Google Code Jam
55 очков. В сумме потратил где-то 2 часа. Почему-то подсчет площадей в третей завалился на большом тесте  .
.
.Каким методом пользовался?
С помощью сравнения с правильными ответами нашел у себя ошибку - если окружность проходит вблизи угла, то я мог пропустить эту точку пересечения (я боялся посчитать ее два раза, а оказалось, что в этом нет ничего плохого). В результате на одном тесте ответы разошлись на 2e-6 .
.Я 50 тоже набрал. Третью не успел решить
Начал за три часа до конца, решил всё, невзирая на то, что их система упорно пыталась свести меня с ума не желая принимать "case #..." с маленькой буквы, блджад.
Первую сам не очень понял, как решил. Ну, массивчег докуда мы можем дойти со сколькими свитчами, в цикле для каждого элемента предполагаем, что мы там свитчнулись и идём дальше пихая в сет кьюери, пока он не наполнится, записывая в массивчег результаты. Наверняка можно это всё соптимизить, но было влом думать, там какие-то мерзкие крайние случаи, а и так сработало.
Вторая пишется мгновенно - фигачим в два массива туплы (время, "a" for arrival or "d" for departure сортируем (при этом арривалы автоматически оказываются перед депарчурами при совпадающем времени, проходим, считаем минимум.
Третья забавная. Не торопясь написал формулок, всю программу, тестирую, фигня выходит. Ну, понятно, что считать нужно площадь дырок в одном секторе, вычитая из g 2f. Как бы. Причём во избежание ошибок округления нужно считать пересекающиеся с краем дырки отдельно, а целые - потом отдельно. Так вот, за пять минут до конца понял, что моя формула площади куска окружности выше прямого угла, сонаправленного координатам, неправильна. Исправил, запустил, результаты совпадают. За три минуты до конца скачал-запустил-отправил маленький тест, возрадовался, запустил на большом и начал стрематься: вместо интеллектуального нахождения края я тупо перебирал пустые дырки по очереди, в результате оно подвисало на десять секунд на некоторых тестах. Но успело вычислиться.
Первую сам не очень понял, как решил. Ну, массивчег докуда мы можем дойти со сколькими свитчами, в цикле для каждого элемента предполагаем, что мы там свитчнулись и идём дальше пихая в сет кьюери, пока он не наполнится, записывая в массивчег результаты. Наверняка можно это всё соптимизить, но было влом думать, там какие-то мерзкие крайние случаи, а и так сработало.
Вторая пишется мгновенно - фигачим в два массива туплы (время, "a" for arrival or "d" for departure сортируем (при этом арривалы автоматически оказываются перед депарчурами при совпадающем времени, проходим, считаем минимум.
Третья забавная. Не торопясь написал формулок, всю программу, тестирую, фигня выходит. Ну, понятно, что считать нужно площадь дырок в одном секторе, вычитая из g 2f. Как бы. Причём во избежание ошибок округления нужно считать пересекающиеся с краем дырки отдельно, а целые - потом отдельно. Так вот, за пять минут до конца понял, что моя формула площади куска окружности выше прямого угла, сонаправленного координатам, неправильна. Исправил, запустил, результаты совпадают. За три минуты до конца скачал-запустил-отправил маленький тест, возрадовался, запустил на большом и начал стрематься: вместо интеллектуального нахождения края я тупо перебирал пустые дырки по очереди, в результате оно подвисало на десять секунд на некоторых тестах. Но успело вычислиться.
приведите тексты задач, плиз
Saving the Universe
Problem
The urban legend goes that if you go to the Google homepage and search for "Google", the universe will implode. We have a secret to share... It is true! Please don't try it, or tell anyone. All right, maybe not. We are just kidding.
The same is not true for a universe far far away. In that universe, if you search on any search engine for that search engine's name, the universe does implode!
To combat this, people came up with an interesting solution. All queries are pooled together. They are passed to a central system that decides which query goes to which search engine. The central system sends a series of queries to one search engine, and can switch to another at any time. Queries must be processed in the order they're received. The central system must never send a query to a search engine whose name matches the query. In order to reduce costs, the number of switches should be minimized.
Your task is to tell us how many times the central system will have to switch between search engines, assuming that we program it optimally.
Input
The first line of the input file contains the number of cases, N. N test cases follow.
Each case starts with the number S — the number of search engines. The next S lines each contain the name of a search engine. Each search engine name is no more than one hundred characters long and contains only uppercase letters, lowercase letters, spaces, and numbers. There will not be two search engines with the same name.
The following line contains a number Q — the number of incoming queries. The next Q lines will each contain a query. Each query will be the name of a search engine in the case.
Output
For each input case, you should output:
Case #X: Ywhere X is the number of the test case and Y is the number of search engine switches. Do not count the initial choice of a search engine as a switch.
Limits
0 < N ≤ 20
Small dataset
2 ≤ S ≤ 10
0 ≤ Q ≤ 100
Large dataset
2 ≤ S ≤ 100
0 ≤ Q ≤ 1000
Sample
Input
2
5
Yeehaw
NSM
Dont Ask
B9
Googol
10
Yeehaw
Yeehaw
Googol
B9
Googol
NSM
B9
NSM
Dont Ask
Googol
5
Yeehaw
NSM
Dont Ask
B9
Googol
7
Googol
Dont Ask
NSM
NSM
Yeehaw
Yeehaw
Googol
Output
Case 1
Case 0
In the first case, one possible solution is to start by using Dont Ask, and switch to NSM after query number 8.
For the second case, you can use B9, and not need to make any switches.
Problem
The urban legend goes that if you go to the Google homepage and search for "Google", the universe will implode. We have a secret to share... It is true! Please don't try it, or tell anyone. All right, maybe not. We are just kidding.
The same is not true for a universe far far away. In that universe, if you search on any search engine for that search engine's name, the universe does implode!
To combat this, people came up with an interesting solution. All queries are pooled together. They are passed to a central system that decides which query goes to which search engine. The central system sends a series of queries to one search engine, and can switch to another at any time. Queries must be processed in the order they're received. The central system must never send a query to a search engine whose name matches the query. In order to reduce costs, the number of switches should be minimized.
Your task is to tell us how many times the central system will have to switch between search engines, assuming that we program it optimally.
Input
The first line of the input file contains the number of cases, N. N test cases follow.
Each case starts with the number S — the number of search engines. The next S lines each contain the name of a search engine. Each search engine name is no more than one hundred characters long and contains only uppercase letters, lowercase letters, spaces, and numbers. There will not be two search engines with the same name.
The following line contains a number Q — the number of incoming queries. The next Q lines will each contain a query. Each query will be the name of a search engine in the case.
Output
For each input case, you should output:
Case #X: Ywhere X is the number of the test case and Y is the number of search engine switches. Do not count the initial choice of a search engine as a switch.
Limits
0 < N ≤ 20
Small dataset
2 ≤ S ≤ 10
0 ≤ Q ≤ 100
Large dataset
2 ≤ S ≤ 100
0 ≤ Q ≤ 1000
Sample
Input
2
5
Yeehaw
NSM
Dont Ask
B9
Googol
10
Yeehaw
Yeehaw
Googol
B9
Googol
NSM
B9
NSM
Dont Ask
Googol
5
Yeehaw
NSM
Dont Ask
B9
Googol
7
Googol
Dont Ask
NSM
NSM
Yeehaw
Yeehaw
Googol
Output
Case 1
Case 0
In the first case, one possible solution is to start by using Dont Ask, and switch to NSM after query number 8.
For the second case, you can use B9, and not need to make any switches.
Train Timetable
Problem
A train line has two stations on it, A and B. Trains can take trips from A to B or from B to A multiple times during a day. When a train arrives at B from A (or arrives at A from B it needs a certain amount of time before it is ready to take the return journey - this is the turnaround time. For example, if a train arrives at 12:00 and the turnaround time is 0 minutes, it can leave immediately, at 12:00.
A train timetable specifies departure and arrival time of all trips between A and B. The train company needs to know how many trains have to start the day at A and B in order to make the timetable work: whenever a train is supposed to leave A or B, there must actually be one there ready to go. There are passing sections on the track, so trains don't necessarily arrive in the same order that they leave. Trains may not travel on trips that do not appear on the schedule.
Input
The first line of input gives the number of cases, N. N test cases follow.
Each case contains a number of lines. The first line is the turnaround time, T, in minutes. The next line has two numbers on it, NA and NB. NA is the number of trips from A to B, and NB is the number of trips from B to A. Then there are NA lines giving the details of the trips from A to B.
Each line contains two fields, giving the HH:MM departure and arrival time for that trip. The departure time for each trip will be earlier than the arrival time. All arrivals and departures occur on the same day. The trips may appear in any order - they are not necessarily sorted by time. The hour and minute values are both two digits, zero-padded, and are on a 24-hour clock (00:00 through 23:59).
After these NA lines, there are NB lines giving the departure and arrival times for the trips from B to A.
Output
For each test case, output one line containing "Case #x: " followed by the number of trains that must start at A and the number of trains that must start at B.
Limits
1 ≤ N ≤ 100
Small dataset
0 ≤ NA, NB ≤ 20
0 ≤ T ≤ 5
Large dataset
0 ≤ NA, NB ≤ 100
0 ≤ T ≤ 60
Sample
Input
2
5
3 2
09:00 12:00
10:00 13:00
11:00 12:30
12:02 15:00
09:00 10:30
2
2 0
09:00 09:01
12:00 12:02
Output
Case 2 2
Case 2 0
Problem
A train line has two stations on it, A and B. Trains can take trips from A to B or from B to A multiple times during a day. When a train arrives at B from A (or arrives at A from B it needs a certain amount of time before it is ready to take the return journey - this is the turnaround time. For example, if a train arrives at 12:00 and the turnaround time is 0 minutes, it can leave immediately, at 12:00.
A train timetable specifies departure and arrival time of all trips between A and B. The train company needs to know how many trains have to start the day at A and B in order to make the timetable work: whenever a train is supposed to leave A or B, there must actually be one there ready to go. There are passing sections on the track, so trains don't necessarily arrive in the same order that they leave. Trains may not travel on trips that do not appear on the schedule.
Input
The first line of input gives the number of cases, N. N test cases follow.
Each case contains a number of lines. The first line is the turnaround time, T, in minutes. The next line has two numbers on it, NA and NB. NA is the number of trips from A to B, and NB is the number of trips from B to A. Then there are NA lines giving the details of the trips from A to B.
Each line contains two fields, giving the HH:MM departure and arrival time for that trip. The departure time for each trip will be earlier than the arrival time. All arrivals and departures occur on the same day. The trips may appear in any order - they are not necessarily sorted by time. The hour and minute values are both two digits, zero-padded, and are on a 24-hour clock (00:00 through 23:59).
After these NA lines, there are NB lines giving the departure and arrival times for the trips from B to A.
Output
For each test case, output one line containing "Case #x: " followed by the number of trains that must start at A and the number of trains that must start at B.
Limits
1 ≤ N ≤ 100
Small dataset
0 ≤ NA, NB ≤ 20
0 ≤ T ≤ 5
Large dataset
0 ≤ NA, NB ≤ 100
0 ≤ T ≤ 60
Sample
Input
2
5
3 2
09:00 12:00
10:00 13:00
11:00 12:30
12:02 15:00
09:00 10:30
2
2 0
09:00 09:01
12:00 12:02
Output
Case 2 2
Case 2 0
The urban legend goes that if you go to the Google homepage and search for "Google", the universe will implode. We have a secret to share... It is true! Please don't try it, or tell anyone.Сцуко, я попробовал, не вышло. Наебали!
Fly Swatter
Problem
What are your chances of hitting a fly with a tennis racquet?
To start with, ignore the racquet's handle. Assume the racquet is a perfect ring, of outer radius R and thickness t (so the inner radius of the ring is R−t).
The ring is covered with horizontal and vertical strings. Each string is a cylinder of radius r. Each string is a chord of the ring (a straight line connecting two points of the circle). There is a gap of length g between neighbouring strings. The strings are symmetric with respect to the center of the racquet i.e. there is a pair of strings whose centers meet at the center of the ring.
The fly is a sphere of radius f. Assume that the racquet is moving in a straight line perpendicular to the plane of the ring. Assume also that the fly's center is inside the outer radius of the racquet and is equally likely to be anywhere within that radius. Any overlap between the fly and the racquet (the ring or a string) counts as a hit.
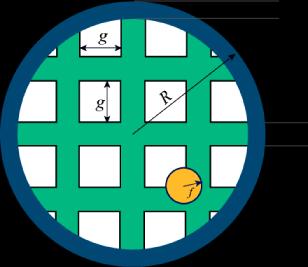
Input
One line containing an integer N, the number of test cases in the input file.
The next N lines will each contain the numbers f, R, t, r and g separated by exactly one space. Also the numbers will have at most 6 digits after the decimal point.
Output
N lines, each of the form "Case #k: P", where k is the number of the test case and P is the probability of hitting the fly with a piece of the racquet.
Answers with a relative or absolute error of at most 10-6 will be considered correct.
Limits
f, R, t, r and g will be positive and smaller or equal to 10000.
t < R
f < R
r < R
Small dataset
1 ≤ N ≤ 30
The total number of strings will be at most 60 (so at most 30 in each direction).
Large dataset
1 ≤ N ≤ 100
The total number of strings will be at most 2000 (so at most 1000 in each direction).
Sample
Input
5
0.25 1.0 0.1 0.01 0.5
0.25 1.0 0.1 0.01 0.9
0.00001 10000 0.00001 0.00001 1000
0.4 10000 0.00001 0.00001 700
1 100 1 1 10
Output
Case 1.000000
Case 0.910015
Case 0.000000
Case 0.002371
Case 0.573972
Problem
What are your chances of hitting a fly with a tennis racquet?
To start with, ignore the racquet's handle. Assume the racquet is a perfect ring, of outer radius R and thickness t (so the inner radius of the ring is R−t).
The ring is covered with horizontal and vertical strings. Each string is a cylinder of radius r. Each string is a chord of the ring (a straight line connecting two points of the circle). There is a gap of length g between neighbouring strings. The strings are symmetric with respect to the center of the racquet i.e. there is a pair of strings whose centers meet at the center of the ring.
The fly is a sphere of radius f. Assume that the racquet is moving in a straight line perpendicular to the plane of the ring. Assume also that the fly's center is inside the outer radius of the racquet and is equally likely to be anywhere within that radius. Any overlap between the fly and the racquet (the ring or a string) counts as a hit.
Input
One line containing an integer N, the number of test cases in the input file.
The next N lines will each contain the numbers f, R, t, r and g separated by exactly one space. Also the numbers will have at most 6 digits after the decimal point.
Output
N lines, each of the form "Case #k: P", where k is the number of the test case and P is the probability of hitting the fly with a piece of the racquet.
Answers with a relative or absolute error of at most 10-6 will be considered correct.
Limits
f, R, t, r and g will be positive and smaller or equal to 10000.
t < R
f < R
r < R
Small dataset
1 ≤ N ≤ 30
The total number of strings will be at most 60 (so at most 30 in each direction).
Large dataset
1 ≤ N ≤ 100
The total number of strings will be at most 2000 (so at most 1000 in each direction).
Sample
Input
5
0.25 1.0 0.1 0.01 0.5
0.25 1.0 0.1 0.01 0.9
0.00001 10000 0.00001 0.00001 1000
0.4 10000 0.00001 0.00001 700
1 100 1 1 10
Output
Case 1.000000
Case 0.910015
Case 0.000000
Case 0.002371
Case 0.573972
навскидку слабовато. на всеукраинской по информатике посложнее...
Сложного особо нет ничего, правда на раундах будет времени 1-3 часа на задачки, для меня это фигово - не умею на скорость думать и прогать, люблю неспеша
Решил всё кроме большого на второй задаче (так и не понял где ошибка, не исключено что налажал с отправкой).
На реальном языке бы это писать, за 10 минут решить можно было бы. Типа как 1-ю задачу:
p:{[cn;n;s;q] $[count q;p[cn;n+1;scount each s except\q)?0)_q];1 "Case #",cn,": "string n"\n"];};
nc:"I"$first u:read0`:./test.txt;u:1_u;
{p[string 1+x;-1] .{s:`$(ns:"I"$first u)#1_u;u::(1+ns)_u;s}each 0 1}each til nc;
exit 0
Первую сам не очень понял, как решил. Ну, массивчег докуда мы можем дойти со сколькими свитчами, в цикле для каждого элемента предполагаем, что мы там свитчнулись и идём дальше пихая в сет кьюери, пока он не наполнится, записывая в массивчег результаты. Наверняка можно это всё соптимизить, но было влом думатьзаметно

на самом деле, всё намного проще

def count_switches(queries, eng_num):
n = 0
s = set
for q in queries:
s.add(q)
if len(s) == eng_num:
n += 1
s = setq
return n
первые две задачи решаются за 10 минут, последнюю решать не стал: влома было писать формулы =)
ну это просто квалификация, думаю, на основных турах нормальные задачки будут
лол, и вправду =)
фильтр ненужных запросов ты благополучно пропустил 
10 минут на написание или на решение?
Учавствовал? Какой ник?
фильтр ненужных запросов ты благополучно пропустилчо за фильтр такой?

Round 1b. Набрал сорок очков (большой тест решил только для первой задачи).
Чтобы решить первую надо для каждого хвоста списка координат найти 9 чисел - количеств пар деревьев из этого хвоста, суммы координат которыхпо модулю 3 такие-то и такие-то. А для этого надо для каждого хвостасписка координат найти 9 чисел - количество деревьев из этого хвоста, координаты которых по модулю 3 такие-то и такие-то.
Вторая задача. Скорее всего её можно решить влоб с использованием disjoint set union из Кормена (кстати кто не знает что это такое -советую узнать: идея очень красивая) и быстрого ЯП. Но на питоне у меня не получилось. Как схалявить с помощью каких-нибудь соображений из теории чисел не допёр.
Третья задача. Настолько боянная, что было влом думать. Решение есть вроде в Кнуте, только в другом антураже (жеребьёвка моряков и возможно при несколько другой формулировке.
Чтобы решить первую надо для каждого хвоста списка координат найти 9 чисел - количеств пар деревьев из этого хвоста, суммы координат которыхпо модулю 3 такие-то и такие-то. А для этого надо для каждого хвостасписка координат найти 9 чисел - количество деревьев из этого хвоста, координаты которых по модулю 3 такие-то и такие-то.
Вторая задача. Скорее всего её можно решить влоб с использованием disjoint set union из Кормена (кстати кто не знает что это такое -советую узнать: идея очень красивая) и быстрого ЯП. Но на питоне у меня не получилось. Как схалявить с помощью каких-нибудь соображений из теории чисел не допёр.
Третья задача. Настолько боянная, что было влом думать. Решение есть вроде в Кнуте, только в другом антураже (жеребьёвка моряков и возможно при несколько другой формулировке.
Чтобы решить первую, надо...
Или, что тоже самое, пройти по списку и раскидать единички по массиву из 9 элементов, после чего не мудрствуя лукаво перебрать все 9**3 / 6 комбинаций, проверить совместимость каждой и аккуратно перемножить циферки (не забыв обработать отдельно случаи, когда два или все три числа взяты из одной коробки).
Или, что тоже самое, пройти по списку и раскидать единички по массиву из 9 элементов, после чего не мудрствуя лукаво перебрать все 9**3 / 6 комбинаций, проверить совместимость каждой и аккуратно перемножить циферки (не забыв обработать отдельно случаи, когда два или все три числа взяты из одной коробки).
Решил уже после number sets на питоне с пирексом. Большой тест занимает 75 секунд. На чистом питоне скорее всего не успел бы (дискриминация!.. или всё же есть какой-то нетривиальный алгоритм) .
А представь какая дискриминация тех, кто пишет на brain fuck? У них неделю самый оптимальный алгоритм считаться будет. Так что мораль - не используйте слишком (10 раз еще нормально, а 100 - нет) тормозные языки программирования; для скриптовых языков jit компилер обязателен.
Ну вот, я вылетел, например.
Потому что решив первую за полчаса, зачем-то решил написать решение старворз методом последовательных приближений. Ну и оно не заработало, естественно - либо говорило неточный результат, либо глубоко задумывалось даже на маленьких тестах. В результате за двадцать минут до конца начал лихорадочно писать тупой перебор для последней, ещё более лихорадочно дебажа свою глючащую функцию nextPermutation (ёбаный стыд...) и не успел, оказавшись 1100-ым где-то.
Что самое обидное, уже после вдруг понял, что вообще-то если у кучи октаэдров есть непустые попарные пересечения, то у них есть и непустое пересечение. Не знаю, как обосновать, но в результате
плюс поиск максимума по несчастному полумиллиону сочетаний в худшем случае проходил большой тест за секунду (под Psyco). Очень обидно. Ведь получается, что это самая маленькая (по объёму кода) задача. Эх.
(кстати. Последняя задача из предыдущего забега, про карты, которая баянная, тоже проходила большой тест если скачать blist и тупо симулировать весь процесс. Вот тоже прикольно - фактически добавлялась одна строчка, "cards = blist(cards)")
Потому что решив первую за полчаса, зачем-то решил написать решение старворз методом последовательных приближений. Ну и оно не заработало, естественно - либо говорило неточный результат, либо глубоко задумывалось даже на маленьких тестах. В результате за двадцать минут до конца начал лихорадочно писать тупой перебор для последней, ещё более лихорадочно дебажа свою глючащую функцию nextPermutation (ёбаный стыд...) и не успел, оказавшись 1100-ым где-то.
Что самое обидное, уже после вдруг понял, что вообще-то если у кучи октаэдров есть непустые попарные пересечения, то у них есть и непустое пересечение. Не знаю, как обосновать, но в результате
def powerToIntersectx1, y1, z1, p1 (x2, y2, z2, p2:
return (abs(x1 - x2) + abs(y1 - y2) + abs(z1 - z2 / (p1 + p2)
плюс поиск максимума по несчастному полумиллиону сочетаний в худшем случае проходил большой тест за секунду (под Psyco). Очень обидно. Ведь получается, что это самая маленькая (по объёму кода) задача. Эх.
(кстати. Последняя задача из предыдущего забега, про карты, которая баянная, тоже проходила большой тест если скачать blist и тупо симулировать весь процесс. Вот тоже прикольно - фактически добавлялась одна строчка, "cards = blist(cards)")
Тоже вылетел. Потому что потратил первый час с копейками на поиски решения последних двух задач.
В результате сдал первую ближе к концу и не успел написать ни одну из оставшихся. Где-то м/у 1300 и 1400
Теперь вот глубоко задумался, может стоит попрактиковаться в олимпиадном программировании? А то после школьного всероса 2005-ого я ходил лишь на последний ACM. А до всероса в качестве подготовки решил только 4 задачи на динамику.
В результате сдал первую ближе к концу и не успел написать ни одну из оставшихся. Где-то м/у 1300 и 1400
Теперь вот глубоко задумался, может стоит попрактиковаться в олимпиадном программировании? А то после школьного всероса 2005-ого я ходил лишь на последний ACM. А до всероса в качестве подготовки решил только 4 задачи на динамику.
1073 
А чо пишут:
?
А чо пишут:
Round 2 - The top 1000 contestants advance. Results are not final: Problem C will be rejudged
?
Факт насчёт попарных пересечений становится очевидным, если рассматривать октаэдры в проеции на четыре оси: (1,1,1 (-1,-1,1 (1,-1,-1) и (-1,1,-1). И вообще это очень удобно:
А дальше двоичный поиск. Впрочем, тривиальность этой задачи не помешала мне налажать с начальным диапазоном для поиска, и большой тест я не прошёл.
В итоге где-то на трёхсотом месте, и, чувствую, такими темпами вылечу на третьем туре.
---
Занимательно смотреть исходники профессиональных олимпиадников с первых строчек. Они какие-то минималистичные, что ли.
def enough(power):
global ships
for q1 in [-1,1]:
for q2 in [-1,1]:
S = 0
for q3 in [-1,1]:
sx = q1*q3
sy = q2*q3
sz = q3
S += min(x*sx+y*sy+z*sz+power*p for x,y,z,p in ships)
if S<0:
return False
return True
А дальше двоичный поиск. Впрочем, тривиальность этой задачи не помешала мне налажать с начальным диапазоном для поиска, и большой тест я не прошёл.
В итоге где-то на трёхсотом месте, и, чувствую, такими темпами вылечу на третьем туре.
---
Занимательно смотреть исходники профессиональных олимпиадников с первых строчек. Они какие-то минималистичные, что ли.
(забыл залогиниться)
Попарное пересечение октаэдров может не пройти на большом тесте - именно поэтому C и реджаджили (авторы написали неправильное решение). Там надо делать чуть хитрее - см. мое решение.
Не понял - не пройдёт в смысле по времени?
Ну, там же в худшем случае десять раз по полмиллиона выполняется четыре сложения и деление. Это даже на чистом питоне (без Psyco) даже на очень старой машине успеет отработать за восемь минут.
Ну, там же в худшем случае десять раз по полмиллиона выполняется четыре сложения и деление. Это даже на чистом питоне (без Psyco) даже на очень старой машине успеет отработать за восемь минут.
если бы не проходило по времени, то реджаджить не надо было бы. =)
видимо, не проходит, по смыслу.
видимо, не проходит, по смыслу.
Простейший тест -
Все попарные пересечения существуют для расстояния 1, а на самом деле ответ 1.5.
4
1 1 1 1
1 0 0 1
0 1 0 1
0 0 1 1
Все попарные пересечения существуют для расстояния 1, а на самом деле ответ 1.5.
Ох, блин, и вправду.
Правильно ли я понял логику за твоим решением: вообще мы ищем пересечение кучи слоёв (или полупространств). Вначале для каждой оси ищем пересечение всех ортогональных с ней слоёв, потом дополнительно (и это важно!) проверяем, что получающаяся фигура не вырождена, ведь даже если слои по данной оси вроде бы непусто пересекаются, полупространства в других осях могут их обрезать. Так?
Правильно ли я понял логику за твоим решением: вообще мы ищем пересечение кучи слоёв (или полупространств). Вначале для каждой оси ищем пересечение всех ортогональных с ней слоёв, потом дополнительно (и это важно!) проверяем, что получающаяся фигура не вырождена, ведь даже если слои по данной оси вроде бы непусто пересекаются, полупространства в других осях могут их обрезать. Так?
Ага. Чтобы понять почему условий в моей программе достаточно нужно перейти к координатам
![[math]$x'=-x+y+z, y'=x-y+z, z'=x+y-z$[/math]](mathimg.php?math=%24x%27%3D-x%2By%2Bz%2C%20y%27%3Dx-y%2Bz%2C%20z%27%3Dx%2By-z%24) .
.
А кто-нибудь знает реализацию чего-нибудь вроде blist для плюсов? Точнее, нужен контейнер, который умеет быстро вставлять/удалять/перемещать слайсы и находить элемент по индексу.
Такая штука в прошлогоднем icfpc сильно помогла бы.
Такая штука в прошлогоднем icfpc сильно помогла бы.
Для прошлогоднего ICFPC есть ropes. Можно ли ту реализацию от SGI (кажется) параметризовать чем-нибудь кроме чаров и будет ли это эффективно - не знаю.
Подойдёт внятное описание структуры данных. Где его взять?
В вике нет. Гугл на blist выдаёт что-то невнятное.
В вике нет. Гугл на blist выдаёт что-то невнятное.
http://www.google.com/search?rls=en&q=python+blist
Он на С написан, кстати.
Он на С написан, кстати.
Попробовал написать на нем mousetrap. В 10 раз на обоих тестах проигрывает самописному дереву, которое хранит количество потомков в каждой вершине. Оно и понятно, дерево читерит:
- вместо удаления элементов забивает их нулями, таким образом обходится без перебалансировки;
- если в rope используется B-дерево, то ему при удалении придется двигать элементы внутри узла, а бинарному - нет.
Но асимптотика правильная.
- вместо удаления элементов забивает их нулями, таким образом обходится без перебалансировки;
- если в rope используется B-дерево, то ему при удалении придется двигать элементы внутри узла, а бинарному - нет.
Но асимптотика правильная.
Оставить комментарий
agaaaa
Я набрал 50 очков, но начал только за 5 часов до конца раунда.В результате последняя задача на момент окончания не была решена. Метод Монте-Карло не подошёл, т.к. вышел слишком медленным (и, самое странное, сильно расходился с предложенным ответом на втором тесте из условия обычный подсчёт площадей не успел реализовать.
Кто-нить ещё учавствовал? Какие успехи?