECT permission.id AS permission_id, permission.permission_name AS permission_permission_name, permission.description AS permission_description
FROM permission
14:39:34,877 INFO [sqlalchemy.engine.base.Engine] ()
>>>
Выходит 3 запроса.
У вас, что кеш планов запросов получался огромным?я про чтение не говорю.
даже на запись было неприятно порой, участвовало около 11 сущностей от 70 до 120 полей в каждой, валит поток с фида скажем надо поменять одно поле в какой-нить сущности или 5 полей в трех сущностях, ну соответственно на каждую комбинацию и строилось все заново. но как показывала практика все равно не стандарта на обшем фоне было меньше поэтому не заморачивались, построили база кешанула план, ждем повезет или нет в дальнейшем, кстати не стандартный поток как раз таки видели по времени записи когда как раз таки скорость просаживалась на запись
я нафакапил тогда в том что строил запрос insert blabla() values (@vvvv1_1, @vvvv1_2)
инкрементил @vvvv{incr} mssql для каждого строил экзекьюшен план, причем {incr} какой-то глобальный был

по поводу айдишников и гуидов, мы делали немножко не так:
юзали increment bigint
у нас был прогноз в среднем в день валится 200к записей (в каждой участвует от 1 до 11), кэш делаем с запасом в 30-50 процентов, с коэффициентом на поправку средней связи когда один ко многим
и заказываем у таблиц id в интервале lastid+прогнозируемое кол-во, на старте сервиса, а на завершении не используемые отдавали обратно, если в процессе работы id кончились поток данных больше стал, то шли в базу и заказывали еще
джаверы делали еще круче их системы работали по такому же принципу(точнее мы у них учились как правильно писать такие вещи), тока они еще перед каждым релизом проверяли работу в 2 раза увеличивая поток на тестовых данных если сервис шуршал, то шла отбивка что его трогать не надо.
результатом было следующее когда в лондоне шмальнули терракты в 2004 или каком-то там году, одна из немногих площадок, которая выстояла была как раз таки джаверская поделка, бонусы для девелоперов по результатам года впечатляли
ибо денег народ поднял до фига.Ну тк можно прогревать кеш планов. (*1)не этим мы не заморачивались, хватало и так
кстати прогрев будет елси делать на откате транзакции в mssql? Ты не проверял он план будет оставлять в кеше ?
один фиг когда вся штука работает на write only это выигрыш дает колоссальный ибо из базы читаем один раз
<td>${user.name}</td>а может лучше for сделать внешний?
% if user.id in userpermdict:
% for perm in permlist:
<td>${('-','+')[ perm.id in userpermdict[user.id] ]}</td>
% endfor
% else:
% for perm in permlist:
<td>-</td>
% endfor
% endif
<td>${user.name}</td>
% for perm in permlist:
% if user.id in userpermdict: && perm.id in userpermdict[user.id]
<td>+</td>
% else:
<td>-</td>
% endfor
% endifИли если уж так хочется экономить на спичках, то
<td>${user.name}</td>
% var userInDic = user.id in userpermdict:
% for perm in permlist:
% if userInDic && perm.id in userpermdict[user.id]
<td>+</td>
% else:
<td>-</td>
% endfor
% endifif (user.id in userpermdict) & (perm.id in userpermdict[user.id]):
Если id пользователя нет в словаре, выдаст KeyError из-за второго условия. Поэтому либо "try", либо в два "if"-а.
<% userInDic = user.id in userpermdict %>
% for perm in permlist:
% if userInDic & (perm.id in userpermdict[user.id])
<td>+</td>
% else:
<td>-</td>
% endif
% endfor
Да, вариант. Или:
<% userInDic = user.id in userpermdict %>
% for perm in permlist:
<td>${('-','+')[userInDic & (perm.id in userpermdict[user.id])]}</td>
% endfor
Циклы я разделил из соображения, что при одном условии будет цикл с условием, при втором — просто цикл. Плюс во втором условии сперва думал написать
${['<td>-</td>' for perm in permlist]} , но потом решил не извращаться, чтобы не взрывать мозг тем, кто будет читать.надо поменять одно поле в какой-нить сущности или 5 полейа вы сравнивали подходы всегда апдейтить все поля или часть полей? Тут пишут, что выигрыш от части полей, скорее всего, не получишь. Тем более план генерируется долго. http://stackoverflow.com/a/8683481
надо поменять одно поле в какой-нить сущности или 5 полей в трех сущностях
Что ли условия в клаузе where разные UPDATE WHERE condition? А почему разных condition-ов так много?
Пока смахивает на какой-то гон.
Что ли условия в клаузе where разные UPDATE WHERE condition? А почему разных condition-ов так много?where clause всегда одинаковое where PK=value у всех записей
Пока смахивает на какой-то гон.
потому что фид(дырка в биржу) выплевывает данные которые поменялись(наверное это не надо объяснять почему так), за раз может прийти несколько полей к разным сущностям, мб я вопроса не понял. все поля не апдейтили update работал только на изменения тех что пришли.
но помимо update есть еще и insert а там за раз тоже количество полей может отличаться, что отправляем на вставку
UPD: нет все никогда не апдейтили и не вставляли все. не помню почему, мб и сравнивали
Если id пользователя нет в словаре, выдаст KeyError из-за второго условия. Поэтому либо "try", либо в два "if"-а.В Python надо использовать "and" вместо && http://stackoverflow.com/a/2485471
там же шаблон джанговский у него легко синтаксис расширен может быть
ну должен же быть логический оператор, которые не выполняет второе условие, если результат известен по первому.
а я понял твой вопрос
вообщем атомарность обращения к записи в базу могло содержать
update entity0
insert entity1
insert entity2
или
update entity0
update entity1
insert entity2
ну итд
отсюда и множество планов возникало
вообщем атомарность обращения к записи в базу могло содержать
update entity0
insert entity1
insert entity2
или
update entity0
update entity1
insert entity2
ну итд
отсюда и множество планов возникало
Верно.
and не пойдет на следующее условие, если текущее дало ложь, ничего, пустую строку или ноль.
or не пойдет на следующее условие, если текущее дало истину, непустую строку или число больше нуля.
В общем оптимизированный перл
and не пойдет на следующее условие, если текущее дало ложь, ничего, пустую строку или ноль.
or не пойдет на следующее условие, если текущее дало истину, непустую строку или число больше нуля.
В общем оптимизированный перл
if user.id in userpermdict and perm.id in userpermdict[user.id]:действующий. И вроде даже при текущем состоянии безопасный.
вообщем атомарность обращения к записи в базу могло содержатьВ кеш попадают планы отдельных операции update/insert. Так что, ты гонишь.
update entity0
insert entity1
insert entity2
или
update entity0
update entity1
insert entity2
ну итд
отсюда и множество планов возникало
Условия на разные поля не отменялось. Но суть не в этом один фиг все это говно и не от мира сего. И этим точно не надо заниматься
Но суть не в этом один фиг все это говно и не от мира сего. И этим точно не надо заниматьсяага тратить 90мс каждый раз на генерацию плана это от мира сего
u_perm_dict = {}а в Python нельзя это декларативность записать, подобно вот этому:
for u_id, perm_id in user_permission:
if u_id in u_perm_dict: u_perm_dict[u_id].append(perm_id)
else: u_perm_dict[u_id] = [perm_id]
user_permission.GroupBy(_ => _.UserId)
.ToDictionary(g => g.Key, g => g.ToDictionary(_ => _.PermissionId));
Кстати, случайно натолкнулся, вроде неплохой обзор сравнения Python и C# http://www.quora.com/Python-programming-language-1/How-does-...
20 минут втыкал в этот хак. Так и не понял... Завтра полный кусок перечитаю.
Можно, конечно, выпендриться тяжелой для чтения строкой:
Можно, конечно, выпендриться тяжелой для чтения строкой:
[eval(('u_perm_dict.update({%s:[%s]})', 'u_perm_dict[%s].append(%s)')[uid in u_perm_dict]%(uid, pid)) for uid, pid in user_permission]В финале максимальное сокращение:
Что уменьшает код на 9 строк. Но это трындец не читаемо...
...
@expose('myproject.templates.userperms')
def userperms(self):
d = {}
out = (eval(('d.update({%s:[%s]})', 'd[%s].append(%s)')[uid in d]%(uid, pid)) for uid, pid in DBSession.query(metadata.tables['user_group'].c.user_id, metadata.tables['group_permission'].c.permission_id).filter(metadata.tables['user_group'].c.group_id == metadata.tables['group_permission'].c.group_id).all())
return dict(userlist = DBSession.query(User).all(), permlist = DBSession.query(Permission).all(), userpermdict = d)
...
Что уменьшает код на 9 строк. Но это трындец не читаемо...
20 минут втыкал в этот хак. Так и не понял... Завтра полный кусок перечитаю.Там надо знать как работают два метода GroupBy и ToDictionary.
Метод ToDictionary из коллекции IEnumerable делает Dictionary, в аргументах указываем как из элемента коллекции сделать ключ и как сделать значение:
public static Dictionary<TKey, TElement> ToDictionary<TSource, TKey, TElement>(this IEnumerable<TSource> source, Func<TSource, TKey> keySelector, Func<TSource, TElement> elementSelector)
{
...
}
//метод для случая, если не указан elementSelector, подставляется "_ => _"
public static Dictionary<TKey, TSource> ToDictionary<TSource, TKey>(this IEnumerable<TSource> source, Func<TSource, TKey> keySelector)
{
return ToDictionary(source, keySelector, _ => _);
}
Метод GroupBy из коллекции IEnumerable делает коллекцию IEnumerable<IGrouping>, в аргументе указывает по какому критерию группировать. IGrouping сама является коллекцией и у нее еще есть Кеу свойство:
public static IEnumerable<IGrouping<TKey, TSource>> GroupBy<TSource, TKey>(this IEnumerable<TSource> source, Func<TSource, TKey> keySelector)
{
...
}
public interface IGrouping<out TKey, out TElement> : IEnumerable<TElement>
{
TKey Key { get; }
}
Этих знаний уже достаточно, чтобы легко читать тот код. А знания эти можно почерпнуть, посмотрев методы прям из Visual Studio.
Что уменьшает код на 9 строк. Но это трындец не читаемо...Дело не в уменьшении строк, а как раз в удобстве чтения, поскольку выкидывается пошаговая логика foreach-и, if-ы, присвоения и т.д., остается только декларация того, что нам надо сделать.
Получаем чистое, модульное DRY решение.
The DRY principle is stated as "Every piece of knowledge must have a single, unambiguous, authoritative representation within a system."
Тест на сухость. Можешь запостить diff файлов с кодом, когда меняем название сущности Group на Batch?
Я еще не говорю о том, чтобы разделить сущность на две.
Модельки:зачем эта строчка?
....
has_and_belongs_to_many :users, join_table: 'v_user_permission'
Она же не используется. Вот от такого и нарастает говно — строим модельки, которые не используются, и не нужны.
если хочется ходить по связям, то можно и так переписать:
var result = Query.Create<T001, T002, T003>(@"
SELECT * FROM [User]
SELECT * FROM Permission
SELECT DISTINCT
UserId,
PermissionId
FROM UserGroup
JOIN GroupPermission ON UserGroup.GroupId = GroupPermission.GroupId", new {}).GetResult();
var userPermission = result.Item3.ToLookup(_ => _.UserId);
return View(new {
Users = result.Item1.Select(user => new {
user,
Permissions = userPermission[user.UserId].ToDictionary(_ => _.PermissionId)
}.Impl()._<T005>()),
Permissions = result.Item2
}.Impl()._<T004>());
}
<table class="myTable">
<thead>
<tr>
<th>User</th>
@foreach (var permission in Model.Permissions)
{
<th>@permission.Name</th>
}
</tr>
</thead>
<tbody>
@foreach (var userInfo in Model.Users)
{
<tr>
<td>@userInfo.user.Name</td>
@foreach (var permission in Model.Permissions)
{
if (userInfo.Permissions.ContainsKey(permission.PermissionId))
{
<td>+</td>
}
else
{
<td>-</td>
}
}
</tr>
}
</tbody>
</table>
Причина всех этих копошений вокруг орм - убогий интерфейс доступа, встроенный в существующие РСУБД. Дело в том, что все имеющиеся движки РСУБД родом из 80-х, когда для пользовательского интерфейса имелись только убогие текстовые терминалы, и для отображения вложенных списков просто не было места. Прошло 30 лет, но API не изменился. Чтобы вернуть сущность со списком вложенных сущностей, приходится плющить данные, ломая их структуру, потом героически восстанавливать эту структуру обратно, в результате для простейшей задачи надо многократно писать запутанный говнокод. Если бы разработчики СУБД интересовались потребностями прикладных программистов, то давно встроили бы что-то типа оракловских cursor expressions. В постгресе года три назад сделали возможность возвращать json, но на практике это неюзабельно из-за жутко избыточного ситакисиса. Исправлять это никто не собирается, потому что придется вносить изменения в парсер, а неприкосновенность парсера с точки зрения разработчиков постгреса неизмеримо важнее удобства жалкого быдлокодера.
Передача данных из приложения в РСУБД - тоже жутко неудобна, попробуйте передать в оракл массив таплов с именованными полями, и вы поймете о чем я.
Передача данных из приложения в РСУБД - тоже жутко неудобна, попробуйте передать в оракл массив таплов с именованными полями, и вы поймете о чем я.
Что-то похожее, кстати, произошло с перлом, в котором тоже сначала нельзя было сделать список элементом хэша. Потом возможность добавили, но получилось все равнослегка через жопу.
возвращать jsonSQL статически типизированный, поэтому чистый json это не тру, разработать на его основе что-то нормальное, возможно да.
Потом, SQL замкнут относительно операций, выход можно подать на вход. Графы типа json-а уже сильно далеко от реляционной идеологии.
Реляционка благополучно пережила ОО базы. Разрабатывались целые ООСУБД, а не то что парсеры, создавались целые компании, и все они канули в лету. А реляционка живет и здравствует.
Сейчас бум NoSQL, в итоге, думаю, победят NewSQL (реализации SQL под распределенную инфраструктуру).
Короче, прикладным программистам надо принять реляционную модель, а не хотеть не зная чего.
потом героически восстанавливать эту структуру обратно, в результате для простейшей задачи надо многократно писать запутанный говнокод.В языках, где нет аналогов ToDictionary/ToLookup/т.п., да, запутанный код, там, где есть, код прозрачный. Проблем ни с написание, ни с развитием его нет.
В языка, где нет аналогов ToDictionary/ToLookup/т.п., да, запутанный код, там, где есть, код прозрачный. Проблем ни с написание, ни с развитием его нет.Там можно еще кое-что оптимизировать (для сухости), введя специальный синтаксис в язык, но уже сейчас это настолько хорошо, что выигрыш будет небольшой. Уже сейчас достаточно хорошо, есть посерьезнее проблемы в девелопменте.
В языках, где нет аналогов ToDictionary/ToLookup/т.п., да, запутанный код, там, где есть, код прозрачный. Проблем ни с написание, ни с развитием его нет.В оракле можно писать что-то типа
select
name,
cursor(select name, id from permissions where permisions.id = users.permission_id)
as permissions
from users
Намного удобнее, чем всякие ToDictionary, я не понимаю, о чем тут спорить.
Вообще, любой код, который делает sql запросы к базе - говно по определению, независимо от того, ОРМ это или нет. Приложение должно работать с базой через слой хранимых процедур, по одной на каждую транзакцию. К сожалению, джава архитекторы долго делали негативный пиар хранимым процедурам, и теперь трудно убедить кого-либо их использовать. Приходится выбирать между двумя плохими вариантами - ОРМом и sql запросами, которые делаются напрямую из кода.
кроме проблемы доставания из базы, есть еще проблема обновления этих релейшенов(*1). В реляционной модели я просто записываю id и всё. Следующий раз сделаю заново ToDictionary, и не нужно мне париться о релейшенах.
(*1) меня слегка передергивает, когда эту хрень называю релейшеном. Релейшеном называется другое в реляционной модели. А для этой хрени даже правильного названия нет.
(*1) меня слегка передергивает, когда эту хрень называю релейшеном. Релейшеном называется другое в реляционной модели. А для этой хрени даже правильного названия нет.
релационные схемы не нужны.Вопрос. Ты знаешь что означает слово relation в названии "реляционная модель (relational model)"?
Приложение должно работать с базой через слой хранимых процедур, по одной на каждую транзакцию.Вот тебе пример: есть у нас в базе у юзеров деньги и какие-то разные ресурсы. Ну и пусть есть какая-то типа биржа, где ставятся заявки на покупку-продажу ресурсов. Тогда процедура постановки заявки (транзакция) будет включать в себя:
- проверку того, что юзеру позволено ставить заявки вообще, что их не слишком много и т.д.
- проверку того, что юзеру позволено ставить заявки на этот конкретный ресурс
- блокировку ресурсов/денег юзера, используемых для поддержания заявки
- добавление заявки в таблицу
- пока есть заявки с пересекающимися ценами (заявка на покупку по цене X, заявка на продажу по цене Y, X>=Y), для каждой такой пары заявок надо провести сделку:
- - записать во всевозможные логи информацию о сделке
- - физически перевести деньги и ресурсы
- - удалить или модифицировать заявки
- - снять блокировку с ресурсов, которые использовались для поддержания заявки
Если все это делать одной хранимой процедурой, как ты рекомендуешь, то получится, что вся бизнес-логика твоей системы будет записана в SQL-коде хранимых процедур. А это, как я считаю, очень плохо, потому что SQL - далеко не самый лучший язык для описания бизнес-логики.
Добавлю. Хранимки можно писать и на C#-е. Поэтому разница лишь в том, где выполняется этот код. Обращение к данным будет через тот же SQL. А где выполнять C# код на app сервере или в БД это отдельный вопрос. Т.е. для меня утверждение тоже выглядит странным.
Вот тебе пример: есть у нас в базе у юзеров деньги и какие-то разные ресурсы. Ну и пусть есть какая-то типа биржа, где ставятся заявки на покупку-продажу ресурсов. Тогда процедура постановки заявки (транзакция) будет включать в себя:Ты как раз описал отличный пример, когда хранимки рулят.
- проверку того, что юзеру позволено ставить заявки вообще, что их не слишком много и т.д.
- проверку того, что юзеру позволено ставить заявки на этот конкретный ресурс
- блокировку ресурсов/денег юзера, используемых для поддержания заявки
- добавление заявки в таблицу
- пока есть заявки с пересекающимися ценами (заявка на покупку по цене X, заявка на продажу по цене Y, X>=Y), для каждой такой пары заявок надо провести сделку:
- - записать во всевозможные логи информацию о сделке
- - физически перевести деньги и ресурсы
- - удалить или модифицировать заявки
- - снять блокировку с ресурсов, которые использовались для поддержания заявки
Если все это делать одной хранимой процедурой, как ты рекомендуешь, то получится, что вся бизнес-логика твоей системы будет записана в SQL-коде хранимых процедур. А это, как я считаю, очень плохо, потому что SQL - далеко не самый лучший язык для описания бизнес-логики.
SQL это вообще не язык программирования, хранимки пишутся на plsql (это в оракле). Когда ты делаешь sql запросы из general purpose языка, ты фактически делаешь eval одного языка из другого. Это уродливо и возникают проблемы с конвертацией параметров сложных типов (массивы, рекорды, хэши). Plsql и sql интегрированы на уровне парсеров и систем типов, плотность интеграции близка к той что между C# и LINQ.
SQL статически типизированный, поэтому чистый json это не тру, разработать на его основе что-то нормальное, возможно да.JSON нужен для отдачи клиенту, внутри конечно храним реляционно. Типы же у нас не пересекают границы процессов, так что никакую статическую типизацию нельзя сделать.
code:Против
select
name,
cursor(select name, id from permissions where permisions.id = users.permission_id)
as permissions
from users
...
var userPermission = user.permissions;
SELECT Name, PermissionId FROM User
SELECT Id, Name FROM Permission
...
var permissions = result.Item2.ToDictionary(_ => _.Id);
...
var userPermission = permissions[user.PermissionId];
Твой вариант несколько удобнее, да, но, где тут МНОГО удобства я не вижу. И то, что разработчики СУБД забили на такое незначительное удобство, вполне естественно.
Типы же у нас не пересекают границы процессов, так что никакую статическую типизацию нельзя сделать.f# может доставать типы прям из базы f# type providers
Да и старый дедовский метод кодогенерации тоже подходит. Если, как ты говоришь, обложиться хранимыми процедурами, то для вызовов хранимок можно нагенерить вполне себе типизированные методы доступа. База может рассказать о типе аргументов и о типе результата.
Plsql и sql интегрированы на уровне парсеров и систем типовкогда я изучал pl/sql, там были другие типы, не совпадающие с теми, что хранятся в базе
что-то поменялось?
ты фактически делаешь eval одного языка из другого. Это уродливоЧто в этом уродливого? Красивый синтаксис делается через решение аля Razor ping-pong. Что еще? Статической типизации хочется?
когда я изучал pl/sql, там были другие типы, не совпадающие с теми, что хранятся в базеТы о машинных интах и флоатах, или о чем?
что-то поменялось?
In this state, it simply scans forward to the next "@" character, it doesn't care about tags or other HTML concepts, just "@". When it reaches an "@", it makes a decision: "Is this a switch to code, or is it an email address?"с твиттером конфликтует
Ты о машинных интах и флоатах, или о чем?насколько я помню, числовые типы совсем не такие как в базе
и коллекции странные (я бы ожидал, чтоб они были похожи на таблицы в базе, но на деле TABLE в PL/SQL - это совсем другая штука)
вообще pl/sql - это такой паскаль, но кривоватый, зато со встроенным sql
странно этот язык из 1970-х сейчас пиарить как лучшее средство для описания бизнес-логики
странно этот язык из 1970-х сейчас пиарить как лучшее средство для описания бизнес-логики
кстати, встроенный sql есть в x++ (Axapta)
возможно, даже получше pl/sql
возможно, даже получше pl/sql
Кстати, а что в PL/SQL с горячим обновлением кода? В типичном кровавом энтерпрайзе получается 3 слоя: веб клиент, сервер на Java и Oracle (RAC). Допустим мне очень нравятся хранимые процедуры, код близко к данным, которые он обрабатывает, низкий impedance на границе SQL-прикладной код, все то, что ты хвалишь. И вот я запилил половину логики системы в PL/SQL пакетах. Все хорошо, но как выкатывать обновления без простоев системы? Я правильно понимаю, что при попытке пропатчить и перекомпилировать пакеты, не выключая Java сервер, все сломается?
по хорошему надо поднимать вторую базу, настраивать проброс изменений с первой, вторую обновлять, а потом первую подменять второй.
баз тогда надо проде 2 получается. откатывать в случае факапа без простоя опять таки переключением
Кстати, а что в PL/SQL с горячим обновлением кода? В типичном кровавом энтерпрайзе получается 3 слоя: веб клиент, сервер на Java и Oracle (RAC). Допустим мне очень нравятся хранимые процедуры, код близко к данным, которые он обрабатывает, низкий impedance на границе SQL-прикладной код, все то, что ты хвалишь. И вот я запилил половину логики системы в PL/SQL пакетах. Все хорошо, но как выкатывать обновления без простоев системы? Я правильно понимаю, что при попытке пропатчить и перекомпилировать пакеты, не выключая Java сервер, все сломается?Теоретически (я сам не пробовал) надо использовать edition-based redefinition. У тебя может быть одновременно на сервере несколько редакций, в каждой редакции - своя версия пакетов. Для обновления ты
1)Создаешь новую редакцию.
2)Создаешь в ней все пакеты.
3)Делаешь эту редакцию дефолтной для новых сессий.
В случае connection pooling на джава-сервере одна сессия может теоретически жить сколь угодно долго, так что надо попросить пул соединений джава сервера, чтобы он закрывал возвращаемые в пул соединения и создавал новые, пока все соединения не перейдкт на новую редакцию.
вообще pl/sql - это такой паскаль, но кривоватый, зато со встроенным sqlНормальный язык, послабее C#, но посильнее java.
странно этот язык из 1970-х сейчас пиарить как лучшее средство для описания бизнес-логики
В паскале 70-х не было репла, модулей, классов, генераторов, хэштаблиц, именованных аргументов, интроспекции и еще кучи полезной фигни.
В случае connection pooling на джава-сервере одна сессия может теоретически жить сколь угодно долгоМожно делать ALTER SESSION на нужную ревизию в момент, когда берем соединение из пула. Это все понятно. Меня в свое время смутило, что я не смог толком найти отзывов об использовании EBR. Фича существует с 2009 что-ли года и такое чувство, что её никто особо не использует.
Можно делать ALTER SESSION на нужную ревизию в момент, когда берем соединение из пула. Это все понятно. Меня в свое время смутило, что я не смог толком найти отзывов об использовании EBR. Фича существует с 2009 что-ли года и такое чувство, что её никто особо не использует.Вообще, если надо какой-то быстрый квикфикс накатить, то вполне достаточно тупо обновить один пакет. Если надо какой-то большой апдейт выкатить, то возникают сомнения, что приложение-франкенштейн, составленное из кусков разных версий будет корректным.
Если у вас кровавый энтерпрайз, то наверное обновляете приложение не чаще пары раз в год, наверное можете себе на пару раз в год planned downtime запланировать. Тем более нужно ставить патчи на сам оракл, операционную систему и.т.д.
вот и получается, что raw sql подходит только для мелких прототипных проектов, когда еще все красиво.Вот тут по коду очень похоже, что используется ORM http://roem.ru/2012/03/29/auriga45259/
а с orm-ом удобнее в реальных больших работающих проектах, для которых норма, что большая часть кода является страшненькой, но работающей.
В итоге получили:
являясь веб-приложением платформа отказывала при одновременной работе пяти пользователей
Пять пользователей! Т.е. разработчики вообще не понимают, что происходит с базой.
Теперь с тебя пример, когда raw sql привел к провальному результату. Иначе пока считает, что "получается" наоборот (не работает даже прототип).
Деградация индустрии налицо.
У меня мама работает клерком в госучреждении, там заменили древнюю систему родом из 90-х (что-то типа FoxPro или Clipper) на новую, C# + SQL Server. Новая система поддерживает одновременно 2-х или 3-х пользователей, так что там теперь работают в несколько смен (к старой системе вообще никаких претензий не было). Новая система, кстати, крутится на серьезных серверах, старая работала на персоналке.
Теперь немолодые женщины мучаются за копеечную зарплату (а другой в провинции нет).
Я как-то создавал тут тред о том, что никакого дефицита программистов нет, наоборот, есть жуткий переизбыток, но меня заминусовали.
У меня мама работает клерком в госучреждении, там заменили древнюю систему родом из 90-х (что-то типа FoxPro или Clipper) на новую, C# + SQL Server. Новая система поддерживает одновременно 2-х или 3-х пользователей, так что там теперь работают в несколько смен (к старой системе вообще никаких претензий не было). Новая система, кстати, крутится на серьезных серверах, старая работала на персоналке.
Теперь немолодые женщины мучаются за копеечную зарплату (а другой в провинции нет).
Я как-то создавал тут тред о том, что никакого дефицита программистов нет, наоборот, есть жуткий переизбыток, но меня заминусовали.
Деградация индустрии налицо.Это не деградация индустрии, а деградация программистов.
У меня мама работает клерком в госучреждении, там заменили древнюю систему родом из 90-х (что-то типа FoxPro или Clipper) на новую, C# + SQL Server
Если бы проблема была в C# и SQL Server, то в мире не было бы ни одной системы на этой технологии, поддерживающей более 3 пользователей за раз. Но это не так, я сам соавтор нескольких таких систем.
Это не деградация индустрии, а деградация программистов.человеческие мозги вряд ли поменялись за последние 20-30 лет, а вот то, что заполняет эти мозги, поменялось. Например, появились ORM-ы.
Вообще, если надо какой-то быстрый квикфикс накатить, то вполне достаточно тупо обновить один пакет.Ну вот у меня есть одно OLTP приложение, там попытка тупо обновить пакет на ходу приводит к тому что на Java стороне получается большая пачка ORA-* и соответственно пачка кривых платежей в БД. У которых не записалось то, не создалось это. Получается, что надо останавливать все ради обновления PL/SQL.
Если у вас кровавый энтерпрайз, то наверное обновляете приложение не чаще пары раз в год, наверное можете себе на пару раз в год planned downtime запланировать.Оок, видимо мой энтерпрайз недостаточно кровав. Мы выкатываем изменения часто, когда это касается Java куска приложения. Рады бы часто обновлять PL/SQL кусок, но вот не осиливаем.
Ну вот у меня есть одно OLTP приложение, там попытка тупо обновить пакет на ходу приводит к тому что на Java стороне получается большая пачка ORA-* и соответственно пачка кривых платежей в БД.На всякий случай: и это не специфично для Java, с C++/OCI та ж фигня
Вообще, предложение писать половину бизнес-логики на нормальном языке, а половину на PL/SQL - редкостный бред.
Ну вот у меня есть одно OLTP приложение, там попытка тупо обновить пакет на ходу приводит к тому что на Java стороне получается большая пачка ORA-*Переменные пакета используете?
соответственно пачка кривых платежей в БД. У которых не записалось то, не создалось это.
Как это возможно? У вас обработка нетранзакционная?
Кстати, как насчет подхода - раздельные схемы для таблиц и пакетов, каждая версия пакетов - в новой схеме, обращение к таблицам через qualified name (schemaname.tablename) или через синонимы.
Постгрес, кстати, позволяет несколько текущих схем указывать, объекты ищутся по очереди в каждой схеме, при этом схемы не связаны с пользователями. Суперфича, которая заменяет оракловский edition-based redefinition
Постгрес, кстати, позволяет несколько текущих схем указывать, объекты ищутся по очереди в каждой схеме, при этом схемы не связаны с пользователями. Суперфича, которая заменяет оракловский edition-based redefinition
человеческие мозги вряд ли поменялись за последние 20-30 летещё как поменялись
засилье интерпретируемых языков с разнообразным нетривиальным сахаром, ведущим к ожирению мозгов, и "магией" (вроде gc) + быстрое железо, скрадывающее сложности до поры до времени — развивают в молодом падаване мистическое чувство отрешённости от ограничений железа, алгоритмов, программного окружения, специфики баз данных, требований индустрии — и от здравого смысла в итоге! Инфантильное желание спрятаться от возможных проблем, загромождая обычные задачи тучей ненужных "упрощающих" усложнений — бич современной эпохи. Вернитесь к ассемблеру и С, дети мои, вернитесь! Каждый программер должен хоть раз залезть в ассемблерный листинг, понюхать перфокарту, попрограммить на embedded-устройствах и микроконтроллерах, чтобы отринуть еретические лжеучения и вернуться в чистый С. Аминь
Счетами еще пощелкать должен.
Чтоб на своей шкуре ощутить, каково процессору ворочать числами.
Чтоб на своей шкуре ощутить, каково процессору ворочать числами.
ещё как поменялисьты вроде опять про наполнение мозгов написал
засилье интерпретируемых языков с разнообразным нетривиальным сахаром, ведущим к ожирению мозгов, и "магией" (вроде gc) + быстрое железо, скрадывающее сложности до поры до времени — развивают в молодом падаване мистическое чувство отрешённости от ограничений железа, алгоритмов, программного окружения, специфики баз данных, требований индустрии — и от здравого смысла в итоге! Инфантильное желание спрятаться от возможных проблем, загромождая обычные задачи тучей ненужных "упрощающих" усложнений — бич современной эпохи. Вернитесь к ассемблеру и С, дети мои, вернитесь! Каждый программер должен хоть раз залезть в ассемблерный листинг, понюхать перфокарту, попрограммить на embedded-устройствах и микроконтроллерах, чтобы отринуть еретические лжеучения и вернуться в чистый С. Аминь
опять про наполнение мозгов написаля не считаю, что наполнение мозгов сильно отличается от самих мозгов - до тех пор, пока их не получится опустошить и перезалить
увы, "чем поливали, то и выросло"
Оставить комментарий
bav46
Что-то куда не плюнь, везде питон, тындекс плавненько переводит все разработки на него, стартапы модно на нем ваять сейчас.В чем заключаются преимущества именно питона перед другими языками для сайтостроения?
Заранее всем спасибо.